Strefer: Empowering Video LLMs with Space-Time Referring and Reasoning via Synthetic Instruction Data
October 17, 2025 · View on GitHub
Honglu Zhou, Xiangyu Peng, Shrikant Kendre, Michael S. Ryoo, Silvio Savarese, Caiming Xiong, Juan Carlos Niebles

Table of Contents
- Highlights 🌟
- Download Strefer-Synthesized Instruction Data 💾
- Download Data for Timestamp-based Yes/No QA on QVHighlights ✅
- Download Model (BLIP-3-Strefer) for Space-Time Referring 🤖
- Code for Model Training and Inference 🧠
- Code for Referring Masklet Generation 💻
- License 💼
- Citation 📝
Highlights 🌟
This is the repository for our paper Strefer: Empowering Video LLMs with Space-Time Referring and Reasoning via Synthetic Instruction Data.

Strefer is a data engine that synthesizes instruction-response pairs through a scalable, grounded approach that enhances fine-grained spatial and temporal perception and reasoning over videos for tuning Video LLMs.
By design, Strefer generates instruction-response pairs—requiring no legacy annotations—based on its pseudo-annotated video metadata. It automatically clips the video into segments and pseudo-annotates the video metadata, including active entities, their locations (as masklets), and action timelines, for complex video scenarios, such as scenes containing multiple entities of the same category, and cases where entities do not appear in the first frame, or temporarily exit and re-enter the frame.
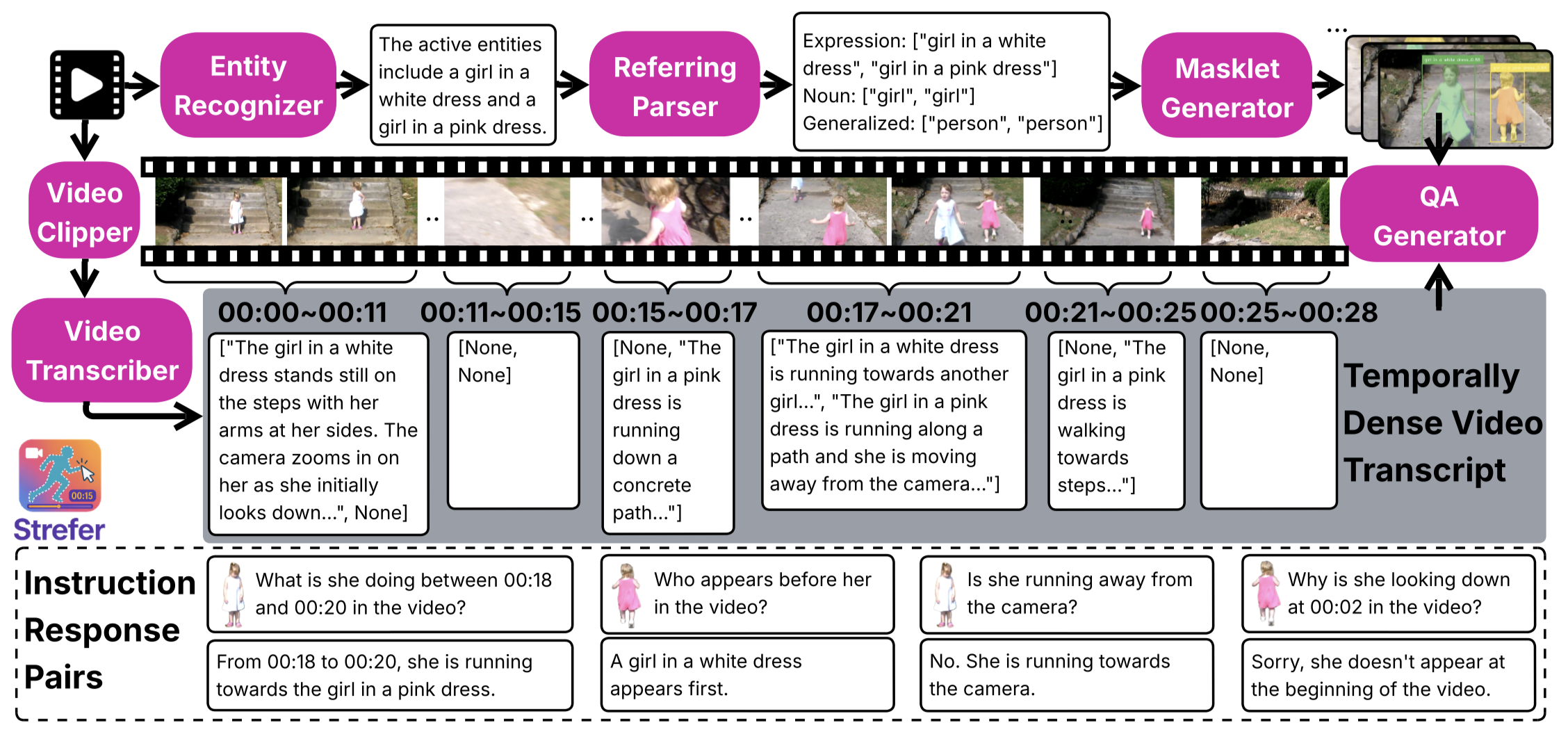
Strefer enhances the ability of Video LLMs to interpret spatial and temporal references, fostering more versatile, space-time-aware reasoning essential for real-world AI companions.

Download Strefer-Synthesized Instruction Data 💾
We release the final recipe descirbed in our paper including the Strefer synthesized instruction-response pairs on Hugging Face: https://huggingface.co/datasets/strefer/strefer
