timeout-and-retry.md
May 30, 2026 · View on GitHub
由于网络抖动、硬件故障、进程异常、依赖服务不可用等问题的不确定性,我们的系统或者服务永远不可能保证时刻都是可用的状态。
为了最大限度地减小系统或者服务出现故障之后带来的影响,我们需要用到 超时(Timeout) 和 重试(Retry) 机制。
超时和重试的核心思想确实不难理解,但在生产环境中正确使用它们却有不少门道。你平时接触到的绝大部分涉及远程调用的系统或者服务都会应用超时和重试机制。尤其是对于微服务系统来说,正确设置超时和重试非常重要。单体服务通常只涉及数据库、缓存、第三方 API、中间件等的网络调用,而微服务系统内部各个服务之间还存在着网络调用。
超时机制
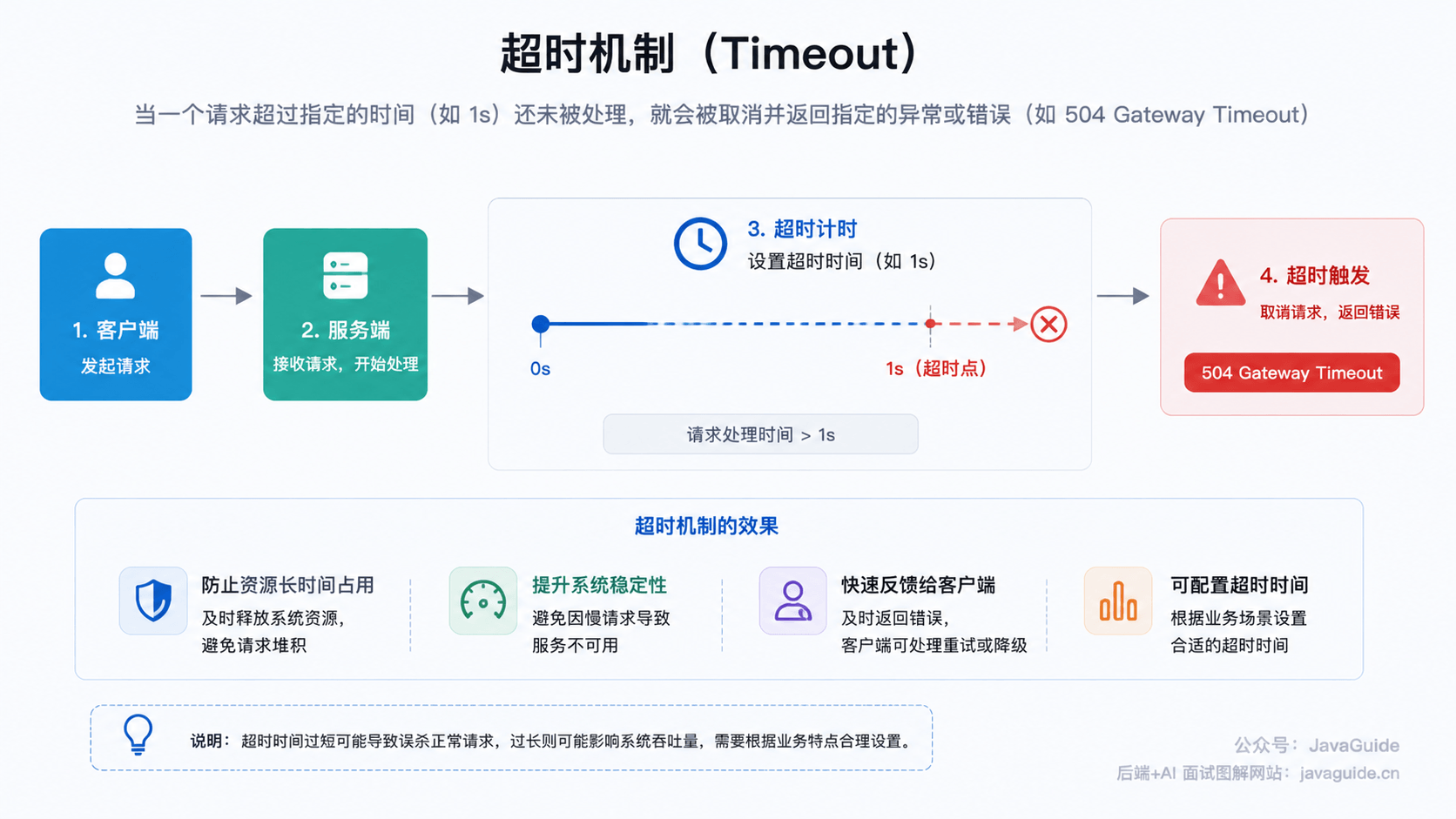
什么是超时机制?
