High Performance Convolution Bloom On Unity
April 30, 2025 · View on GitHub
This project implements a high-quality bloom effect using Fast Fourier Transform (FFT) convolution, Providing customizable bloom effects with optimized performance. It achieves performance parity with Unreal Engine’s convolution bloom effect while offering greater flexibility and additional optimization options.
Unity Version: 2022.3.8f1c1
Blog: https://zhuanlan.zhihu.com/p/1900864922390343758


Convolution Benchmark
The performance testing of Convolution was conducted using the Unity Profiler, recording GPU Profiler timings.
The testing process involved executing 20 convolution per frame, calculating the average time for per-convolution. Kernel FFT is not included.
Read/Write Texture format ARGBHalf.
Device: NVIDIA GeForce MX450.
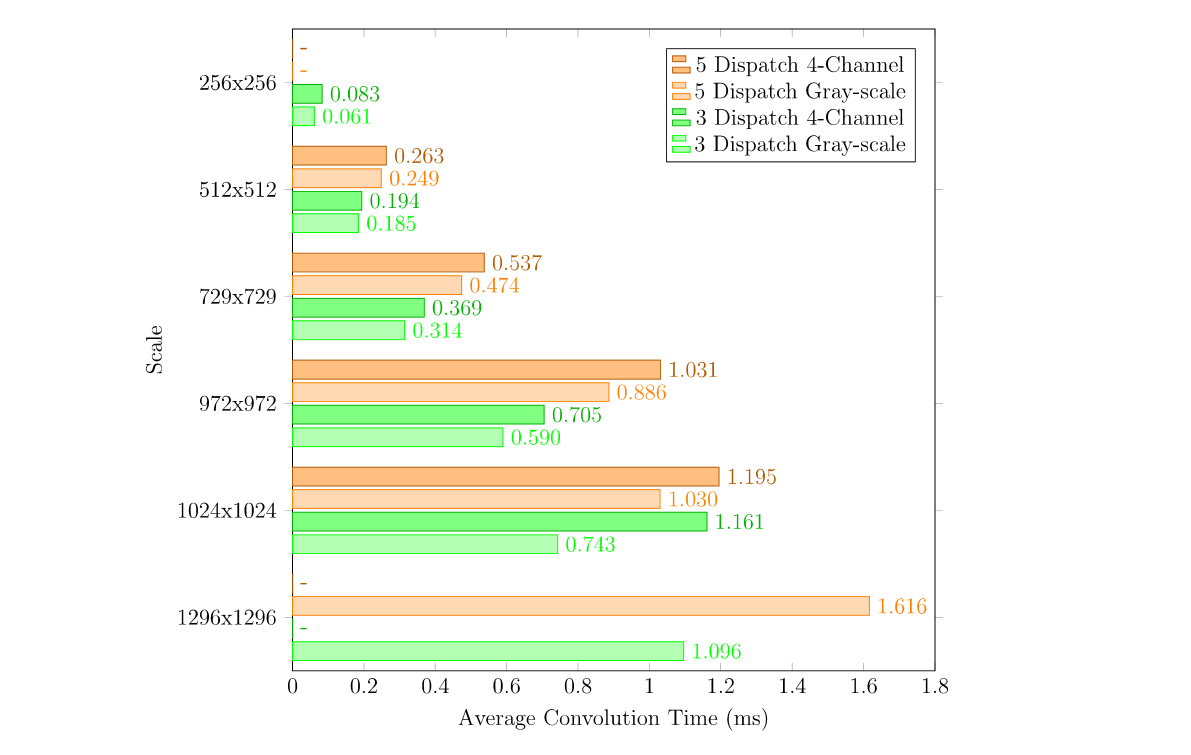
Dispatch Merge Performance Comparison
| Scale | Strategy | Mode | Average Horizontal FFT (ms) | Average Vertical FFT + Mul (ms) | Average Convolution (ms) |
|---|---|---|---|---|---|
| 1296x1296 | 9,6,6,4 inplace | Gray-scale | 1.151 | 0.465 | 1.616 |
| 1024x1024 | 16,16,4 inplace | Gray-scale | 0.781 | 0.249 | 1.030 |
| 1024x1024 | 16,16,4 inplace | 4-Channel | 0.779 | 0.415 | 1.195 |
| 972x972 | 9,3,6,6 inplace | Gray-scale | 0.663 | 0.223 | 0.886 |
| 972x972 | 9,3,6,6 inplace | 4-Channel | 0.664 | 0.367 | 1.031 |
| 729x729 | 9,9,9 inplace | Gray-scale | 0.373 | 0.101 | 0.474 |
| 729x729 | 9,9,9 inplace | 4-Channel | 0.369 | 0.169 | 0.537 |
| 512x512 | 8,8,8 inplace | Gray-scale | 0.202 | 0.046 | 0.249 |
| 512x512 | 8,8,8 inplace | 4-Channel | 0.200 | 0.063 | 0.263 |
In cases where "inplace !" is used, padding optimization cannot be performed during the merged convolution operation due to the limitations of group shared memory size.
