Test-split Server on CIRR Dataset
October 17, 2025 · View on GitHub
We host an evaluation server (backup) on a dedicated machine. It accepts a .json file containing the model's predictions and returns results.
The .json files must be generated following our templates, otherwise, it cannot be properly processed.
Warning
We do not save your information, nor your uploaded files to the server.
Nevertheless, please DO NOT upload any file containing sensitive information. We are not responsible for any related incidents.
Updates
- May 2025 The main test server is back online.
- May 2025 We encountered a network outage on 16 May 2025,
the main test server is now offline. For now please refer to the backup test server. - May 2025 We have replaced reCAPTCHA with hCaptcha, users that previously relied on VPN to submit should experience less errors.
Generating the Prediction Files for Upload
The Easiest Way
If you are developing based on the CIRPLANT codebase, please refer to this section of the README file. The model supports exporting two .json files that can be readily uploaded for the evaluation of Recall and Recall_Subset.
The Manual Way
Please follow the following template to generate the .json file.
The content should be a dictionary, click to see an example key-value pair.
"12063": ["test1-233-3-img1",
"test1-969-1-img0",
"test1-455-2-img1",
"test1-835-3-img0",
"test1-238-1-img1",
...
# list contains:
# top-50 candidates for recall, or
# top-3 candidates for recall_subset
],
- Here,
12063is the uniquepair_idfor a query, you shall find it in our dataset annotation entries (check out either one of thecaptions/cap.VER.SPLIT.jsonfiles). - The list of candidates is your model's prediction associated with that particular query.
- Important! Two special entries shall be added to the file, indicating (1) the version of the CIRR dataset used, and (2) the metric for evaluation.
- dataset version: e.g.,
"version": "rc2" - metric: either
"metric": "recall"or"metric": "recall_subset"
- dataset version: e.g.,
- To limit the file size (Maximum 5MB), please select, for each entry, the top-50 (resp. 3) predictions to evaluate on Recall (resp. Recall_Subset).
Example Submission Files
See example .json files on Recall and Recall_Subset.
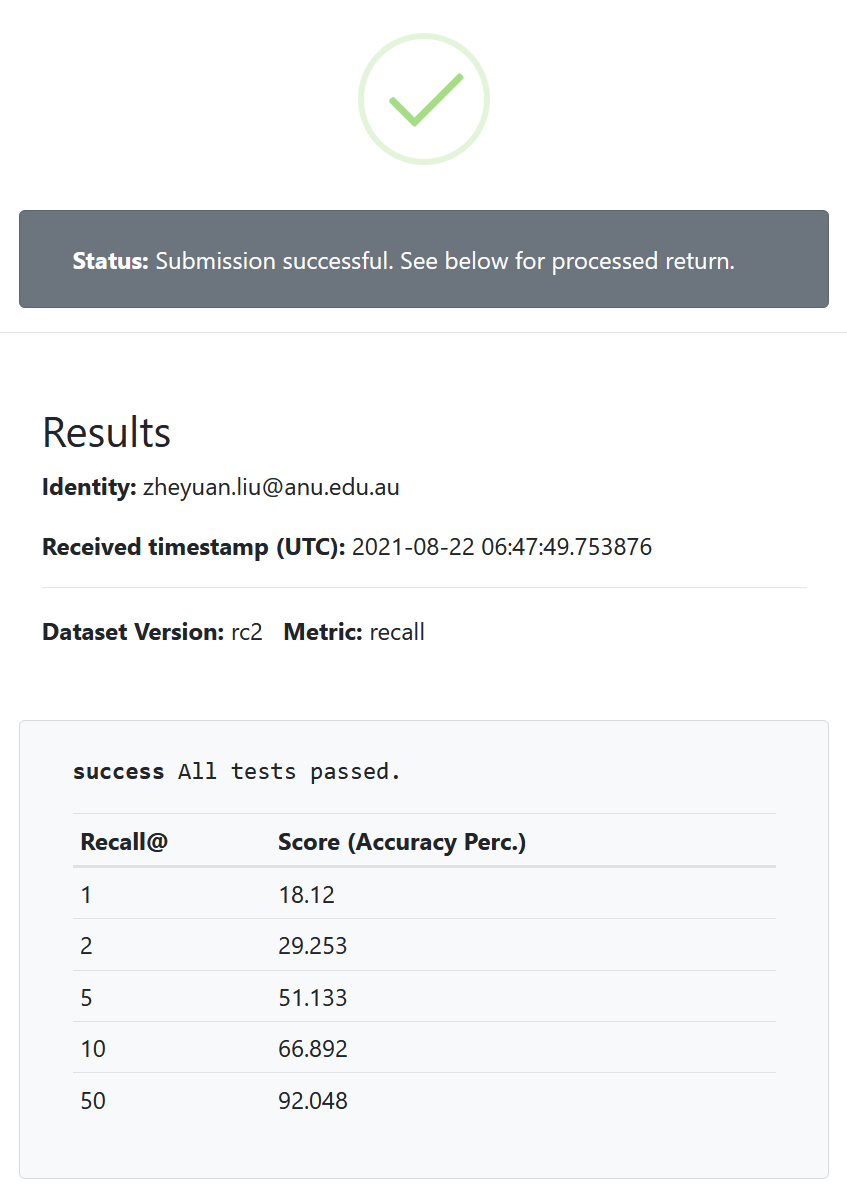
These files were generated on our trained baseline model. You can try to upload them to the server, they shall pass all our sanity checks.
You shall see the result (here showing Recall@K, Recall_subset@K will be similar) as below:
Contact
If you have any questions regarding our dataset, model, or publication, please create an issue in the project repository, or email zheyuan.david.liu@outlook.com.