超时机制 说的是当一个请求超过指定的时间(比如 1s)还没有被处理的话,这个请求就会直接被取消并抛出指定的异常或者错误(比如 504 Gateway Timeout)。
我们平时接触到的超时可以简单分为下面 2 种:
| 超时类型 | 说明 | 建议值 |
|---|---|---|
| 连接超时(Connect Timeout) | 客户端与服务端建立 TCP 连接的最长等待时间 | 1000ms ~ 5000ms |
| 读取超时(Read Timeout) | 连接已建立后,客户端等待对端返回数据的最长等待时间 | 1000ms ~ 3000ms |
入门时可以先理解连接超时和读取超时,但 生产环境还要看客户端是否支持更多维度的超时配置:
| 超时阶段 | 说明 |
|---|---|
| DNS 解析超时 | 域名解析的最长等待时间 |
| 连接池获取连接超时 | 从连接池获取可用连接的最长等待时间 |
| Connect Timeout | TCP 建立连接的最长等待时间 |
| TLS 握手超时 | TLS/SSL 握手阶段的最长等待时间 |
| Write Timeout | 请求体写入的最长等待时间 |
| Read / Response Timeout | 等待响应数据读取的最长等待时间 |
| Call Timeout / Deadline | 整个调用的总超时时间,包含所有阶段 |
| 空闲连接清理超时 | 连接池中空闲连接的最大存活时间 |
不同 HTTP/RPC 客户端对 read timeout、response timeout、call timeout 的覆盖范围不同,配置时必须绑定具体客户端实现的文档。
为什么需要超时机制?