The following image illustrates the data composition of the final recipe used in our experiments:

If you hope to replicate model training, please follow the following steps to download and prepare the data:
git clone --recurse-submodules https://github.com/SalesforceAIResearch/strefer.git
cd blip-3-strefer
mkdir data
cd data
git clone https://huggingface.co/datasets/strefer/strefer
apt-get install git-lfs
git lfs install
git lfs pull
Download Data for Timestamp-based Yes/No QA on QVHighlights ✅
Timestamp-based Yes/No QA on QVHighlights is a task that repurposes existing annotations from the video highlight detection dataset, QVHighlights. We transform annotations from QVHighlights into questions tied to specific timestamps, each expecting a ‘Yes’ or ‘No’ answer. The task measures how well a model understands events in videos based on specific timestamp references.
For details on how we construct the question-answer pairs, please check page 9 in our paper.
We release this data on Hugging Face: https://huggingface.co/datasets/strefer/qvhighlights-yesno-qa
Download Model (BLIP-3-Strefer) for Space-Time Referring 🤖
We release the final checkpoint of our model, BLIP-3-Strefer, for space-time referring. For details on how to use this model, please refer to this README.

Code for Model Training and Inference 🧠
Our model incorporates a spatiotemporal object encoder from Video-Refer for region comprehension and temporal tokens from Grounded-VideoLLM for precise timestamp comprehension. These modules are integrated into the BLIP-3-Video architecture. We call this model trained using our Strefer-synthesized instruction data as BLIP-3-Strefer.
We release our code used to train BLIP-3-Strefer and perform inference. For detailed guidelines, please refer to this README.
