lru-cache.md
June 12, 2026 · View on GitHub
LRU 是 Least Recently Used 的缩写,意思是最近最少使用。当缓存容量满了,需要淘汰最久没有被访问的数据。
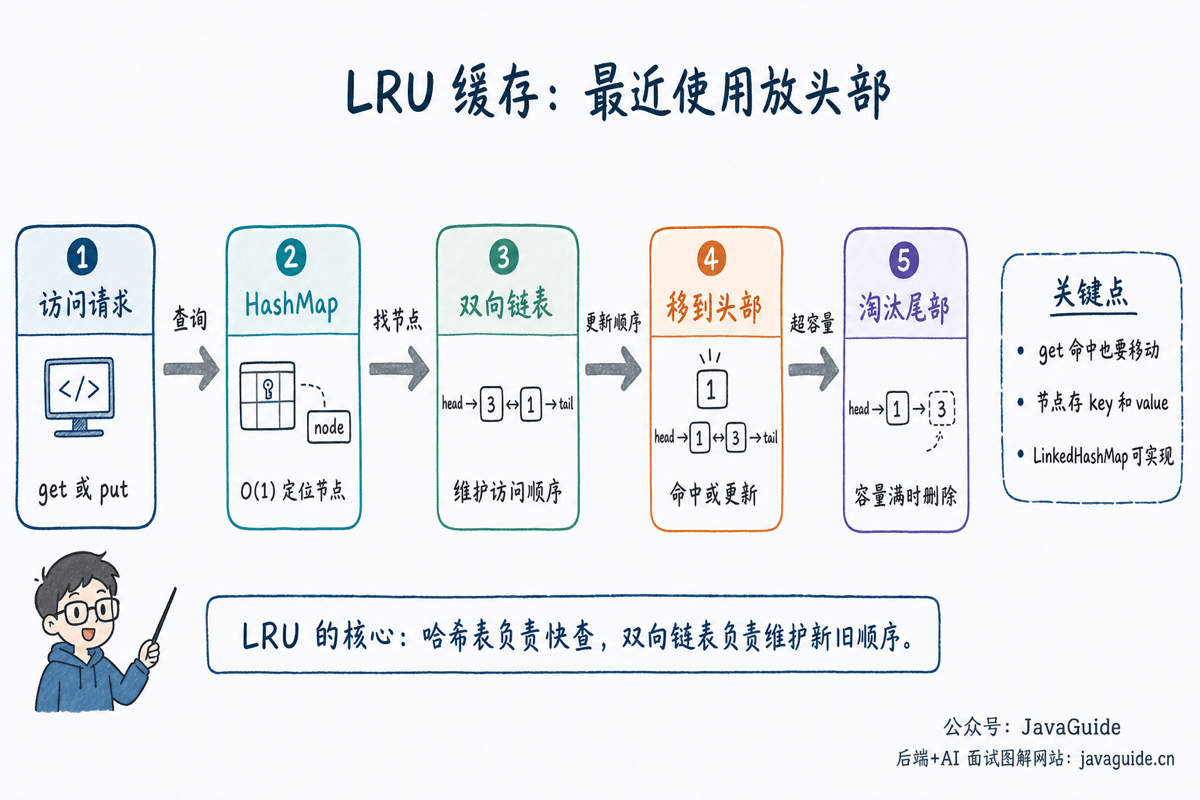
面试里手写 LRU 很高频,因为它把哈希表和双向链表结合在一起:哈希表负责 O(1) 查找节点,双向链表负责 O(1) 移动节点和删除尾节点。
文章内容概览:
- 什么是 LRU 缓存?
- LRU 为什么适合做缓存淘汰?
- 为什么需要哈希表 + 双向链表?
- 如何手写
get和put? - Java
LinkedHashMap如何实现 LRU? - 真实工程里的 LRU 还要考虑什么?
什么是 LRU 缓存?
缓存的核心矛盾是:空间有限,但希望尽量把“未来还会被访问”的数据留在内存里。
问题是,程序并不知道未来。LRU 的做法是用“最近访问过”去近似预测“接下来还可能访问”。如果一个数据刚刚被访问过,它很可能还会再被访问;如果一个数据很久没被访问,缓存满的时候就优先淘汰它。
举个例子,容量为 2 的缓存按顺序访问:
put(1, 1)
put(2, 2)
get(1)
put(3, 3)
在 put(3, 3) 之前,缓存里有 1 和 2。虽然 1 更早插入,但它刚被 get(1) 访问过,所以最近最少使用的是 2,最终应该淘汰 2。
这个例子也说明了一点:LRU 看的不是“谁最早插入”,而是“谁最久没被访问”。
为什么需要缓存淘汰策略?
