Profile B: Voxtral HF + translation
June 12, 2026 · View on GitHub

WLK: Ultra-low-latency, self-hosted speech-to-text pipeline
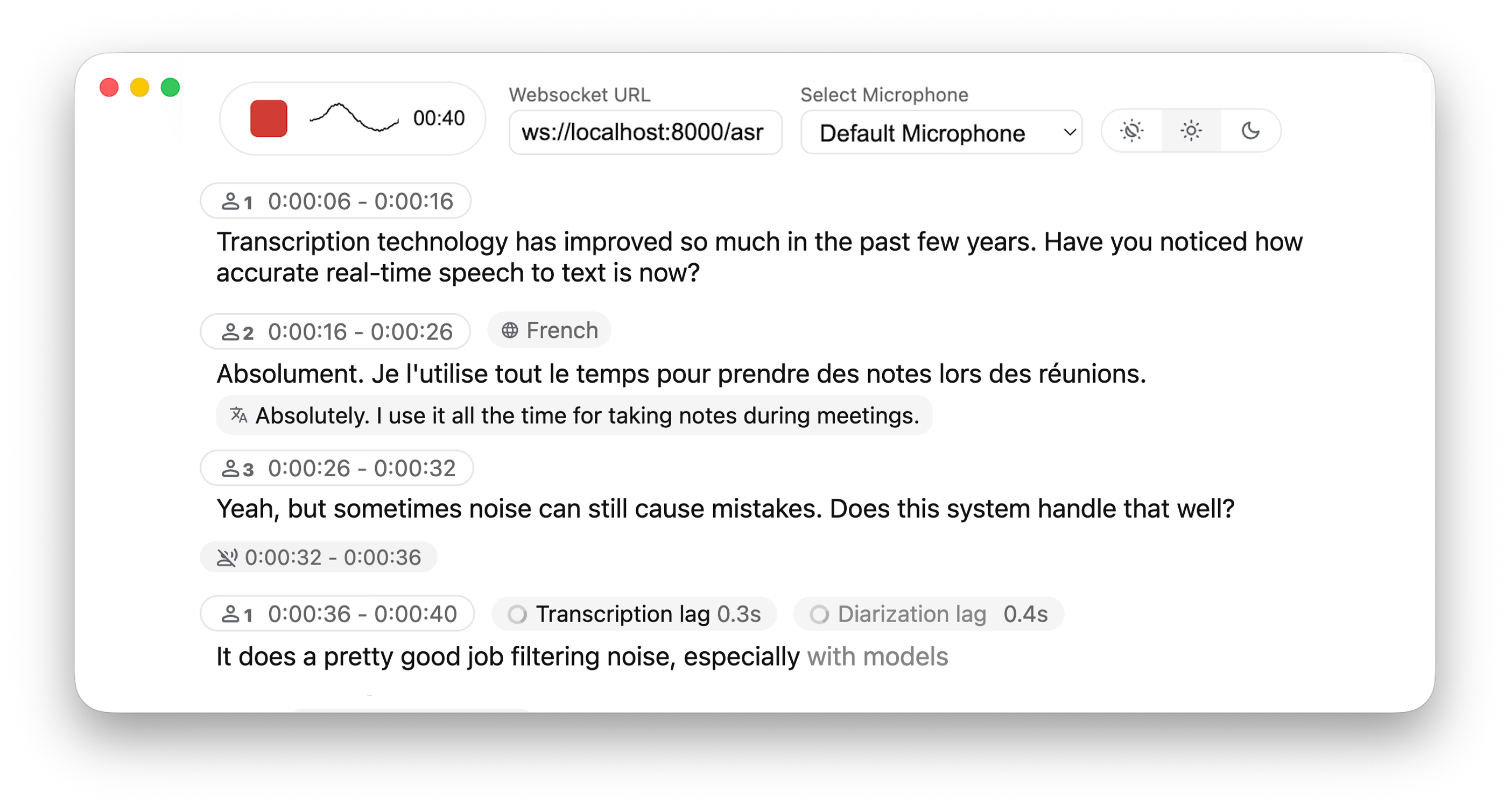

Powered by Leading Research:
- Simul-Whisper/Streaming (SOTA 2025) - Ultra-low latency transcription using AlignAtt policy.
- NLLW (2025), based on distilled NLLB (2022, 2024) - Simulatenous translation from & to 200 languages.