| Scale | Strategy | Mode | Average Horizontal FFT (ms) | Average Vertical FFT + Mul (ms) | Average Convolution (ms) | Ratio |
|---|---|---|---|---|---|---|
| 1296x1296 | 9,6,6,4 inplace | Gray-scale | 0.598 | 0.498 | 1.096 | 68% |
| 1024x1024 | 16,16,4 inplace | Gray-scale | 0.400 | 0.343 | 0.743 | 72% |
| 1024x1024 | 16,16,4 inplace ! | 4-Channel | 0.393 | 0.768 | 1.161 | 97% |
| 972x972 | 9,3,6,6 inplace | Gray-scale | 0.318 | 0.273 | 0.590 | 67% |
| 972x972 | 9,3,6,6 inplace | 4-Channel | 0.339 | 0.365 | 0.705 | 68% |
| 729x729 | 9,9,9 inplace | Gray-scale | 0.192 | 0.121 | 0.314 | 66% |
| 729x729 | 9,9,9 inplace | 4-Channel | 0.192 | 0.177 | 0.369 | 69% |
| 512x512 | 8,8,8 inplace | Gray-scale | 0.102 | 0.083 | 0.185 | 75% |
| 512x512 | 8,8,8 inplace | 4-Channel | 0.107 | 0.087 | 0.194 | 74% |
| 256x256 | 16,16 outplace | Gray-scale | 0.041 | 0.021 | 0.061 | - |
| 256x256 | 16,16 outplace & inplace | 4-Channel | 0.033 | 0.050 | 0.083 | - |
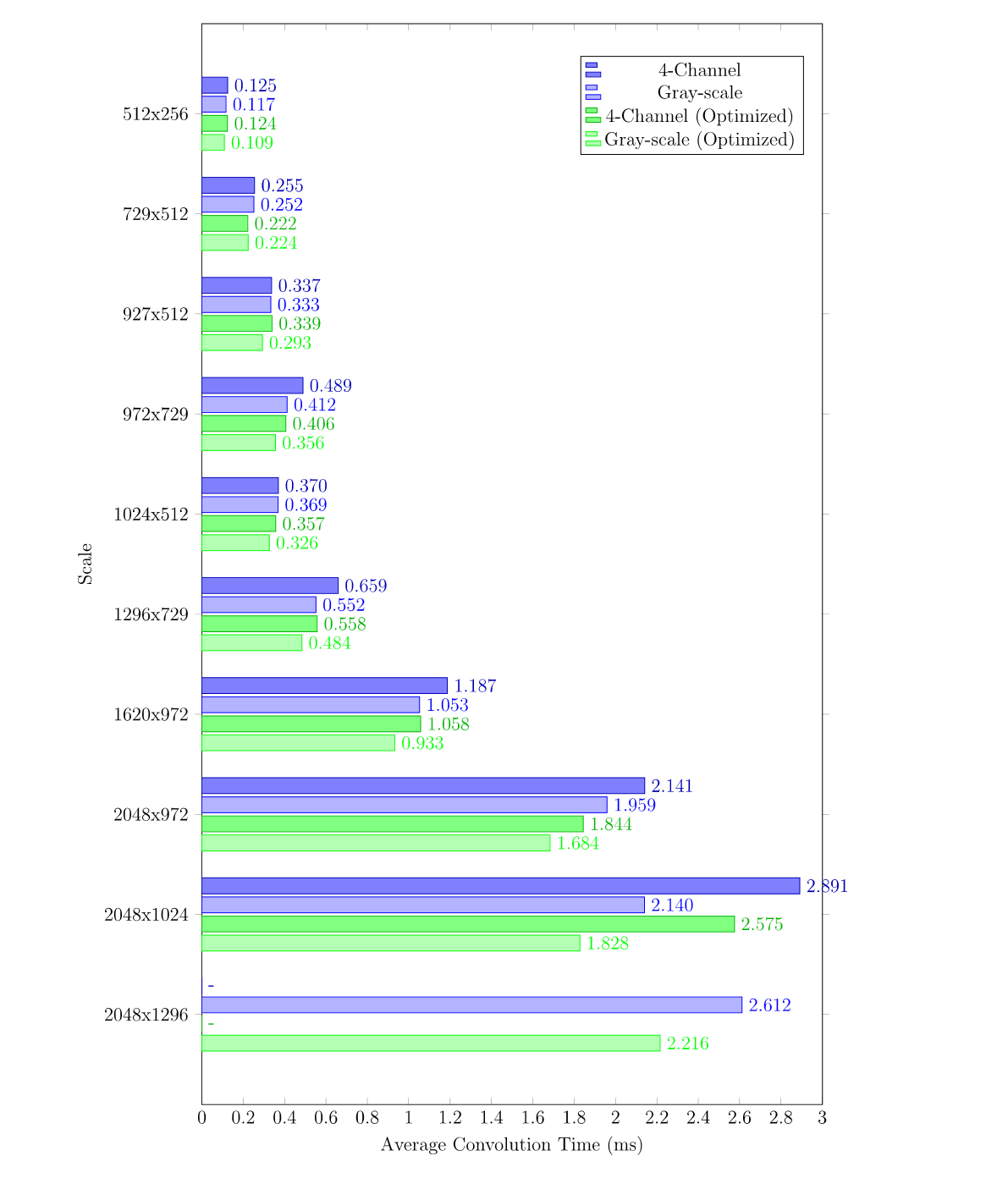
Common Configuration
Below are performance test results for screen ratios closer to rectangular shapes. The second set of data reflects the results of a optimization for 20% vertical length padding. Since the size of the padding needs to be customized based on the shape of the convolution kernel, the "Optimized" results are for reference only.
| Scale | Mode | Convolution Average(ms) | Convolution(20% Padding Optimization) Average(ms) | Ratio |
|---|---|---|---|---|
