Selecting Initial Seeds for Better JVM Fuzzing
August 10, 2024 · View on GitHub
This is the implementation of our ICSE 2025 paper.
I. Introduction
JVM fuzzing techniques serve as a cornerstone for guaranteeing the quality of implementations. In typical fuzzing workflows, initial seeds are crucial as they form the basis of the process. Literature in traditional program fuzzing has confirmed that effectiveness is largely impacted by redundancy among initial seeds, thereby proposing a series of seed selection methods. JVM fuzzing, compared to traditional ones, presents unique characteristics, including large-scale and intricate code, and programs with both syntactic and semantic features. However, it remains unclear whether the existing initial seed selection methods are suitable for JVM fuzzing and whether utilizing program features can enhance effectiveness. To address this, we devised a total of 10 initial seed selection methods, comprising coverage-based, prefuzz-based, and program-feature-based methods. We then conducted an empirical study on three JVM implementations to extensively evaluate the performance of the initial seed selection methods within two state-of-the-art fuzzing techniques (JavaTailor and VECT). Specifically, we examine performance from three aspects: (i) effectiveness and efficiency using widely studied initial seeds, (ii) effectiveness using the programs in the wild, and (iii) the ability to detect new bugs.
Evaluation results first show that the program-feature-based method that utilizes the control flow graph not only has a significantly lower time overhead (i.e., 30s), but also outperforms other methods, achieving 142% to 269% improvement compared to the full set of initial seeds. Second, results reveal that the initial seed selection greatly improves the quality of wild programs and exhibits complementary effectiveness by detecting new behaviors. Third, results demonstrate that given the same testing period, initial seed selection improves the JVM fuzzing techniques by detecting more unknown bugs. Particularly, 16 out of the 25 detected bugs have been confirmed or fixed by developers. This work takes the first look at initial seed selection in JVM fuzzing, confirming its importance in fuzzing effectiveness and efficiency.
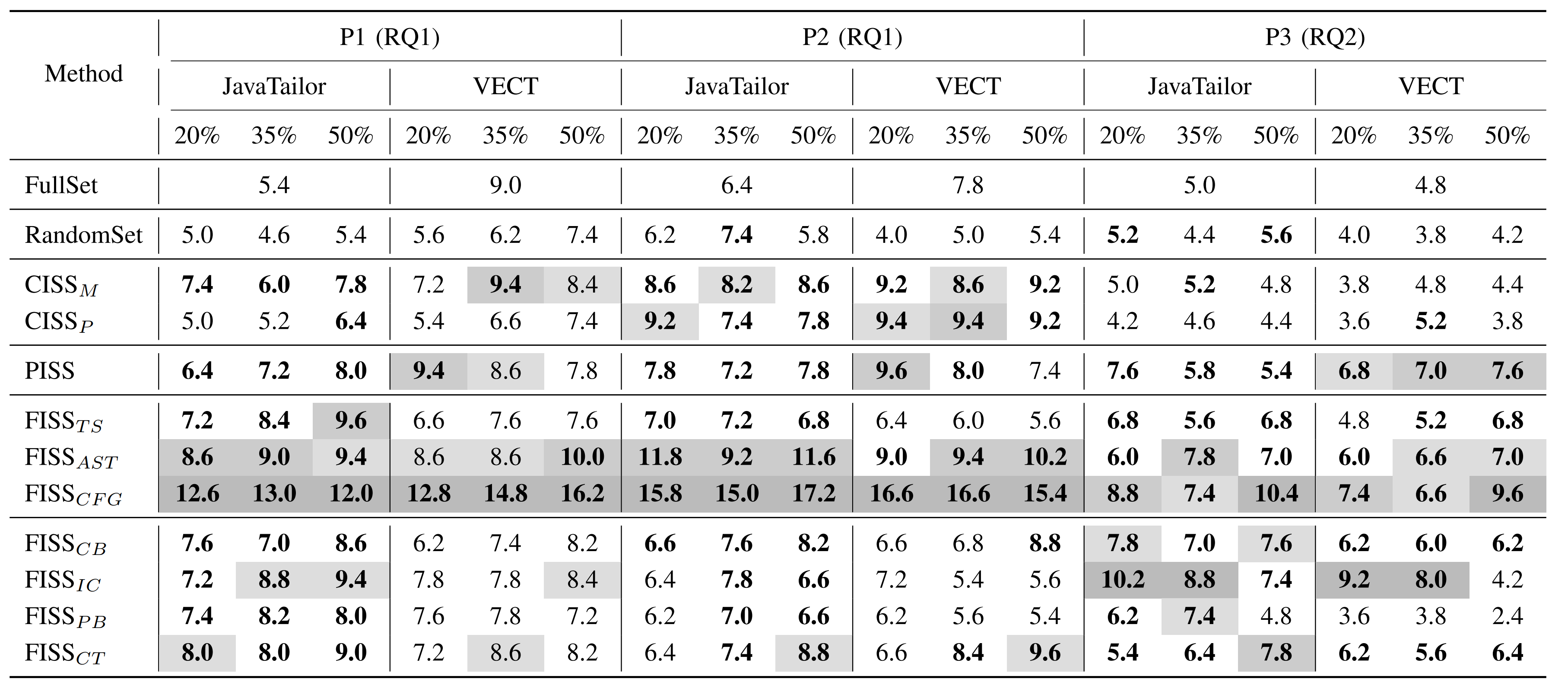
Table 1 shows the comparison results of each method in terms of unique inconsistencies in the differential testing. The FullSet and RandomSet in the first column represent the use of the entire set of initial seeds and the subset selected by random selection, serving as baselines for comparison. Results highlighted in bold indicate superior performance compared to the FullSet. The top three performing methods are shaded, with darker shades indicating better performance.