- WhisperStreaming (SOTA 2023) - Low latency transcription using LocalAgreement policy
- Streaming Sortformer (SOTA 2025) - Advanced real-time speaker diarization
- Diart (SOTA 2021) - Real-time speaker diarization
- Voxtral Mini (2025) - 4B-parameter multilingual speech model by Mistral AI
- Silero VAD (2024) - Enterprise-grade Voice Activity Detection
Why not just run a simple Whisper model on every audio batch? Whisper is designed for complete utterances, not real-time chunks. Processing small segments loses context, cuts off words mid-syllable, and produces poor transcription. WhisperLiveKit uses state-of-the-art simultaneous speech research for intelligent buffering and incremental processing.
Architecture
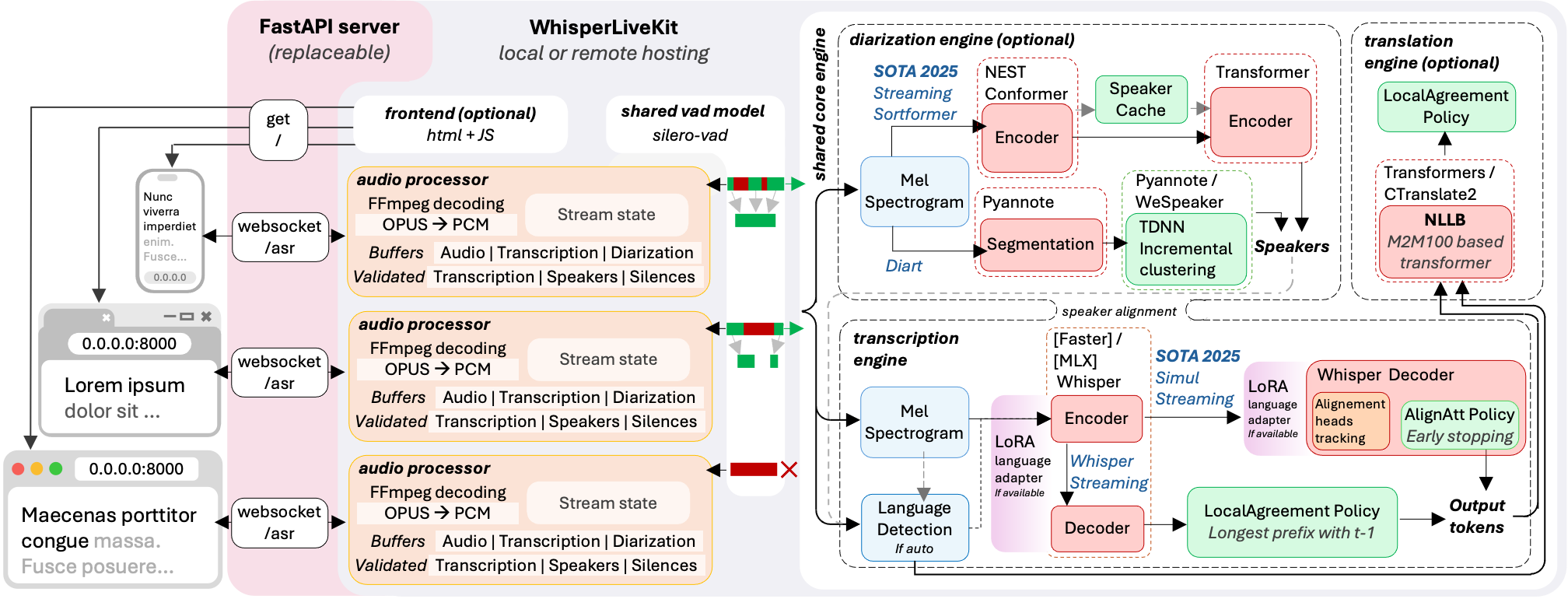
The backend supports multiple concurrent users. Voice Activity Detection reduces overhead when no voice is detected.