| 512x256 | Gray-scale | 0.117 | 0.109 | 93% |
| 512x256 | 4-Channel | 0.125 | 0.124 | 99% |
| 729x512 | Gray-scale | 0.252 | 0.224 | 89% |
| 729x512 | 4-Channel | 0.255 | 0.222 | 87% |
| 927x512 | Gray-scale | 0.333 | 0.293 | 88% |
| 927x512 | 4-Channel | 0.337 | 0.339 | 101% |
| 972x729 | Gray-scale | 0.412 | 0.356 | 86% |
| 972x729 | 4-Channel | 0.489 | 0.406 | 83% |
| 1024x512 | Gray-scale | 0.369 | 0.326 | 88% |
| 1024x512 | 4-Channel | 0.370 | 0.357 | 97% |
| 1296x729 | Gray-scale | 0.552 | 0.484 | 88% |
| 1296x729 | 4-Channel | 0.659 | 0.558 | 85% |
| 1620x972 | Gray-scale | 1.053 | 0.933 | 89% |
| 1620x972 | 4-Channel | 1.187 | 1.058 | 89% |
| 2048x972 | Gray-scale | 1.959 | 1.684 | 86% |
| 2048x972 | 4-Channel | 2.141 | 1.844 | 86% |
| 2048x1024 | Gray-scale | 2.140 | 1.828 | 85% |
| 2048x1024 | 4-Channel | 2.891 | 2.575 | 89% |
| 2048x1296 | Gray-scale | 2.612 | 2.216 | 85% |
Note: The performance of Unity default bloom is 0.164ms on my device.
FFT Benchmark
- Strategies such as R8+R2 represent shorthand for a combination of Radix-8 and Radix-2 decomposition strategies.
- R/W Only refers to the read and write overhead of global memory (RWTexture) and group shared memory.
- Combinations marked with in the table indicate internal decomposition optimizations.
- (pad) denotes padding and remapping of indices for group shared memory.
- Padding for group shared memory involves inserting an empty element every $15$ elements.
- (permute) indicates task reordering for threads.