如果没有设置超时的话,就可能会导致 服务端连接数爆炸 和 大量请求堆积 的问题。
这些堆积的连接和请求会消耗系统资源,影响新收到的请求的处理。严重的情况下,甚至会拖垮整个系统或者服务。
我之前在实际项目就遇到过类似的问题,整个网站无法正常处理请求,服务器负载直接快被拉满。后面发现原因是项目超时设置错误加上客户端请求处理异常,导致服务端连接数接近 40 万,这么多堆积的连接直接拖垮了整个系统。
超时时间应该如何设置?
超时时间应该设置多长,是一个需要结合业务场景判断的问题。超时值设置太高或者太低都有风险:
| 设置方式 | 风险 |
|---|---|
| 设置太高 | 降低超时机制的有效性,系统依然可能出现大量慢请求堆积的问题 |
| 设置太低 | 在系统处理速度变慢时(如请求突然增多),大量请求超时重试,加重系统压力,可能导致雪崩 |
通常情况下,我们建议:
- 读取超时:对于延迟敏感型在线服务的内部 RPC 调用,可以先根据历史 P99/P999 延迟、核心链路 SLO 和可接受的误超时率设置初始值,再压测调整。比如 AWS 的经验是:先确定可接受的 false timeout 比例(例如 0.1%),再选择对应延迟百分位(如 P99.9)作为超时起点。
- 连接超时:要按网络环境区分。同机房内网调用通常应较短;跨地域、公网、代理链路、TLS 冷连接可能需要更长。连接池场景还要区分首次建连和复用连接,建议在 1000ms ~ 5000ms 之内。
没有银弹! 超时值具体该设置多大,还是要根据实际项目的需求和情况慢慢调整优化得到。
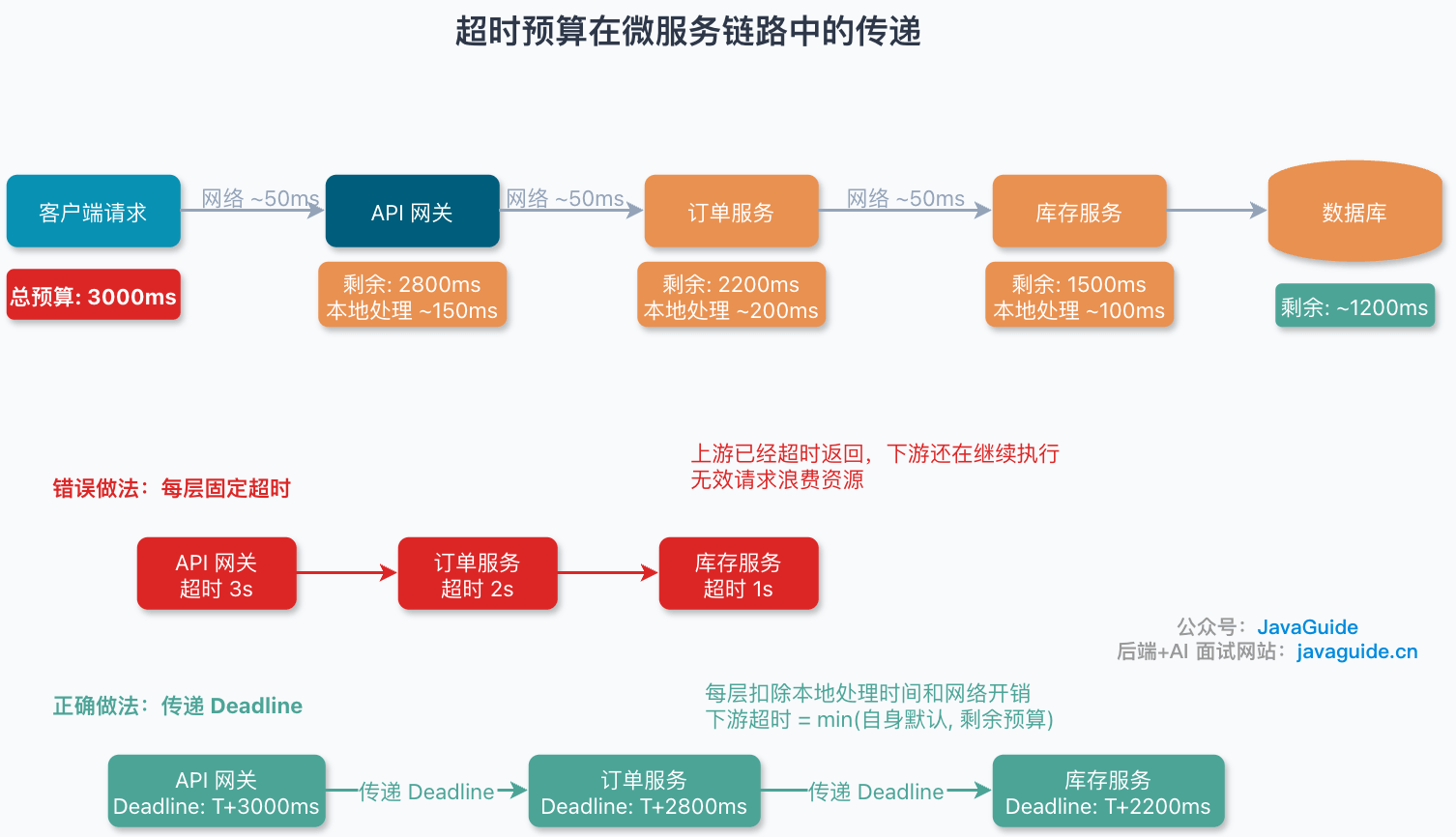
在微服务调用链中,还要遵循一个原则:下游超时要小于上游超时,并给网络开销和本地处理预留余量。