Table 1: Comparison results of different methods in terms of the number of unique inconsistencies
II. Project Structure
├── Code
│ ├── dataProcessing // Data processing module
│ ├── seedSelection // Seed Selection module
│ │ ├── coverage
│ │ | ├── CISS_M // Coverage-based Seed Selection Method
│ │ | └── CISS_P // Coverage-Increment-based Seed Selection Method
│ │ ├── feature
│ │ | └── FISS // Prefuzz-based Seed Selection Method
│ │ └── prefuzz
│ │ └── PISS // Program-Feature-based Seed Selection Method
│ ├── utils
│ ├── pythonCode // Preprocessing implemented in python
│ ├── DataProcessing.java // Preprocessing for three types of methods
│ └── SeedSelection.java // Entry for initial seed selection
├── Data
│ ├── benchmarks
│ | ├── HotspotTests-Java // Benchmark P1
│ | ├── Openj9Test-Test // Benchmark P2
│ | └── CollectProject // Open-source Benchmark P3 collected from Github
│ ├── covInfo
│ | └── ProjeactName
│ │ └── info // Coverage files folder, seed.info
│ ├── bugInfo
│ | └── ProjeactName
│ │ ├── testcases.txt // All initial seeds
│ │ └── difference.log // Prefuzzing result
│ └── featureInfo
└── Result
To facilitate use by developers, we have uploaded the relevant data to zenodo for download.
III. Getting Started
1: Import as an maven project
This is developed as an maven project, so you can directly load the project using IntelliJ IDEA workspace to build the environment.
2: Data Collection
- Collecting coverage for CISS
You need to compile a JVM that can collect coverage (set compilation option --enable-native-coverage)
Use this JVM to execute each seed program and collect coverage. We propose to use GCOV+LCOV to obtain coverage information.
lcov -b ./ -d ./ --rc lcov_branch_coverage=1 --gcov-tool /usr/bin/gcov -c -o seed.info
You can download the coverage information we collected directly.
-
Prefuzz result for PISS
Perform a 5-minute test on each seed program using VECT. The goal is to get the fuzzing result file
difference.log.You can download the fuzzing result we collected directly.
3. Data Processing
Our data processing is implemented in two languages and can be used according to actual needs.
The following four methods are implemented using Java code:
You can do data processing by calling the Java DataProcessing projectname method, where method can select CISS, PISS, FISSAST, and FISSCFG.
The rest of the methods are implemented using python:
You can do data processing by calling the python CodeBERTVector.py projectname.
4. Seed Selection
Similarly, you can make an initial seed selection using SeedSelection, which you can do by calling the following command:
java SeedSelection [projectList] [budgetList] [methodList]
For example:
java SeedSelection [HotspotTests-Java,Openj9Test-Test] [20,35,50] [CISSM,CISSP]