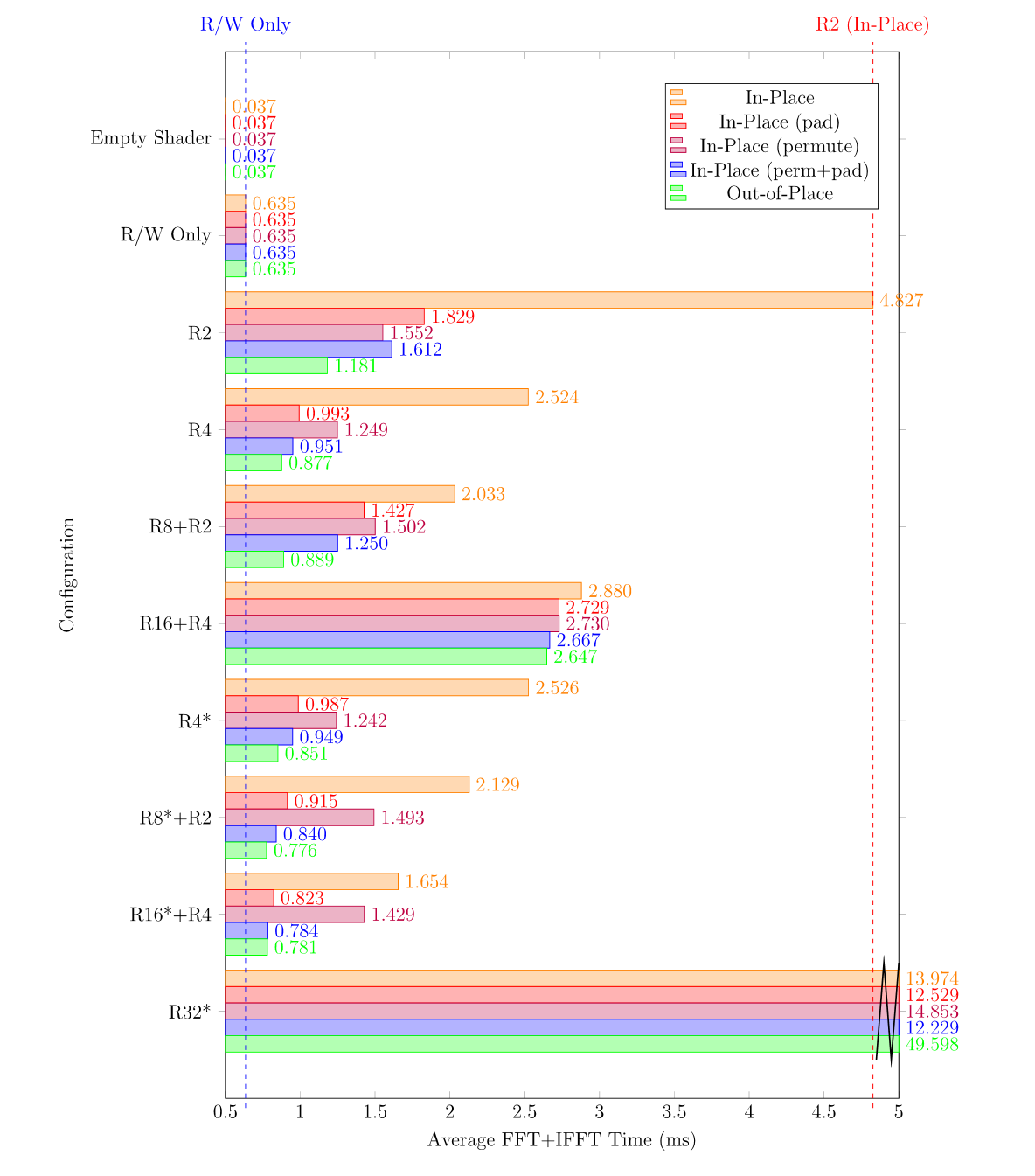
1024x1024
The table and figure below shows the performance test results for a $1024 \times 1024$ image under different combinations.