更推荐的做法是传递 deadline 或 timeout budget:入口请求有一个总时间预算,每经过一层都要扣除本地处理、排队、网络和下游调用时间。下游超时应小于调用方剩余预算,而不是每层拍脑袋固定 3s、2s、1s。否则上游已经超时返回,下游还在继续执行无效请求,容易放大资源浪费。
更进一步,参考 美团的 Java 线程池参数动态配置 思想,我们也可以将超时弄成 可配置化的参数 而不是固定的,比较简单的一种办法就是将超时的值放在配置中心中。这样的话,我们就可以根据系统或者服务的状态动态调整超时值了。
超时配置动态调整要灰度发布,并观察 P99/P999 延迟、超时率、线程池队列、连接池等待时间和重试量,不能大范围直接推全量。
超时、重试、熔断、限流的组合关系
只设置超时和重试还不够。超时和重试是弹性手段,但如果下游持续异常,重试反而会放大故障。生产环境通常需要 超时 + 重试 + 熔断 + 限流 组合使用:
| 机制 | 职责 | 关键点 |
|---|---|---|
| 超时(Timeout) | 及时释放等待资源 | 避免请求无限堆积 |
| 重试(Retry) | 处理瞬态失败 | 必须限制次数、退避、加 Jitter |
| 限流(Rate Limit) | 限制进入系统的请求量 | 保护下游不被流量冲垮 |
| 熔断(Circuit Breaker) | 避免继续打异常下游 | 快速失败,给下游恢复时间 |
| 隔离(Bulkhead) | 限制故障影响面 | 线程池 / 信号量隔离,防止级联失败 |
重试机制
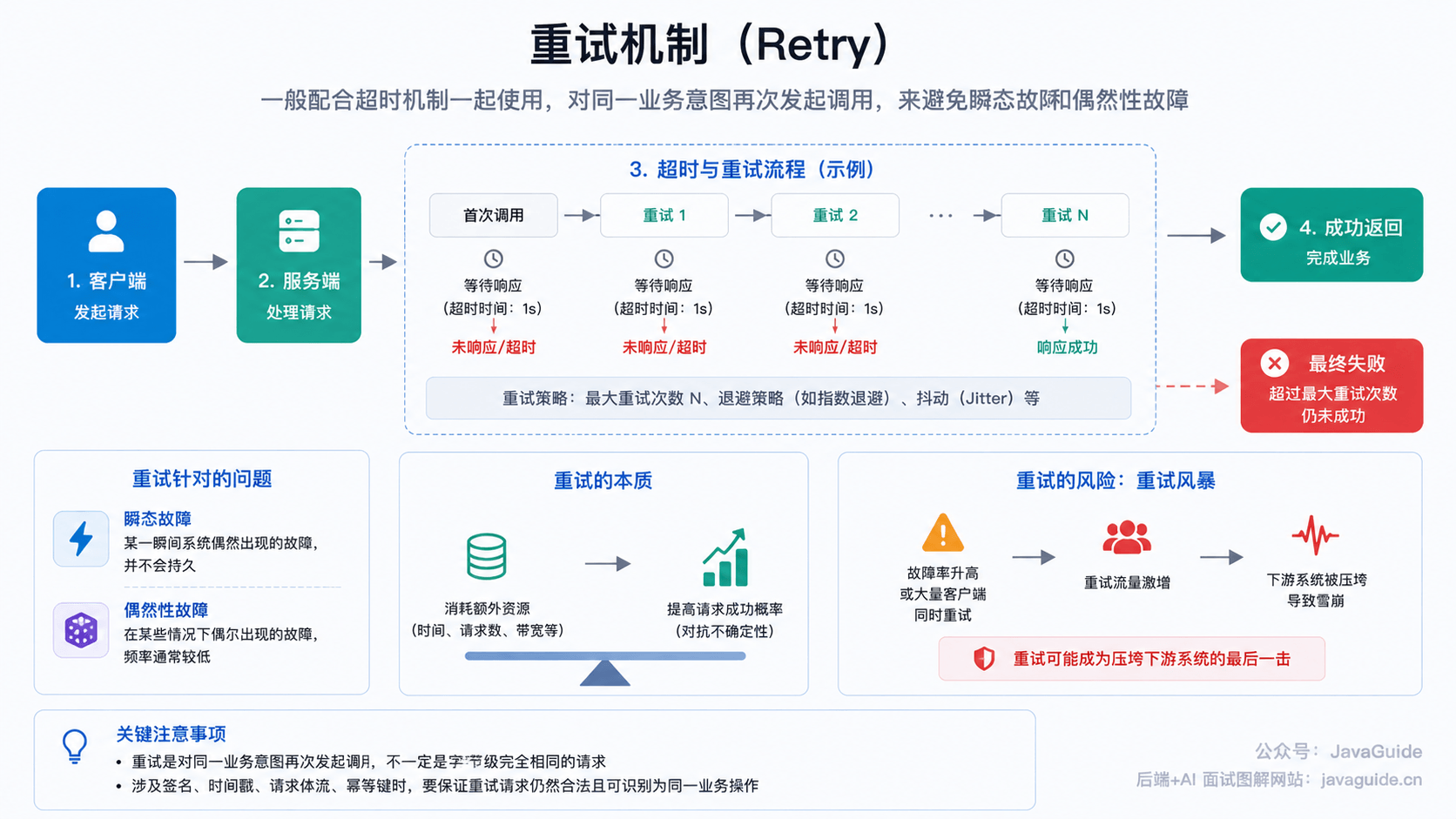
什么是重试机制?