Installation & Quick Start
pip install whisperlivekit
Quick Start
# Start the server — open http://localhost:8000 and start talking
wlk --model base --language en
# Auto-pull model and start server
wlk run whisper:tiny
# Transcribe a file (no server needed)
wlk transcribe meeting.wav
# Generate subtitles
wlk transcribe --format srt podcast.mp3 -o podcast.srt
# Manage models
wlk models # See what's installed
wlk pull large-v3 # Download a model
wlk rm large-v3 # Delete a model
# Benchmark speed and accuracy
wlk bench
API Compatibility
WhisperLiveKit exposes multiple APIs so you can use it as a drop-in replacement:
# OpenAI-compatible REST API
curl http://localhost:8000/v1/audio/transcriptions -F file=@audio.wav
# Works with the OpenAI Python SDK
client = OpenAI(base_url="http://localhost:8000/v1", api_key="unused")
# Deepgram-compatible WebSocket (use any Deepgram SDK)
# Just point your Deepgram client at localhost:8000
# Native WebSocket for real-time streaming
ws://localhost:8000/asr
See docs/API.md for the complete API reference.
- See here for the list of all available languages.
- Check the troubleshooting guide for step-by-step fixes collected from recent GPU setup/env issues.
- For HTTPS requirements, see the Parameters section for SSL configuration options.
Optional Dependencies
| Feature | uv sync | pip install -e |
|---|---|---|
| Apple Silicon MLX Whisper backend | uv sync --extra mlx-whisper | pip install -e ".[mlx-whisper]" |
| Voxtral (MLX backend, Apple Silicon) | uv sync --extra voxtral-mlx | pip install -e ".[voxtral-mlx]" |
| CPU PyTorch stack | uv sync --extra cpu | pip install -e ".[cpu]" |
| CUDA 12.9 PyTorch stack | uv sync --extra cu129 | pip install -e ".[cu129]" |
| Translation | uv sync --extra translation | pip install -e ".[translation]" |
| Sentence tokenizer | uv sync --extra sentence_tokenizer | pip install -e ".[sentence_tokenizer]" |
| Voxtral (HF backend) | uv sync --extra voxtral-hf | pip install -e ".[voxtral-hf]" |
| Qwen3-ASR vLLM (CUDA) | uv sync --extra qwen3-vllm | pip install -e ".[qwen3-vllm]" |
| Qwen3-ASR vLLM Metal (Apple Silicon) | Install vLLM with the official vllm-metal script first, then uv sync --extra qwen3-vllm-metal | Install vLLM with the official vllm-metal script first, then pip install -e ".[qwen3-vllm-metal]" |
| Speaker diarization (Sortformer / NeMo) | uv sync --extra diarization-sortformer | pip install -e ".[diarization-sortformer]" |
| [Not recommended] Speaker diarization with Diart | uv sync --extra diarization-diart | pip install -e ".[diarization-diart]" |
Supported GPU profiles:
# Profile A: Sortformer diarization
uv sync --extra cu129 --extra diarization-sortformer
# Profile B: Voxtral HF + translation
uv sync --extra cu129 --extra voxtral-hf --extra translation
# Profile C: Qwen3-ASR vLLM
uv sync --extra qwen3-vllm
qwen3-vllm uses vLLM's CUDA wheel stack and must be installed in a separate environment from cu129. voxtral-hf / qwen3-vllm-metal and diarization-sortformer are also intentionally incompatible extras and must be installed in separate environments.
See Parameters & Configuration below on how to use them.


Benchmarks use 6 minutes of public LibriVox audiobook recordings per language (30s + 60s + 120s + 180s), with ground truth from Project Gutenberg. Fully reproducible with python scripts/run_scatter_benchmark.py.
We are actively looking for benchmark results on other hardware (NVIDIA GPUs, different Apple Silicon chips, cloud instances). If you run the benchmarks on your machine, please share your results via an issue or PR!
Use it to capture audio from web pages.
Go to chrome-extension for instructions.
Voxtral Backend
WhisperLiveKit supports Voxtral Mini,
a 4B-parameter speech model from Mistral AI that natively handles 100+ languages with automatic
language detection. Whisper also supports auto-detection (--language auto), but Voxtral's per-chunk
detection is more reliable and does not bias towards English.
# Apple Silicon (native MLX, recommended)
pip install -e ".[voxtral-mlx]"
wlk --backend voxtral-mlx
# Linux/GPU (HuggingFace transformers)
pip install transformers torch
wlk --backend voxtral
Voxtral uses its own streaming policy and does not use LocalAgreement or SimulStreaming. See BENCHMARK.md for performance numbers.