| Decomposition Strategy | Pass | Memory Access Strategy | Total Shader Time (ms) | Average FFT+IFFT Time (ms) | Average Single-Channel FFT Time (ms) | Average FFT+IFFT Computation Time (ms) | Normalized Time |
|---|---|---|---|---|---|---|---|
| Empty | - | 0.730 | 0.037 | 0.005 | - | 3.481 | |
| R/W Only | - | 12.704 | 0.635 | 0.079 | - | 60.577 | |
| R2 | 10 | Out-of-Place | 23.628 | 1.181 | 0.148 | 0.546 | 112.667 |
| R4 | 5 | Out-of-Place | 17.549 | 0.877 | 0.110 | 0.242 | 83.680 |
| R8+R2 | 4 | Out-of-Place | 17.775 | 0.889 | 0.111 | 0.254 | 84.758 |
| R16+R4 | 3 | Out-of-Place | 52.931 | 2.647 | 0.331 | 2.011 | 252.395 |
| R4* | 5 | Out-of-Place | 17.023 | 0.851 | 0.106 | 0.216 | 81.172 |
| R8*+R2 | 4 | Out-of-Place | 15.510 | 0.776 | 0.097 | 0.140 | 73.957 |
| R16+R4 | 3 | Out-of-Place | 15.625 | 0.781 | 0.098 | 0.146 | 74.506 |
| R32* | 2 | Out-of-Place | 991.962 | 49.598 | 6.200 | 48.963 | 4730.043 |
| R2 | 10 | In-Place | 96.542 | 4.827 | 0.603 | 4.192 | 460.348 |
| R4 | 5 | In-Place | 50.474 | 2.524 | 0.315 | 1.889 | 240.679 |
| R8+R2 | 4 | In-Place | 40.667 | 2.033 | 0.254 | 1.398 | 193.915 |
| R16+R4 | 3 | In-Place | 57.606 | 2.880 | 0.360 | 2.245 | 274.687 |
| R4* | 5 | In-Place | 50.523 | 2.526 | 0.316 | 1.891 | 240.912 |
| R8*+R2 | 4 | In-Place | 42.585 | 2.129 | 0.266 | 1.494 | 203.061 |
| R16*+R4 | 3 | In-Place | 33.072 | 1.654 | 0.207 | 1.018 | 157.700 |
| R32* | 2 | In-Place | 279.489 | 13.974 | 1.747 | 13.339 | 1332.707 |
| R2 | 10 | In-Place(pad) | 36.572 | 1.829 | 0.229 | 1.193 | 174.389 |
| R4 | 5 | In-Place(pad) | 19.863 | 0.993 | 0.124 | 0.358 | 94.714 |
| R8+R2 | 4 | In-Place(pad) | 28.530 | 1.427 | 0.178 | 0.791 | 136.042 |
| R16+R4 | 3 | In-Place(pad) | 54.577 | 2.729 | 0.341 | 2.094 | 260.243 |
| R4* | 5 | In-Place(pad) | 19.749 | 0.987 | 0.123 | 0.352 | 94.171 |
| R8*+R2 | 4 | In-Place(pad) | 18.307 | 0.915 | 0.114 | 0.280 | 87.295 |
| R16*+R4 | 3 | In-Place(pad) | 16.458 | 0.823 | 0.103 | 0.188 | 78.478 |
| R32* | 2 | In-Place(pad) | 250.572 | 12.529 | 1.566 | 11.893 | 1194.820 |
| R2 | 10 | In-Place(perm) | 31.037 | 1.552 | 0.194 | 0.917 | 147.996 |
| R4 | 5 | In-Place(perm) | 24.977 | 1.249 | 0.156 | 0.614 | 119.100 |