重试机制 一般配合超时机制一起使用,指的是 对同一业务意图再次发起调用,来避免瞬态故障和偶然性故障。
- 瞬态故障:某一瞬间系统偶然出现的故障,并不会持久。
- 偶然性故障:在某些情况下偶尔出现的故障,频率通常较低。
重试是对同一业务意图再次发起调用,它不一定是字节级完全相同的请求。因此涉及签名、时间戳、请求体流、幂等键时,要保证重试请求仍然合法且可识别为同一业务操作。
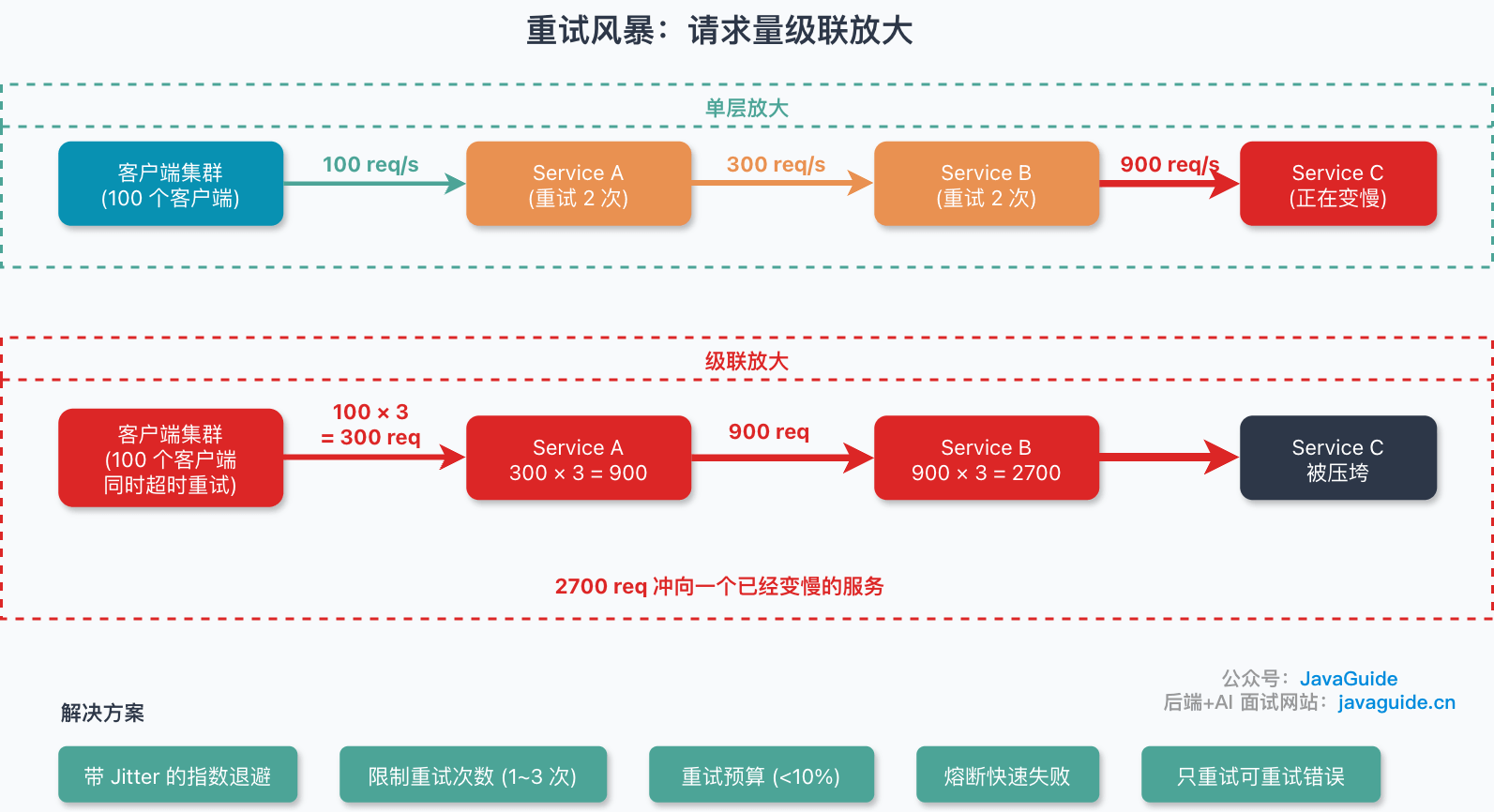
重试的核心思想是 通过消耗额外资源来尽可能提高请求被成功处理的概率。在瞬态故障频率很低、客户端数量有限的场景下,重试带来的额外负载通常可控;但当故障率升高或大量客户端同时触发重试时,重试流量可能成为压垮下游系统的最后一击,也就是后文要讨论的 重试风暴。
常见的重试策略有哪些?
