In-the-wild Inference
January 3, 2025 · View on GitHub
2D Pose
Please use AlphaPose to extract the 2D keypoints for your video first. We use the Fast Pose model trained on Halpe dataset (Link).
Note: Currently we only support single person. If your video contains multiple person, you may need to use the Pose Tracking Module for AlphaPose and set --focus to specify the target person id.
3D Pose
 | 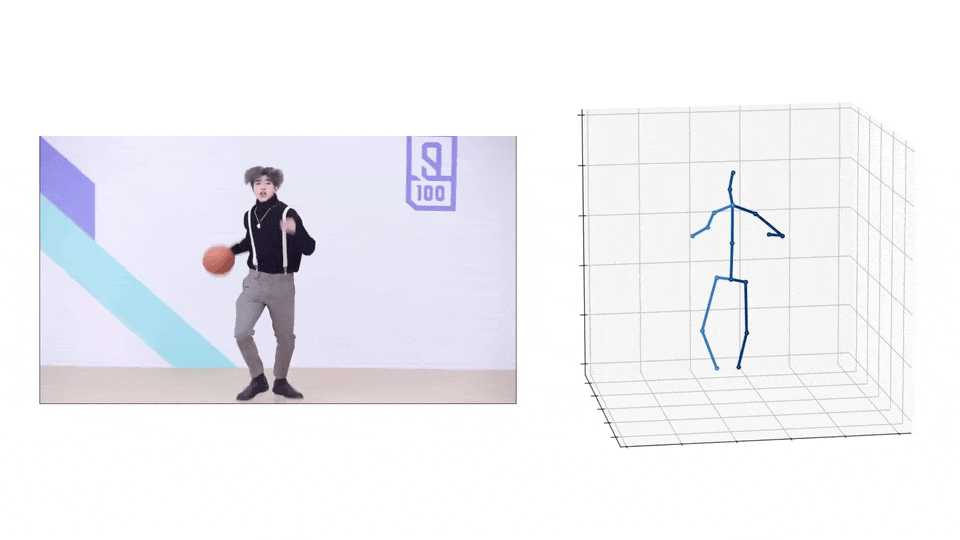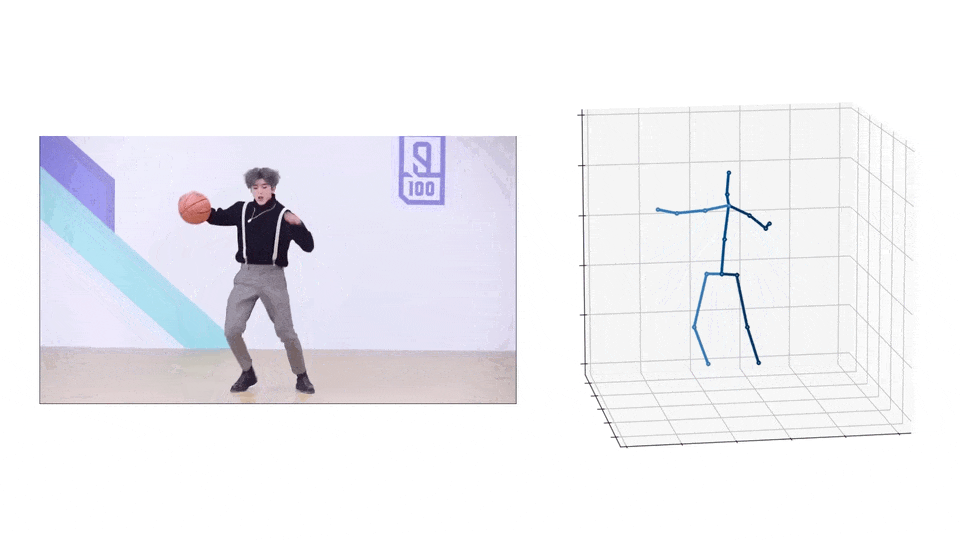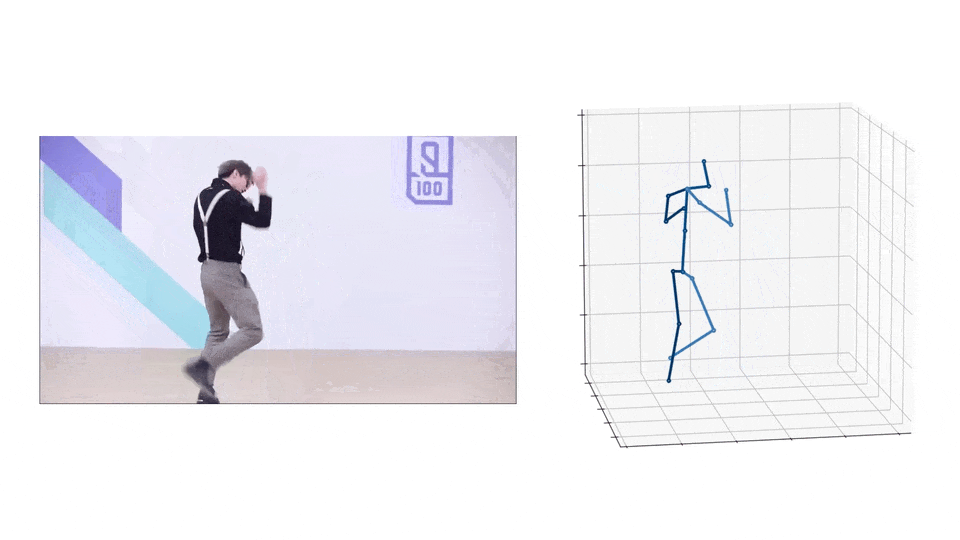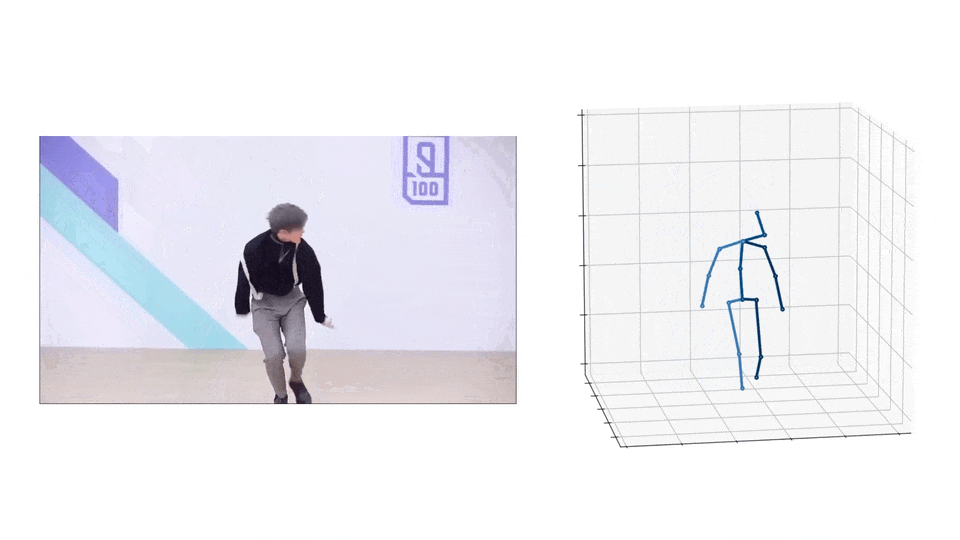 |
|---|
- Please download the checkpoint here and put it to
checkpoint/pose3d/FT_MB_lite_MB_ft_h36m_global_lite/. - Run the following command to infer from the extracted 2D poses:
python infer_wild.py \
--vid_path <your_video.mp4> \
--json_path <alphapose-results.json> \
--out_path <output_path>
Mesh
 |  |
|---|
- Please download the checkpoint here and put it to
checkpoint/mesh/FT_MB_release_MB_ft_pw3d/ - Please prepare data following here.
- Run the following command to infer from the extracted 2D poses:
python infer_wild_mesh.py \
--vid_path <your_video.mp4> \
--json_path <alphapose-results.json> \
--out_path <output_path> \
--ref_3d_motion_path <3d-pose-results.npy> # Optional, use the estimated 3D motion for root trajectory.