| R8+R2 | 4 | In-Place(perm) | 30.036 | 1.502 | 0.188 | 0.867 | 143.223 |
| R16+R4 | 3 | In-Place(perm) | 54.603 | 2.730 | 0.341 | 2.095 | 260.367 |
| R4* | 5 | In-Place(perm) | 24.848 | 1.242 | 0.155 | 0.607 | 118.484 |
| R8*+R2 | 4 | In-Place(perm) | 29.859 | 1.493 | 0.187 | 0.858 | 142.379 |
| R16*+R4 | 3 | In-Place(perm) | 28.573 | 1.429 | 0.179 | 0.793 | 136.247 |
| R32* | 2 | In-Place(perm) | 297.053 | 14.853 | 1.857 | 14.217 | 1416.459 |
| R2 | 10 | In-Place(perm+pad) | 32.239 | 1.612 | 0.201 | 0.977 | 153.728 |
| R4 | 5 | In-Place(perm+pad) | 19.028 | 0.951 | 0.119 | 0.316 | 90.733 |
| R8+R2 | 4 | In-Place(perm+pad) | 25.001 | 1.250 | 0.156 | 0.615 | 119.214 |
| R16+R4 | 3 | In-Place(perm+pad) | 53.336 | 2.667 | 0.333 | 2.032 | 254.326 |
| R4* | 5 | In-Place(perm+pad) | 18.977 | 0.949 | 0.119 | 0.314 | 90.489 |
| R8*+R2 | 4 | In-Place(perm+pad) | 16.808 | 0.840 | 0.105 | 0.205 | 80.147 |
| R16*+R4 | 3 | In-Place(perm+pad) | 15.672 | 0.784 | 0.098 | 0.148 | 74.730 |
| R32* | 2 | In-Place(perm+pad) | 244.572 | 12.229 | 1.529 | 11.593 | 1166.210 |
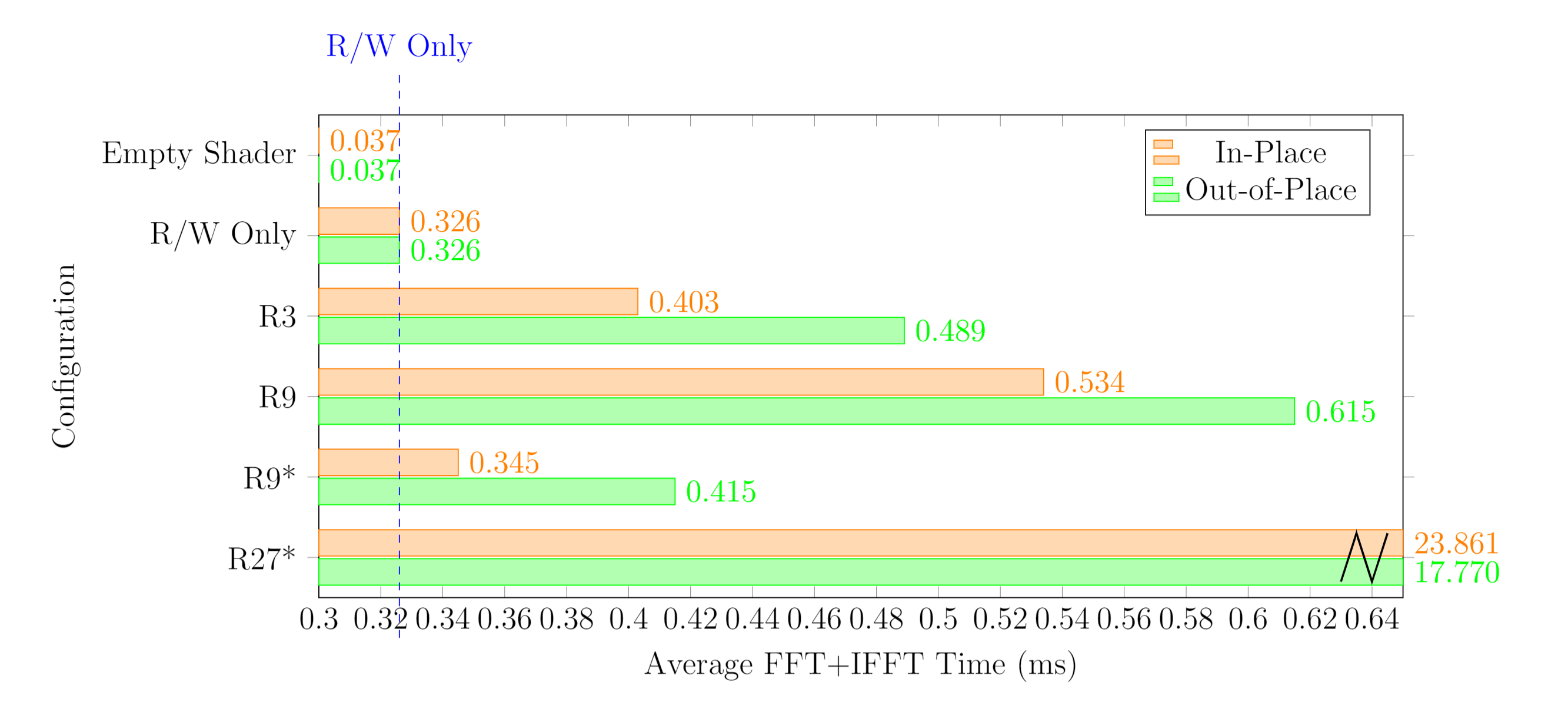
729x729
($3^6 = 729$)
| Decomposition Strategy | Pass | Memory Access Strategy | Total Shader Time (ms) | Average FFT+IFFT Time (ms) | Average Single-Channel FFT Time (ms) | Average FFT+IFFT Computation Time (ms) | Normalized Time |
|---|---|---|---|---|---|---|---|
| Empty | - | 0.730 | 0.037 | 0.005 | - | 7.222 | |
| R/W Only | - | 6.522 | 0.326 | 0.041 | - | 64.525 | |
| R3 | 6 | Out-of-Place | 9.787 | 0.489 | 0.061 | 0.163 | 96.827 |
| R9 | 3 | Out-of-Place | 12.301 | 0.615 | 0.077 | 0.289 | 121.698 |
| R9* | 3 | Out-of-Place | 8.304 | 0.415 | 0.052 | 0.089 | 82.155 |
| R27* | 2 | Out-of-Place | 355.409 | 17.770 | 2.221 | 17.444 | 3516.196 |
| R3 | 6 | In-Place | 8.053 | 0.403 | 0.050 | 0.077 | 79.671 |
| R9 | 3 | In-Place | 10.671 | 0.534 | 0.067 | 0.207 | 105.572 |
| R9* | 3 | In-Place | 6.909 | 0.345 | 0.043 | 0.019 | 68.353 |
| R27* | 2 | In-Place | 477.22 | 23.861 | 2.983 | 23.535 | 4721.319 |
972x972
For a $972 \times 972 image size, since \972 = \times $3^{5}$$, the FFT decomposition strategy becomes more complex.