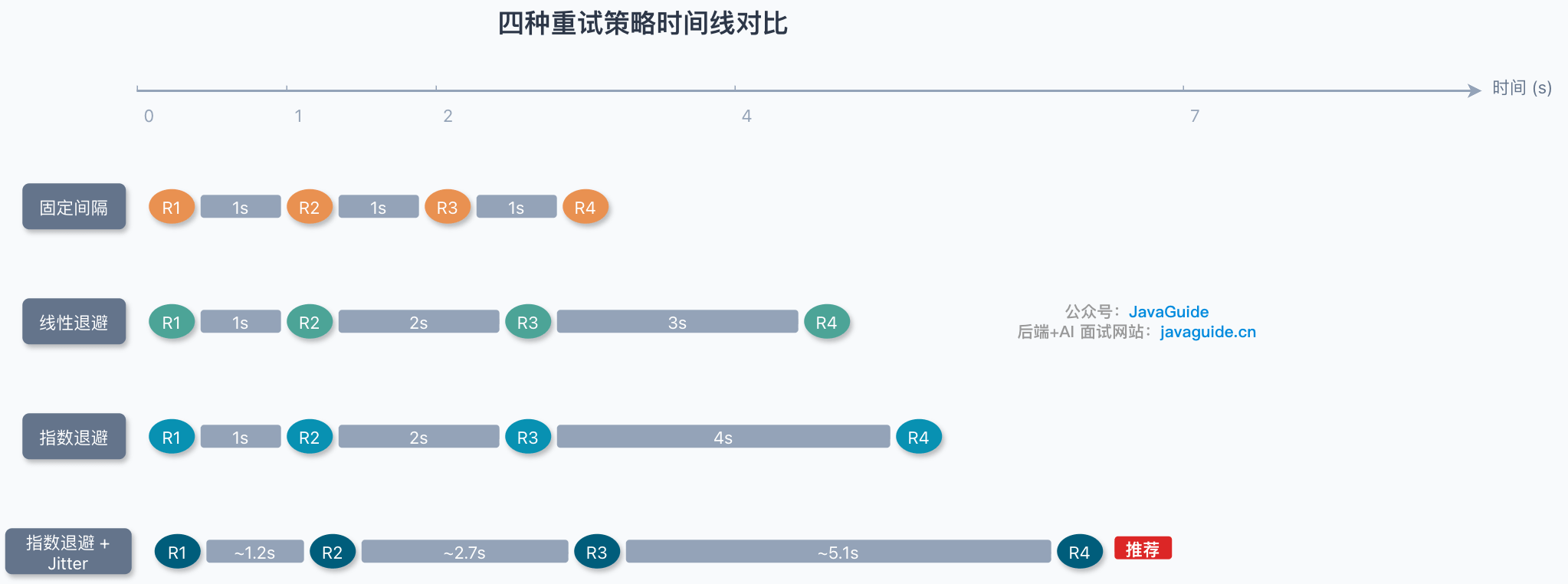
常见的重试策略对比如下:
| 策略 | 说明 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 固定间隔重试 | 每次重试间隔相同(如每隔 1s) | 实现简单 | 可能造成重试风暴 | 目标系统恢复时间稳定可预测 |
| 线性退避重试 | 间隔线性增长(如 1s、2s、3s) | 比固定间隔更温和 | 增长速度较慢 | 一般场景 |
| 指数退避重试 | 间隔指数增长(如 1s、2s、4s、8s) | 比固定间隔更温和 | 多客户端仍可能同步重试,等待时间可能过长 | 目标系统恢复时间较长或不可预测 |
| 带 Jitter 的指数退避 | 指数退避基础上加随机抖动 | 避免多个客户端同时重试 | 实现稍复杂 | 分布式系统推荐 |
分布式系统里通常优先使用带 Jitter 的指数退避策略。Jitter 的具体实现可以是 full jitter(完全随机)、equal jitter(等分抖动)或 decorrelated jitter(去相关抖动),目标都是打散多个客户端的同步重试。
重试的次数如何设置?
重试的次数不宜过多,否则依然会对系统负载造成比较大的压力。
在线同步请求的重试次数通常要很克制,常见是 1~3 次。比如说我们要重试 3 次的话:
- 第 1 次请求失败后,等待 1 秒再进行重试
- 第 2 次请求失败后,等待 2 秒再进行重试
- 第 3 次请求失败后,等待 4 秒再进行重试
异步任务或 MQ 消费可以更多,但必须配合退避、最大重试次数、死信队列、告警和人工补偿。
重试次数不是越多越好。假设读取超时为 1.5s,重试 3 次,并使用 1s、2s、4s 的指数退避,最坏情况下总耗时约为 1.5s × 4 + 1s + 2s + 4s = 13s。对于在线请求,这个尾部延迟可能已经不可接受。因此,读操作可以相对积极地重试,写操作必须配合幂等设计,非关键链路也可以选择快速失败。
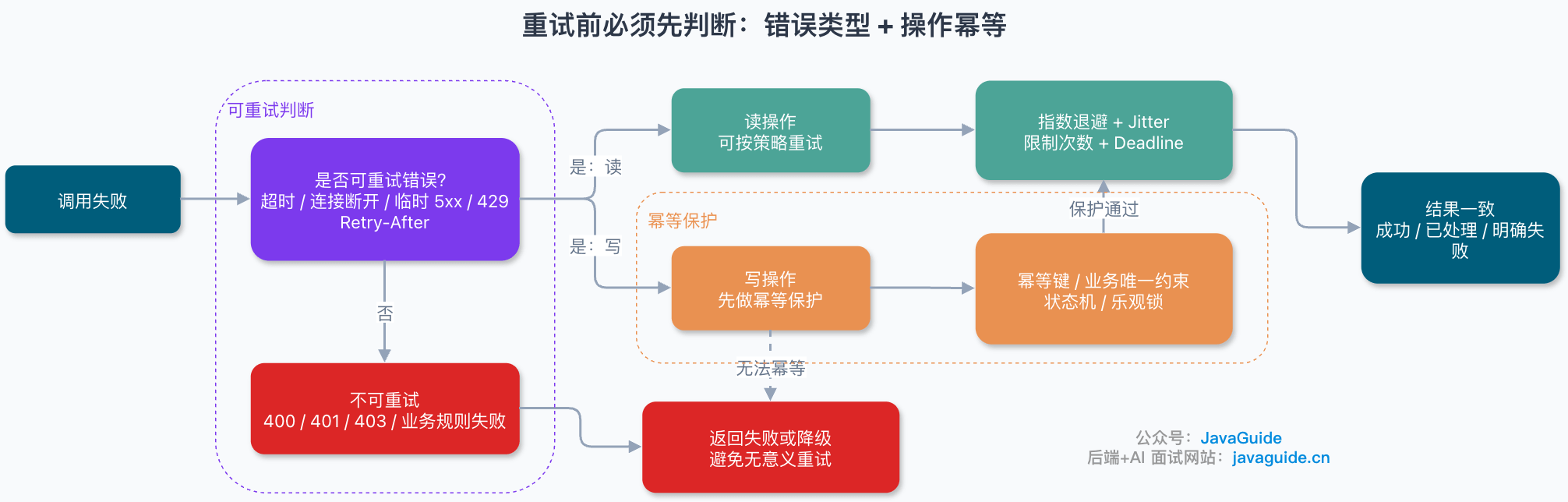
只重试可重试错误
重试落地最关键的一步是 区分可重试错误和不可重试错误。盲目重试会浪费资源甚至加剧问题:
| 分类 | 典型场景 | 处理方式 |
|---|---|---|
| 可重试 | 连接超时、读超时、连接重置、临时 502/503/504 | 配合退避策略重试 |
| 可重试 | 限流后带 Retry-After 响应头的 429 | 按 Retry-After 等待后重试 |
| 谨慎重试 | 支付、下单、库存扣减、发券等写操作 | 必须有幂等键或业务唯一约束 |
| 不应重试 | 参数错误(400)、权限失败(401/403)、业务规则失败 | 直接返回错误 |