缓存不是无限大的。无论是本地内存缓存、Redis、数据库 Buffer Pool,还是操作系统里的页面缓存,都要面对容量上限。
容量满了之后,如果没有淘汰策略,就只能拒绝新数据或者随机删数据。随机删当然简单,但可能把刚好很热的数据删掉,导致命中率变差。LRU 则利用访问时间顺序做了一个经验判断:长期没被碰过的数据,短期内再次访问的概率通常更低。
常见淘汰策略可以简单对比一下:
| 策略 | 淘汰依据 | 特点 |
|---|---|---|
| FIFO | 最早进入缓存的数据 | 实现简单,但不关心数据后来是否被频繁访问 |
| LRU | 最久没有被访问的数据 | 适合有时间局部性的访问模式 |
| LFU | 访问次数最少的数据 | 适合长期热点明显的场景,但需要维护频率信息 |
| TTL | 过期时间 | 适合数据有明确有效期的场景,不等同于容量淘汰 |
LRU 之所以常被拿来面试,是因为它既有真实工程背景,又能很好地考察数据结构组合。
面试考察重点
- 能说清为什么只用哈希表或只用链表都不够。
- 能写
get和put。 - 能解释双向链表头尾分别代表什么。
- 能处理容量满、更新已有 key、删除尾节点等边界。
- 能知道 Java
LinkedHashMap可以实现 LRU。
LRU 的访问顺序怎么维护?
LRU 缓存里,每一次访问都会改变数据的新旧程度。
通常我们会约定:
- 链表头部表示最近使用的数据。
- 链表尾部表示最久未使用的数据。
get(key)命中后,把对应节点移动到头部。put(key, value)如果是新 key,把新节点插入头部。put(key, value)如果是已有 key,更新 value 后也要移动到头部。- 容量超过上限时,删除尾部节点。
这里最容易漏的是 get()。很多同学会觉得 get() 只是读数据,不该改结构。但对 LRU 来说,读也是一次访问;只要命中缓存,这个 key 的“最近使用时间”就变新了。
数据结构设计
| 组件 | 作用 |
|---|---|
HashMap<Integer, Node> | 根据 key 快速找到链表节点 |
| 双向链表 | 按访问时间排序,头部是最近使用,尾部是最久未使用 |
| 虚拟头尾节点 | 简化插入和删除边界 |
访问一个 key 后,需要把它移动到链表头部。插入新 key 时,也放到头部。容量超限时,删除尾部前一个节点。
为什么必须两个结构配合?
只用哈希表,可以 O(1) 找到 value,但不知道哪个 key 最久没用。你还得额外维护访问顺序。
只用链表,可以维护访问顺序,尾部就是该淘汰的节点。但每次根据 key 查找节点都要从头扫到尾,复杂度是 O(n)。
哈希表 + 双向链表刚好补齐彼此短板:
- 哈希表让我们能根据 key 直接定位链表节点。
- 双向链表让我们能快速移动节点、删除尾部节点。
- 节点里同时存 key 和 value,是为了淘汰尾节点时能从哈希表里删除对应 key。
面试手写路径
LRU 的代码细节多,建议不要一上来就写完整类。面试时可以先把操作拆开:
- 先定义链表顺序:头部表示最近使用,尾部表示最久未使用。
- 再定义
get:查不到返回-1,查到后移动到头部。 - 再定义
put:已有 key 更新值并移动到头部;新 key 插入头部。 - 最后处理淘汰:超过容量后删除尾部前一个节点,并从哈希表删除。
- 把链表操作封装成
addToHead、remove、moveToHead、removeTail。
这样写的好处是,get 和 put 都只组合几个基础链表操作,不会在主流程里反复改指针,出错概率低很多。
为什么用双向链表?
把一个节点移动到头部,需要先把它从原位置摘下来,再插到头节点后面。
如果用单向链表,删除当前节点时必须知道它的前驱节点。哈希表里即使能直接找到当前节点,也找不到它前面的节点,还是要从头遍历。
双向链表的节点同时有 prev 和 next,删除任意节点只需要改四个指针:
node.prev.next = node.next;
node.next.prev = node.prev;
这就是 LRU 要用双向链表的关键原因:它不只是要删除尾节点,还要在 get() 命中和 put() 更新已有 key 时,把任意节点移动到头部。
虚拟头尾节点也很重要。有了 head 和 tail 两个哨兵节点,插入头部、删除尾部、处理空链表时都能走同一套代码,不需要到处写 null 判断。
手写 LRU
class LRUCache {
private final int capacity;
private final Map<Integer, Node> map = new HashMap<>();
private final Node head = new Node(0, 0);
private final Node tail = new Node(0, 0);
LRUCache(int capacity) {
this.capacity = capacity;
head.next = tail;
tail.prev = head;
}
int get(int key) {
Node node = map.get(key);
if (node == null) {
return -1;
}
moveToHead(node);
return node.value;
}
void put(int key, int value) {
Node node = map.get(key);
if (node != null) {
node.value = value;
moveToHead(node);
return;
}
Node newNode = new Node(key, value);
map.put(key, newNode);
addToHead(newNode);
if (map.size() > capacity) {
Node removed = removeTail();
map.remove(removed.key);
}
}
private void moveToHead(Node node) {
remove(node);
addToHead(node);
}
private void addToHead(Node node) {