Usage Examples
Command-line Interface: Start the transcription server with various options:
# Large model and translate from french to danish
wlk --model large-v3 --language fr --target-language da
# Diarization and server listening on */80
wlk --host 0.0.0.0 --port 80 --model medium --diarization --language fr
# Voxtral multilingual (auto-detects language)
wlk --backend voxtral-mlx
Python API Integration: Check basic_server for a more complete example of how to use the functions and classes.
import asyncio
from contextlib import asynccontextmanager
from fastapi import FastAPI, WebSocket, WebSocketDisconnect
from fastapi.responses import HTMLResponse
from whisperlivekit import AudioProcessor, TranscriptionEngine, parse_args
transcription_engine = None
@asynccontextmanager
async def lifespan(app: FastAPI):
global transcription_engine
transcription_engine = TranscriptionEngine(model_size="medium", diarization=True, lan="en")
yield
app = FastAPI(lifespan=lifespan)
async def handle_websocket_results(websocket: WebSocket, results_generator):
async for response in results_generator:
await websocket.send_json(response)
await websocket.send_json({"type": "ready_to_stop"})
@app.websocket("/asr")
async def websocket_endpoint(websocket: WebSocket):
global transcription_engine
# Create a new AudioProcessor for each connection, passing the shared engine
audio_processor = AudioProcessor(transcription_engine=transcription_engine)
results_generator = await audio_processor.create_tasks()
results_task = asyncio.create_task(handle_websocket_results(websocket, results_generator))
await websocket.accept()
while True:
message = await websocket.receive_bytes()
await audio_processor.process_audio(message)
Frontend Implementation: The package includes an HTML/JavaScript implementation here. You can also import it using from whisperlivekit import get_inline_ui_html & page = get_inline_ui_html()
Parameters & Configuration
| Parameter | Description | Default |
|---|---|---|
--model | Whisper model size. List and recommandations here | small |
--model-path | Local .pt file/directory or Hugging Face repo ID containing the Whisper model. Overrides --model. Recommandations here | None |
--language | List here. If you use auto, the model attempts to detect the language automatically, but it tends to bias towards English. | auto |
--target-language | If sets, translates using NLLW. 200 languages available. If you want to translate to english, you can also use --direct-english-translation. The STT model will try to directly output the translation. | None |
--diarization | Enable speaker identification | False |
--backend-policy | Streaming strategy: 1/simulstreaming uses AlignAtt SimulStreaming, 2/localagreement uses the LocalAgreement policy | simulstreaming |
--backend | ASR backend selector. auto picks MLX on macOS (if installed), otherwise Faster-Whisper, otherwise vanilla Whisper. Options: mlx-whisper, faster-whisper, whisper, openai-api (LocalAgreement only), voxtral-mlx (Apple Silicon), voxtral (HuggingFace), qwen3-vllm, qwen3-vllm-metal (Apple Silicon) | auto |
--no-vac | Disable Voice Activity Controller. NOT ADVISED | False |
--no-vad | Disable Voice Activity Detection. NOT ADVISED | False |
--warmup-file | Audio file path for model warmup | jfk.wav |
--host | Server host address | localhost |
--port | Server port | 8000 |
--ssl-certfile | Path to the SSL certificate file (for HTTPS support) | None |
--ssl-keyfile | Path to the SSL private key file (for HTTPS support) | None |
--forwarded-allow-ips | Ip or Ips allowed to reverse proxy the whisperlivekit-server. Supported types are IP Addresses (e.g. 127.0.0.1), IP Networks (e.g. 10.100.0.0/16), or Literals (e.g. /path/to/socket.sock) | None |
--cors-origins | Comma-separated list of allowed CORS origins. Empty disables CORS; use * to allow all origins. | empty |
--pcm-input | raw PCM (s16le) data is expected as input and FFmpeg will be bypassed. Frontend will use AudioWorklet instead of MediaRecorder | False |
--lora-path | Path or Hugging Face repo ID for LoRA adapter weights (e.g., qfuxa/whisper-base-french-lora). Only works with native Whisper backend (--backend whisper) | None |
| Translation options | Description | Default |
|---|---|---|
--nllb-backend | transformers or ctranslate2 | transformers |
--nllb-size | 600M or 1.3B | 600M |
| Diarization options | Description | Default |
|---|---|---|
--diarization-backend | diart or sortformer | sortformer |
--disable-punctuation-split | [NOT FUNCTIONAL IN 0.2.15 / 0.2.16] Disable punctuation based splits. See #214 | False |