| 不应重试 | 余额不足、库存不足等业务异常 | 直接返回错误 |
一般只重试超时、连接断开、临时 5xx、限流后明确允许重试的响应;不要重试参数校验失败、权限失败、业务规则失败、明确的 4xx,以及无法保证幂等的写操作。
重试的风险有哪些?
重试机制虽然能提高系统的可用性,但使用不当也会带来风险:
| 风险 | 说明 | 规避方法 |
|---|---|---|
| 重试风暴 | 大量客户端同时重试,进一步压垮下游服务 | 使用带 Jitter 的指数退避策略 |
| 雪崩效应 | 重试导致上游服务也开始超时重试,形成连锁反应 | 设置重试预算、熔断机制 |
| 重复操作 | 非幂等操作被重复执行,导致数据不一致 | 确保操作幂等性 |
| 资源浪费 | 对永久性故障进行无意义的重试 | 区分可重试错误和不可重试错误 |
重试预算(Retry Budget) 是一种有效的规避策略:限制在一定时间窗口内的重试次数占总请求数的比例,如不超过 10%。落地时可以按调用方、接口或下游维度统计原始请求数和重试请求数,当重试比例超过预算时,后续请求快速失败或只允许首试,不再重试。
重试为什么必须考虑幂等?
超时和重试机制在实际项目中使用的话,需要注意保证 同一操作执行一次和执行多次对系统状态产生的影响相同,这就是幂等性。去重是防止重复执行,幂等是允许重复请求到达但保证结果一致,二者经常配合使用。
什么情况下会出现一个请求被多次执行呢?客户端等待服务端完成请求超时,但此时服务端已经执行了请求,只是由于短暂的网络波动导致响应在发送给客户端的过程中延迟了。
举个例子:用户支付购买某个课程,结果用户支付的请求由于重试的问题导致用户购买同一门课程支付了两次。对于这种情况,我们在执行用户购买课程的请求的时候需要判断一下用户是否已经购买过。这样的话,就不会因为重试的问题导致重复购买了。
实现幂等的常见方法:
| 方法 | 说明 | 适用场景 |
|---|---|---|
| 唯一请求 ID | 每个请求携带唯一 ID,服务端去重 | 通用场景 |
| 数据库唯一约束 | 利用数据库唯一索引防止重复插入 | 创建类操作 |
| 乐观锁 | 通过版本号控制更新 | 更新类操作 |
| 状态机 | 通过状态流转控制,已处理的状态不再处理 | 订单、支付等场景 |
从 HTTP 语义上看,RFC 9110 定义 PUT、DELETE 以及 safe methods(GET、HEAD、OPTIONS、TRACE)为幂等方法。POST 默认不具备幂等语义,但可以通过幂等键、业务唯一约束等方式实现业务幂等。但协议语义不等于服务端实现一定安全,涉及创建订单、扣款、发券、发消息等副作用操作时,服务端仍然需要显式设计幂等。
Java 中如何实现重试?
