TOSS: High-quality Text-guided Novel View Synthesis from a Single Image (ICLR2024)
May 5, 2024 · View on GitHub
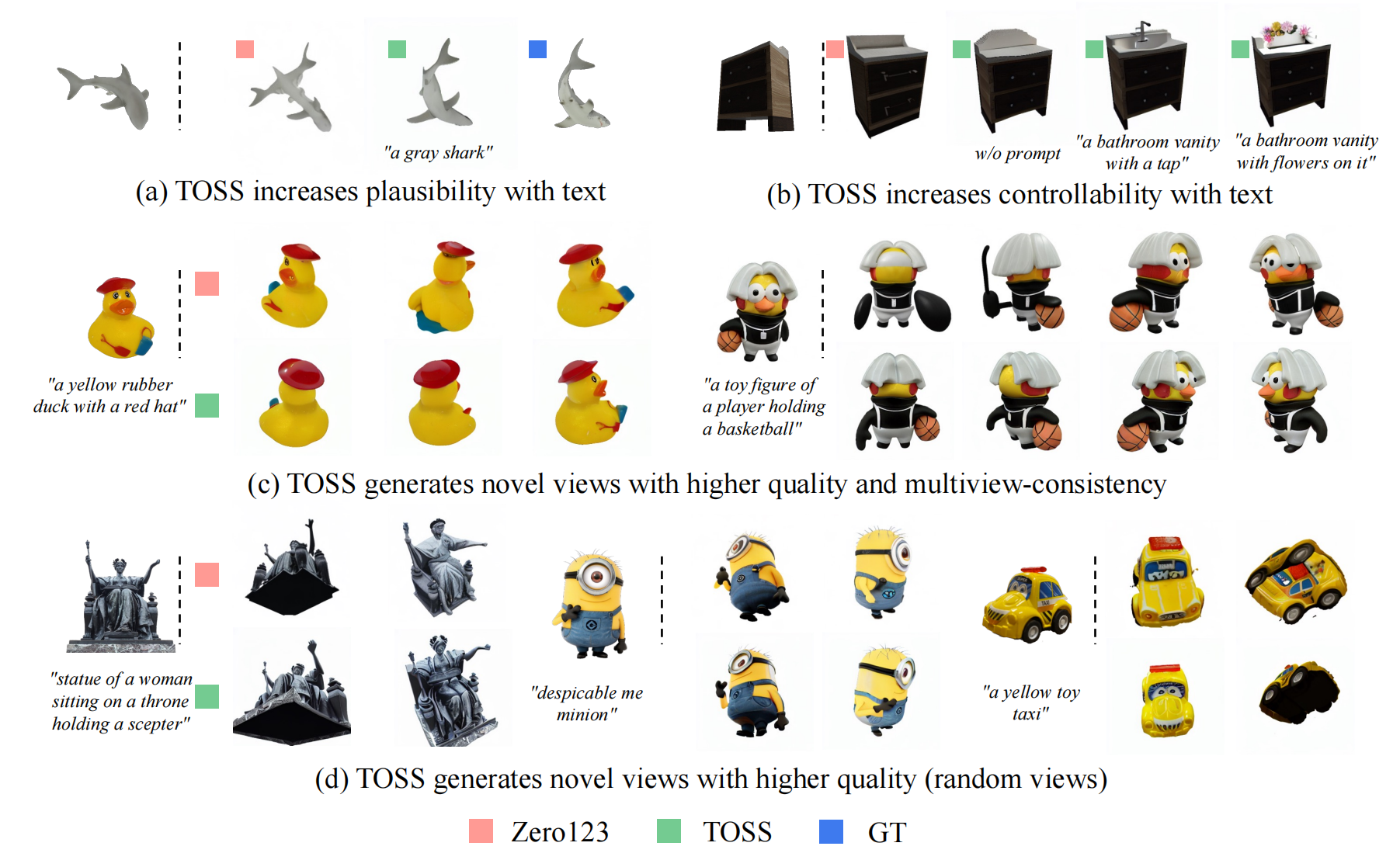
Official implementation for TOSS: High-quality Text-guided Novel View Synthesis from a Single Image.
TOSS introduces text as high-level sementic information to constraint the NVS solution space for more controllable and more plausible results.
Project Page | ArXiv | Weights
https://github.com/IDEA-Research/TOSS/assets/54578597/cd64c6c5-fef8-43c2-a223-7930ad6a71b7
Install
Create environment
conda create -n toss python=3.9
conda activate toss
Install packages
pip install torch==2.0.0 torchvision==0.15.1 torchaudio==2.0.1 --index-url https://download.pytorch.org/whl/cu118
pip install -r requirements.txt
git clone https://github.com/openai/CLIP.git
pip install -e CLIP/
Weights
Download pretrain weights from this link to sub-directory ./ckpt
Inference
We suggest gradio for a visualized inference and test this demo on a single RTX3090.
python app.py

Todo List
- Release inference code.
- Release pretrained models.
- Upload 3D generation code.
- Upload training code.
Acknowledgement
Citation
@article{shi2023toss,
title={Toss: High-quality text-guided novel view synthesis from a single image},
author={Shi, Yukai and Wang, Jianan and Cao, He and Tang, Boshi and Qi, Xianbiao and Yang, Tianyu and Huang, Yukun and Liu, Shilong and Zhang, Lei and Shum, Heung-Yeung},
journal={arXiv preprint arXiv:2310.10644},
year={2023}
}