Soccer Players Tracking
August 26, 2022 · View on GitHub

In this project, we aim to reconstruct a soccer game's details from the position of the players and referees to their movements using three recorded videos with different field coverage. Subsequently, the movement and position of the individuals are displayed in a top-view demonstration of a 2D soccer pitch. For this project, we used "Soccer video and player position dataset" from this website.
Input data
"Soccer video and player position dataset" provides three videos, each displaying a constant soccer match synchronously from a different perspective.
| Left | Center | Right |
|---|---|---|
 |  |  |
Extracting the background of the inputs
We extract the background of the videos by calculating the mean of all video frames for each pixel.
| Left | Center | Right |
|---|---|---|
 |  |  |
Substracting the background
In this section, the obtained backgrounds are used in a KNN Background Subtraction algorithm to detect moving individuals.

Objects to Patches
The detected objects are converted to patches of variable size and saved in a folder named "img". Moreover, with the help of pigeon.anotate a corresponding label is assigned to all the patches.
| Patches |
|---|
           |
Classifying Individuals
After extracting patches and determining labels, we use two convolution layers following a flatten layer and two fully-connected layers to classify the patches into three classes.
| Blue Team | White Team | Referees |
|---|---|---|
   |     |     |
| Layer (type) | Output Shape |
|---|---|
| conv2d (Conv2D) | (None, 26, 8, 64) |
| max_pooling2d (MaxPooling2D) | (None, 13, 4, 64) |
| conv2d_1 (Conv2D) | (None, 11, 2, 128) |
| max_pooling2d_1 (MaxPooling2) | (None, 5, 1, 128) |
| flatten (Flatten) | (None, 640) |
| dense (Dense) | (None, 128) |
| dense_1 (Dense) | (None, 3) |
Applying Masks
We apply two types of masks for different purposes on the input images.
Region of Interest (ROI)
This mask is used to define the region of interest in the image. Using this mask, we are able to omit the improper regions, like the big monitor in the left video, pitch-side hoardings, and audience.
| Left | Center | Right |
|---|---|---|
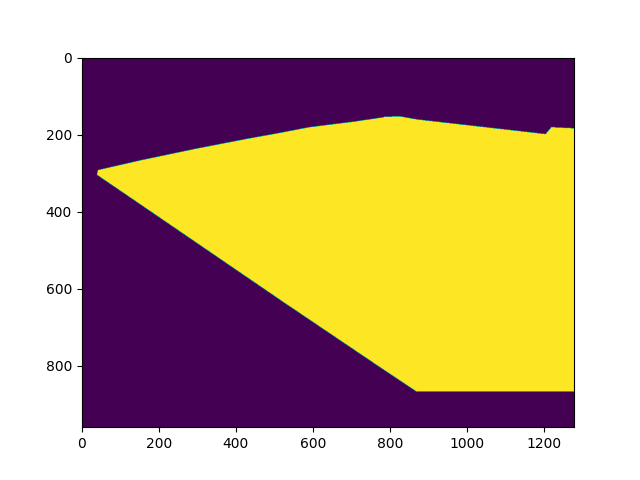 |  | 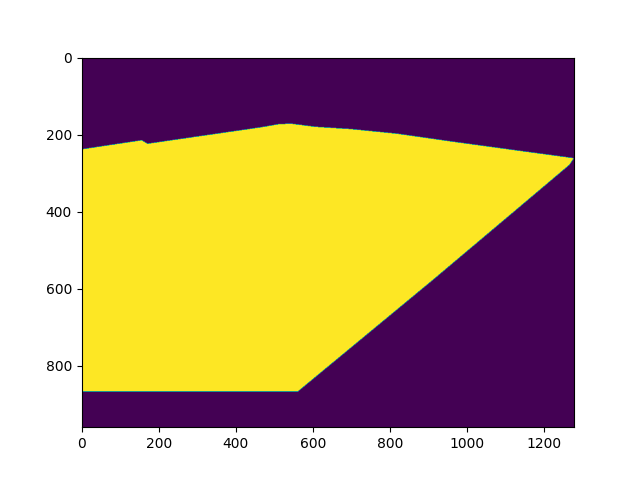 |
Top-view Coverage Area
We used this mask to define a unique top-view area for each input video. By applying this mask, all of the common areas between input videos will be eliminated.
| Left | Center | Right |
|---|---|---|
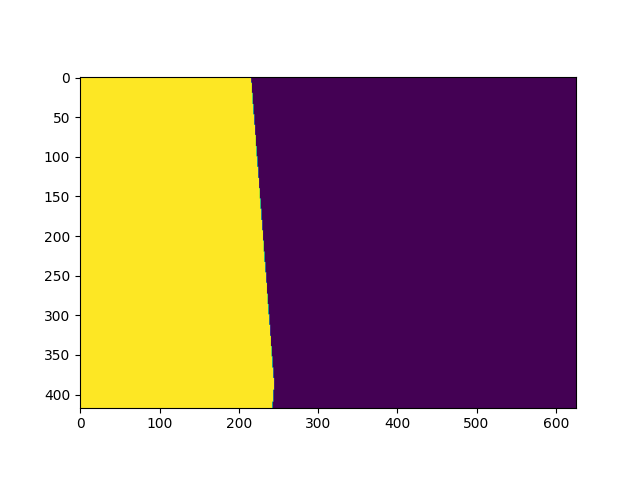 | 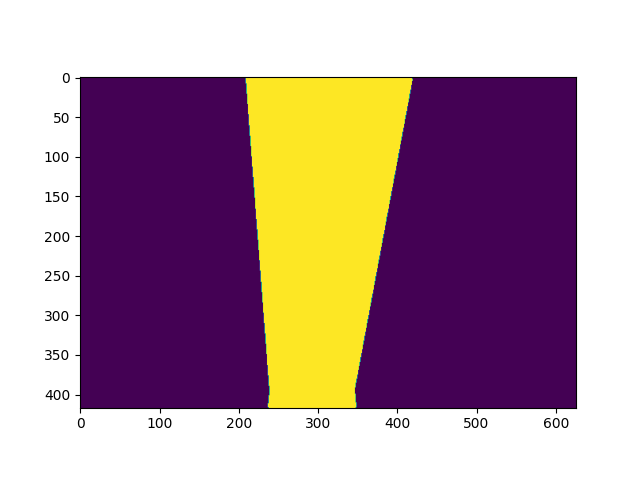 | 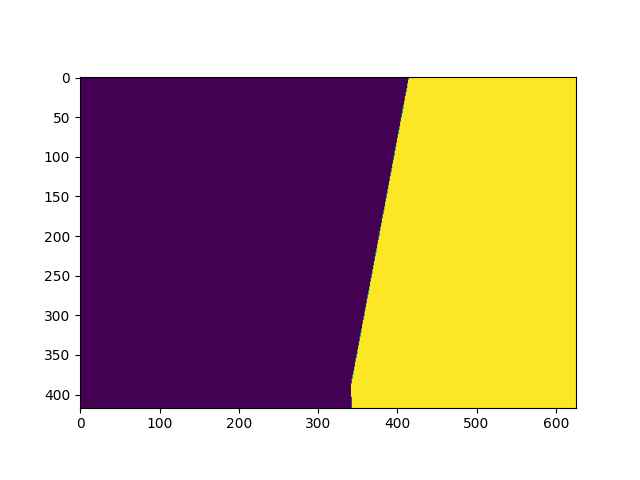 |
Transformation
We transform the masked input videos and their objects to get three complementary top-view presentations.
Final results

References
- S. A. Pettersen, D. Johansen, H. Johansen, V. Berg-Johansen, V. R. Gaddam, A. Mortensen, R. Langseth, C. Griwodz H. K. Stensland, and P. Halvorsen, Soccer video and player position dataset, Proceedings of ACM MMSys 2014, March 19.