node.prev = head;
node.next = head.next;
head.next.prev = node;
head.next = node;
}
private void remove(Node node) {
node.prev.next = node.next;
node.next.prev = node.prev;
}
private Node removeTail() {
Node node = tail.prev;
remove(node);
return node;
}
private static class Node {
int key;
int value;
Node prev;
Node next;
Node(int key, int value) {
this.key = key;
this.value = value;
}
}
}
get 和 put 的时间复杂度都是 O(1),空间复杂度是 O(capacity)。
操作过程示意
假设容量为 2,按顺序执行:
put(1, 1)
put(2, 2)
get(1)
put(3, 3)
链表状态变化如下,左侧表示最近使用:
| 操作 | 链表状态 | 说明 |
|---|---|---|
| 初始状态 | 空 | 虚拟头尾相连,缓存为空 |
put(1, 1) | 1 | 新节点插入头部 |
put(2, 2) | 2 -> 1 | 2 是最近使用 |
get(1) | 1 -> 2 | 访问 1 后移动到头部 |
put(3, 3) | 3 -> 1 | 容量超限,淘汰尾部的 2 |
这张表能帮助检查两个点:访问已有节点要更新使用顺序;淘汰节点时,删除的是最久未使用的尾部节点,而不是刚插入的新节点。
LinkedHashMap 实现
Java 的 LinkedHashMap 支持按访问顺序维护元素:
class LRUCacheWithLinkedHashMap extends LinkedHashMap<Integer, Integer> {
private final int capacity;
LRUCacheWithLinkedHashMap(int capacity) {
super(capacity, 0.75f, true);
this.capacity = capacity;
}
@Override
protected boolean removeEldestEntry(Map.Entry<Integer, Integer> eldest) {
return size() > capacity;
}
}
构造函数里的第三个参数 accessOrder 设置为 true,表示按照访问顺序排序,而不是插入顺序。
LinkedHashMap 官方文档里也专门提到过这种 access-order 模式适合构建 LRU 缓存。这里有两个点要记住:
accessOrder = false时,遍历顺序是插入顺序;accessOrder = true时,遍历顺序是访问顺序。removeEldestEntry()会在插入新映射后被调用,返回true时删除最旧的 entry。
不过,LinkedHashMap 不是线程安全的。如果要在多线程环境里直接用它做本地缓存,需要自己加锁,或者选择成熟缓存库。
LRU 和 Redis 有什么关系?
Redis 作为缓存使用时,也需要在内存达到 maxmemory 上限后执行淘汰策略。Redis 支持 allkeys-lru、volatile-lru 等策略:
allkeys-lru:从所有 key 里淘汰最近最少使用的 key。volatile-lru:只从设置了过期时间的 key 里淘汰最近最少使用的 key。
不过 Redis 的 LRU 不是面试手写题里的“精确 LRU”。为了节省内存和 CPU,Redis 使用的是近似 LRU:随机采样一小批 key,从中挑出最久没访问的 key 淘汰。采样数量可以通过 maxmemory-samples 调整。
这也能帮助我们理解真实工程和面试题的区别:面试题通常要求用哈希表 + 双向链表实现精确 LRU;工程系统会根据内存、吞吐、并发和命中率做折中。
工程场景
- 本地缓存淘汰。
- 操作系统页面置换。
- 热点数据缓存。
- 网关、客户端 SDK 或中间件里的小容量结果缓存。
真实工程里还要考虑线程安全、过期时间、最大内存、统计指标和淘汰回调。面试手写 LRU 主要考数据结构组合,不需要把这些都写进代码。
如果是 Java 项目里的本地缓存,很多时候不会自己手写 LRU,而是直接用 Caffeine 这类缓存库。原因也很现实:工程缓存不只要容量淘汰,还要处理过期、并发、加载、统计、异步刷新、不同 entry 的权重等问题。Caffeine 官方文档里就把淘汰分成基于大小、基于时间、基于引用等多类。
面试追问
| 追问 | 回答重点 |
|---|---|
为什么不用单独的 HashMap? | HashMap 能查值,但不知道谁最久没被使用 |
| 为什么不用单独的链表? | 链表能维护顺序,但按 key 查找节点需要 O(n) |
| 为什么要用双向链表? | 删除任意节点时需要同时连接前驱和后继,单向链表无法 O(1) 找到前驱 |
| 为什么要用虚拟头尾节点? | 统一空链表、头节点、尾节点的插入删除逻辑,减少分支判断 |
LinkedHashMap 怎么实现 LRU? | 构造时开启 accessOrder,重写 removeEldestEntry 控制容量 |
| 真实缓存还要考虑什么? | 线程安全、过期时间、最大内存、淘汰回调、命中率统计和缓存击穿等工程问题 |
易错点
- 更新已有 key 时,也要移动到头部。
- 删除尾节点后,别忘了从哈希表里删除 key。
- 双向链表删除节点时要同时改前后两个指针。
- 虚拟头尾节点可以减少空链表边界判断。
LinkedHashMap的accessOrder要设为true。
高频问题自测
- LRU 为什么需要哈希表和双向链表配合?
get操作为什么也要移动节点?- 更新已有 key 时,为什么不能只改 value?
- 淘汰尾节点后,为什么还要从哈希表删除 key?
LinkedHashMap的插入顺序和访问顺序有什么区别?