如果要手动编写代码实现重试逻辑的话,可以通过 for / while 循环或者递归实现。不过,一般不建议自己动手实现,有很多第三方开源库提供了更完善的重试机制实现:
| 框架 | 特点 | 最新版本 | 适用场景 |
|---|---|---|---|
| Spring Retry | Spring 生态,注解驱动,配置简单 | 2.0.12 | Spring Boot 2.x/3.x 项目 |
| Spring Framework 7 内置重试 | 原生内置 @Retryable,无需额外依赖 | Spring Framework 7 | Spring Boot 4.x 项目 |
| Resilience4j | 轻量级,函数式风格,支持熔断、限流等 | 2.4.0 | 微服务项目 |
| Failsafe | 零依赖,支持异步重试、超时、熔断等 | 3.3.2 | 需要细粒度控制的场景 |
| Guava Retrying | 灵活的重试策略配置 | 2.0.0 | 通用 Java 项目(⚠️ 已长期停更,非 Guava 官方核心模块,使用前需评估维护状态) |
Spring Retry 示例
使用 Spring Retry 的简单示例:
@Configuration
@EnableRetry
public class RetryConfig {
}
@Retryable(
retryFor = {RestClientException.class},
maxAttempts = 3,
backoff = @Backoff(delay = 1000, multiplier = 2)
)
public String callRemoteService(String requestId) {
return remoteClient.call(requestId);
}
@Recover
public String recover(RestClientException e, String requestId) {
// 重试耗尽后的兜底逻辑
return "fallback";
}
@Recover 的第一个参数为异常类型,后续参数与 @Retryable 方法参数一致,Spring Retry 通过参数类型匹配恢复方法。
需要注意的是:
@Retryable基于 Spring AOP 代理,同一个类内部通过this.method()调用不会触发重试,必须通过 Spring 管理的代理对象调用。- Spring Boot 3.x / Spring Framework 6 体系下,优先确认 Spring Retry 2.x 与项目 Spring 版本、Java 17+ 版本的兼容性,不要混用旧版。
- Spring Boot 4.x / Spring Framework 7 开始,重试能力已内置到
spring-core中,使用@EnableResilientMethods激活,无需额外引入spring-retry依赖。Spring Retry 项目已进入维护模式(maintenance only),不再接受新特性。
Resilience4j Retry 示例
RetryConfig config = RetryConfig.custom()
.maxAttempts(3)
.waitDuration(Duration.ofMillis(1000))
.retryOnException(e -> e instanceof SocketTimeoutException
|| e instanceof ConnectException)
.ignoreExceptions(BusinessException.class, AuthException.class)
.intervalFunction(IntervalFunction.ofExponentialBackoff(1000, 2))
.build();
Retry retry = Retry.of("remoteService", config);
// 获取重试事件用于监控
retry.getEventPublisher()
.onRetry(event -> log.warn("Retry attempt {}", event.getNumberOfRetryAttempts()));
String result = Retry.decorateSupplier(retry, () -> remoteClient.call(requestId))
.get();
当 Retry 与 CircuitBreaker 组合使用时,要注意装饰器的顺序影响统计口径:Retry.decorateSupplier(CircuitBreaker.decorateSupplier(supplier)) 意味着重试成功不会打开熔断器,而反过来包装则每次重试都经过熔断器统计。
线上观测指标
超时和重试上线后必须靠指标验证,否则很难发现重试风暴等问题。以下是关键的观测指标:
| 指标类别 | 具体指标 |
|---|---|
| 请求量 | 原始请求 QPS、重试请求 QPS、重试比例 |
| 延迟 | P99 / P999 延迟、超时率 |
| 成功率 | 最终成功率、首次成功率 |
| 下游健康 | 下游 5xx 数量、限流次数、熔断器状态 |
| 资源 | 线程池队列深度、连接池等待时间、活跃连接数 |
| 重试预算 | Retry Budget 消耗比例 |
参考
- 微服务之间调用超时的设置治理:https://www.infoq.cn/article/eyrslar53l6hjm5yjgyx
- 超时、重试和抖动回退(AWS Builders Library):https://aws.amazon.com/cn/builders-library/timeouts-retries-and-backoff-with-jitter/
- AWS Architecture Blog - Exponential Backoff and Jitter:https://aws.amazon.com/blogs/architecture/exponential-backoff-and-jitter/
- RFC 9110 - HTTP Semantics:https://www.rfc-editor.org/rfc/rfc9110