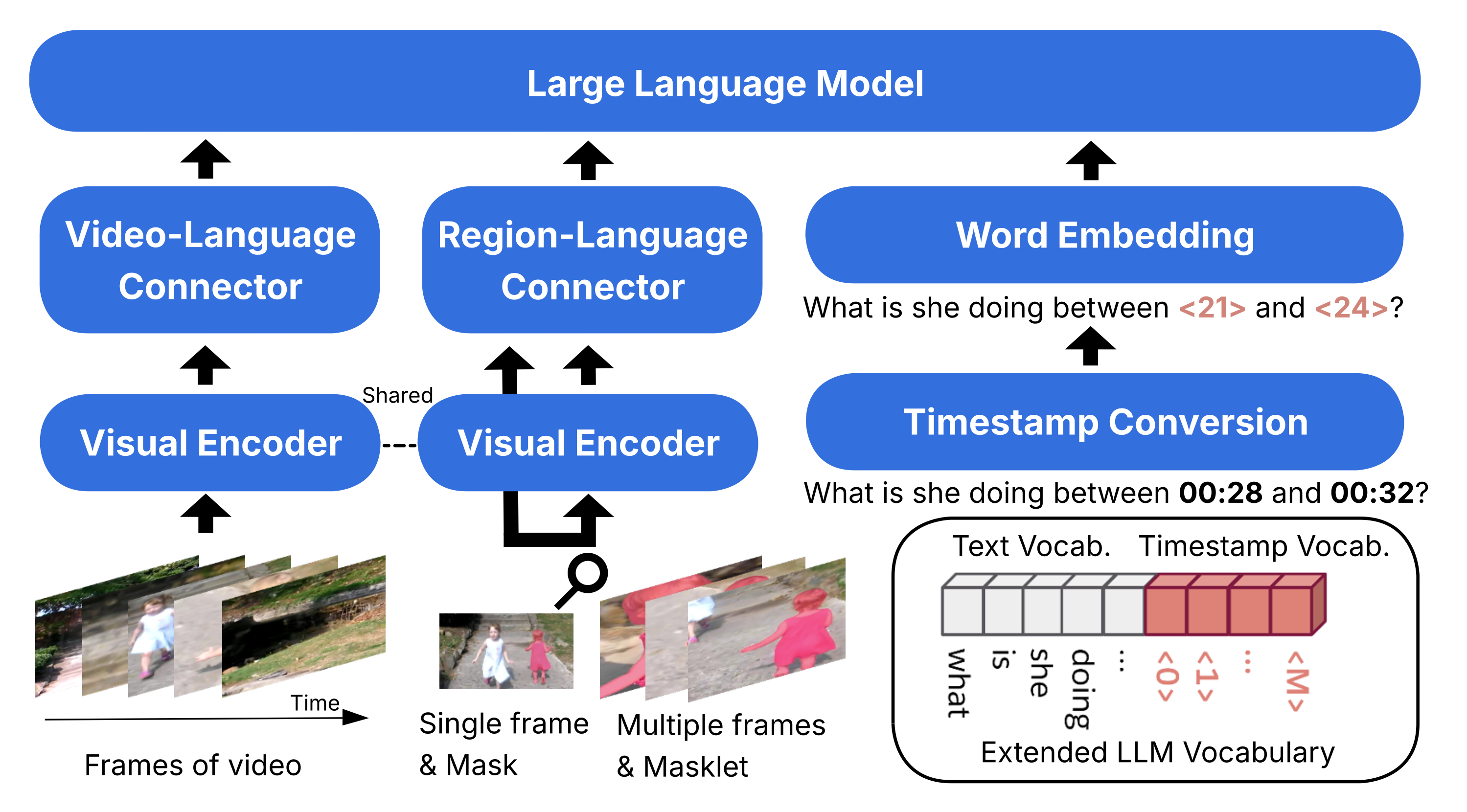
Code for Referring Masklet Generation 💻
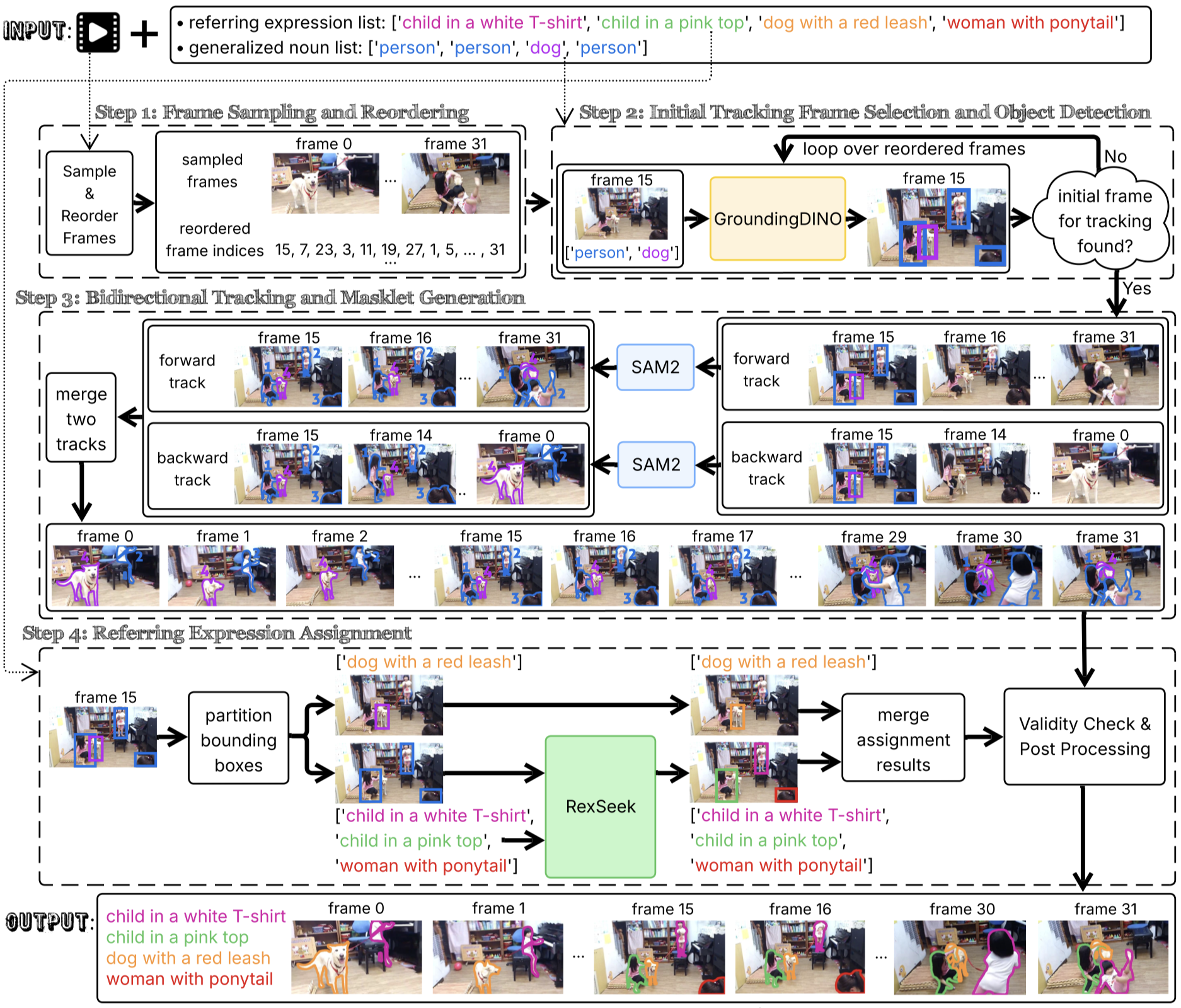
Our novel Referring Masklet Generation Pipeline is a key module within Strefer. This pipeline produces tracked segmentation masks from videos with complex structures based on multi-word natural language referring expressions.
Our referring masklet generator is carefully crafted to address key limitations overlooked by prior works by orchestrating complementary strengths of the state-of-the-art pixel-level vision foundation models to achieve more effective results. The code has been released; for detailed installation and usage guidelines, please refer to this README.
License 💼
Our code, data, and models are released for research-only, non-commercial purposes under a CC-BY-NC 4.0 license. Users are responsible for making their own assessment of any obligations or responsibilities under the corresponding licenses or the terms and conditions applicable to the original code, data, and model weights.
Citation 📝
Please cite us if you find our work helpful. Thank you! 🥰🙏💖
@article{zhou2025strefer,
title={Strefer: Empowering Video LLMs with Space-Time Referring and Reasoning via Synthetic Instruction Data},
author={Zhou, Honglu and Peng, Xiangyu and Kendre, Shrikant and Ryoo, Michael S. and Savarese, Silvio and Xong, Caiming and Niebles, Juan Carlos},
journal={arXiv preprint arXiv:2509.03501},
year={2025}
}