It is worth noting that the Out-of-Place FFT shows a significant performance drop when using the R9*+R3+R6* decomposition strategy, which is suspected to be caused by compiler optimization issues.
| Decomposition Strategy | Pass | Memory Access Strategy | Total Shader Time (ms) | Average FFT+IFFT Time (ms) | Average Single-Channel FFT Time (ms) | Average FFT+IFFT Computation Time (ms) | Normalized Time |
|---|---|---|---|---|---|---|---|
| Empty | - | 0.730 | 0.037 | 0.005 | - | 3.893 | |
| R/W Only | - | 11.713 | 0.586 | 0.073 | - | 62.457 | |
| R3+R2 | 7 | Out-of-Place | 18.269 | 0.913 | 0.114 | 0.328 | 97.416 |
| R3+R4* | 6 | Out-of-Place | 16.522 | 0.826 | 0.103 | 0.240 | 88.100 |
| R9*+R3+R4* | 4 | Out-of-Place | 15.226 | 0.761 | 0.095 | 0.176 | 81.190 |
| R9*+R3+R6* | 4 | Out-of-Place | 76.786 | 3.839 | 0.480 | 3.254 | 409.447 |
| R9*+R12* | 3 | Out-of-Place | 13.481 | 0.674 | 0.084 | 0.088 | 71.885 |
| R3+R2* | 7 | In-Place | 19.264 | 0.963 | 0.120 | 0.378 | 102.722 |
| R3+R4* | 6 | In-Place | 16.140 | 0.807 | 0.101 | 0.221 | 86.063 |
| R9*+R3+R4* | 4 | In-Place | 14.871 | 0.744 | 0.093 | 0.158 | 79.297 |
| R9*+R3+R6* | 4 | In-Place | 13.865 | 0.693 | 0.087 | 0.108 | 73.932 |
| R9*+R12* | 3 | In-Place | 12.719 | 0.636 | 0.079 | 0.050 | 67.822 |
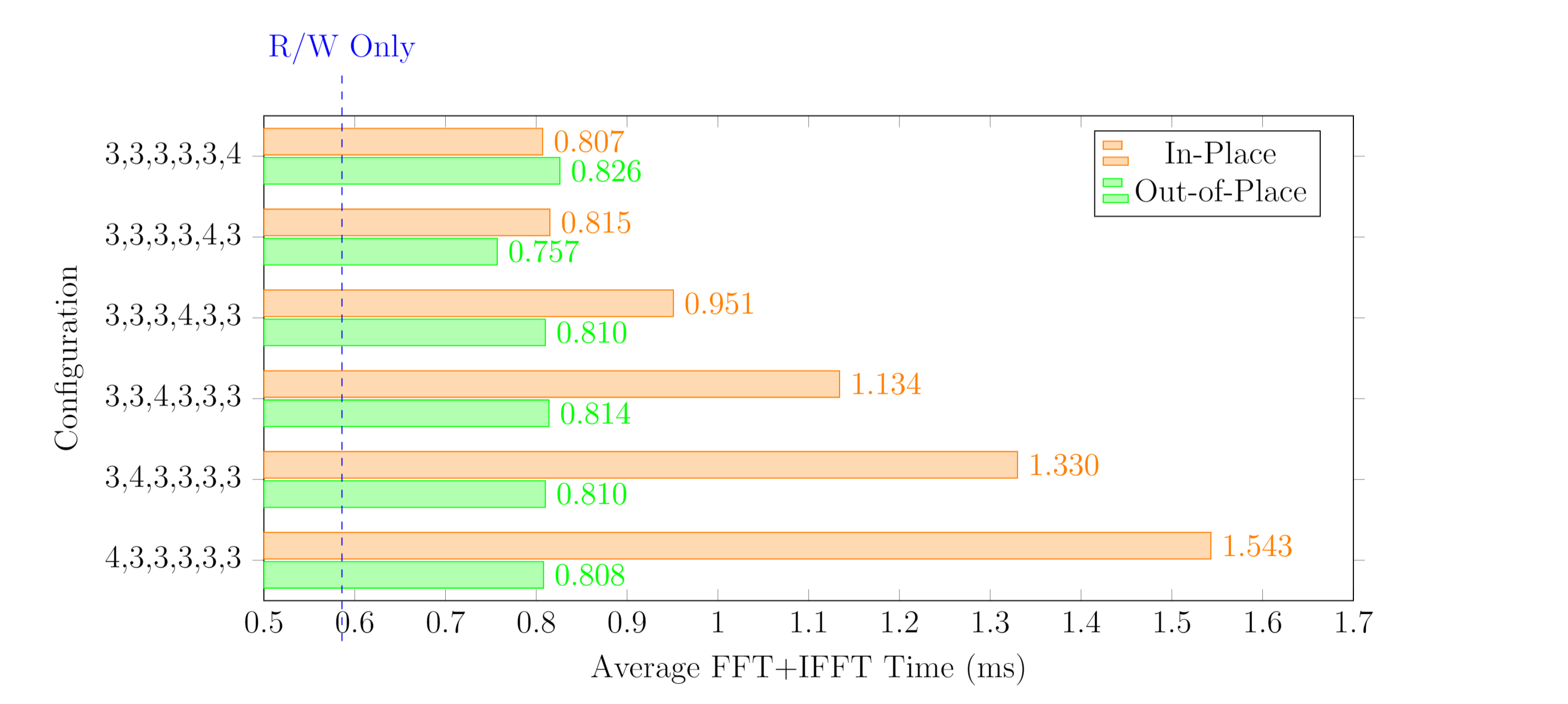
Out-of-Place is relatively stable. Different decomposition orders can lead to changes in memory access patterns, which in turn affect the probability of In-Place Bank Conflict occurrences.
The figure below shows tests for different decomposition orders of the R3 + R4* combination.