--segmentation-model | Hugging Face model ID for Diart segmentation model. Available models | pyannote/segmentation-3.0 |
--embedding-model | Hugging Face model ID for Diart embedding model. Available models | pyannote/embedding |
| SimulStreaming backend options | Description | Default |
|---|---|---|
--disable-fast-encoder | Disable Faster Whisper or MLX Whisper backends for the encoder (if installed). Inference can be slower but helpful when GPU memory is limited | False |
--custom-alignment-heads | Use your own alignment heads, useful when --model-dir is used. Use scripts/determine_alignment_heads.py to extract them. | |
None | ||
--frame-threshold | AlignAtt frame threshold (lower = faster, higher = more accurate) | 25 |
--beams | Number of beams for beam search (1 = greedy decoding) | 1 |
--decoder | Force decoder type (beam or greedy) | auto |
--audio-max-len | Maximum audio buffer length (seconds) | 30.0 |
--audio-min-len | Minimum audio length to process (seconds) | 0.0 |
--cif-ckpt-path | Path to CIF model for word boundary detection | None |
--never-fire | Never truncate incomplete words | False |
--init-prompt | Initial prompt for the model | None |
--static-init-prompt | Static prompt that doesn't scroll | None |
--max-context-tokens | Maximum context tokens | Depends on model used, but usually 448. |
| WhisperStreaming backend options | Description | Default |
|---|---|---|
--confidence-validation | Use confidence scores for faster validation | False |
--buffer_trimming | Buffer trimming strategy (sentence or segment) | segment |
For diarization using Diart, you need to accept user conditions here for the
pyannote/segmentationmodel, here for thepyannote/segmentation-3.0model and here for thepyannote/embeddingmodel. Then, login to HuggingFace:huggingface-cli login
🚀 Deployment Guide
To deploy WhisperLiveKit in production:
-
Server Setup: Install production ASGI server & launch with multiple workers
pip install uvicorn gunicorn gunicorn -k uvicorn.workers.UvicornWorker -w 4 your_app:app -
Frontend: Host your customized version of the
htmlexample & ensure WebSocket connection points correctly -
Nginx Configuration (recommended for production):
server { listen 80; server_name your-domain.com; location / { proxy_pass http://localhost:8000; proxy_set_header Upgrade $http_upgrade; proxy_set_header Connection "upgrade"; proxy_set_header Host $host; }} -
HTTPS Support: For secure deployments, use "wss://" instead of "ws://" in WebSocket URL
🐋 Docker
Deploy the application easily using Docker with GPU or CPU support.
Prerequisites
- Docker installed on your system
- For GPU support: NVIDIA Docker runtime installed
Quick Start
With GPU acceleration (recommended):
docker build -t wlk .
docker run --gpus all -p 8000:8000 --name wlk wlk
CPU only:
docker build -f Dockerfile.cpu -t wlk --build-arg EXTRAS="cpu" .
docker run -p 8000:8000 --name wlk wlk
Advanced Usage
Custom configuration:
# Example with custom model and language
docker run --gpus all -p 8000:8000 --name wlk wlk --model large-v3 --language fr
Compose (recommended for cache + token wiring):
# GPU Sortformer profile
docker compose up --build wlk-gpu-sortformer
# GPU Voxtral profile
docker compose up --build wlk-gpu-voxtral
# CPU service
docker compose up --build wlk-cpu
Memory Requirements
- Large models: Ensure your Docker runtime has sufficient memory allocated
Customization
--build-argOptions:EXTRAS="cu129,diarization-sortformer"- GPU Sortformer profile extras.EXTRAS="cu129,voxtral-hf,translation"- GPU Voxtral profile extras.EXTRAS="cpu,diarization-diart,translation"- CPU profile extras.- Hugging Face cache + token are configured in
compose.ymlusing a named volume andHF_TKN_FILE(default:./token).
Testing & Benchmarks
# Quick benchmark with the CLI
wlk bench
wlk bench --backend faster-whisper --model large-v3
wlk bench --languages all --json results.json
# Install test dependencies for full suite
pip install -e ".[test]"
# Run unit tests (no model download required)
pytest tests/ -v
# Speed vs Accuracy scatter plot (all backends, compute-aware + unaware)
python scripts/create_long_samples.py # generate ~90s test samples (cached)
python scripts/run_scatter_benchmark.py # English (both modes)
python scripts/run_scatter_benchmark.py --lang fr # French
Use Cases
Capture discussions in real-time for meeting transcription, help hearing-impaired users follow conversations through accessibility tools, transcribe podcasts or videos automatically for content creation, transcribe support calls with speaker identification for customer service...