It can be observed that as the R4 Pass is moved earlier, the performance of the In-Place FFT gradually decreases. This is because the R4 Pass introduces a memory access pattern with a factor of 2, increasing the probability of Bank Conflicts in subsequent Passes. Therefore, it is recommended to delay the factor of 2 as much as possible in the decomposition strategy.
| Decomposition Strategy | Pass | Memory Access Strategy | Total Shader Time (ms) | Average FFT+IFFT Time (ms) | Average Single-Channel FFT Time (ms) | Average FFT+IFFT Computation Time (ms) | Normalized Time |
|---|---|---|---|---|---|---|---|
| 3,3,3,3,3,4 | 4 | In-Place | 16.140 | 0.807 | 0.101 | 0.221 | 86.063 |
| 3,3,3,3,3,4 | 4 | Out-of-Place | 16.522 | 0.826 | 0.103 | 0.240 | 88.100 |
| 3,3,3,3,4,3 | 4 | In-Place | 16.290 | 0.815 | 0.102 | 0.229 | 86.863 |
| 3,3,3,3,4,3 | 4 | Out-of-Place | 15.143 | 0.757 | 0.095 | 0.172 | 80.747 |
| 3,3,3,4,3,3 | 4 | In-Place | 19.024 | 0.951 | 0.119 | 0.366 | 101.442 |
| 3,3,3,4,3,3 | 4 | Out-of-Place | 16.194 | 0.810 | 0.101 | 0.224 | 86.351 |
| 3,3,4,3,3,3 | 4 | In-Place | 22.677 | 1.134 | 0.142 | 0.548 | 120.921 |
| 3,3,4,3,3,3 | 4 | Out-of-Place | 16.277 | 0.814 | 0.102 | 0.228 | 86.794 |
| 3,4,3,3,3,3 | 4 | In-Place | 26.600 | 1.330 | 0.166 | 0.744 | 141.839 |
| 3,4,3,3,3,3 | 4 | Out-of-Place | 16.209 | 0.810 | 0.101 | 0.225 | 86.431 |
| 4.3,3,3,3,3 | 4 | In-Place | 30.851 | 1.543 | 0.193 | 0.957 | 164.507 |
| 4.3,3,3,3,3 | 4 | Out-of-Place | 16.166 | 0.808 | 0.101 | 0.223 | 86.202 |