Evaluating your evaluator
October 16, 2024 · View on GitHub
Before using a judge-LLM in production or at scale, you want to first evaluate its quality for your task, to make sure its scores are actually relevant and useful for you.
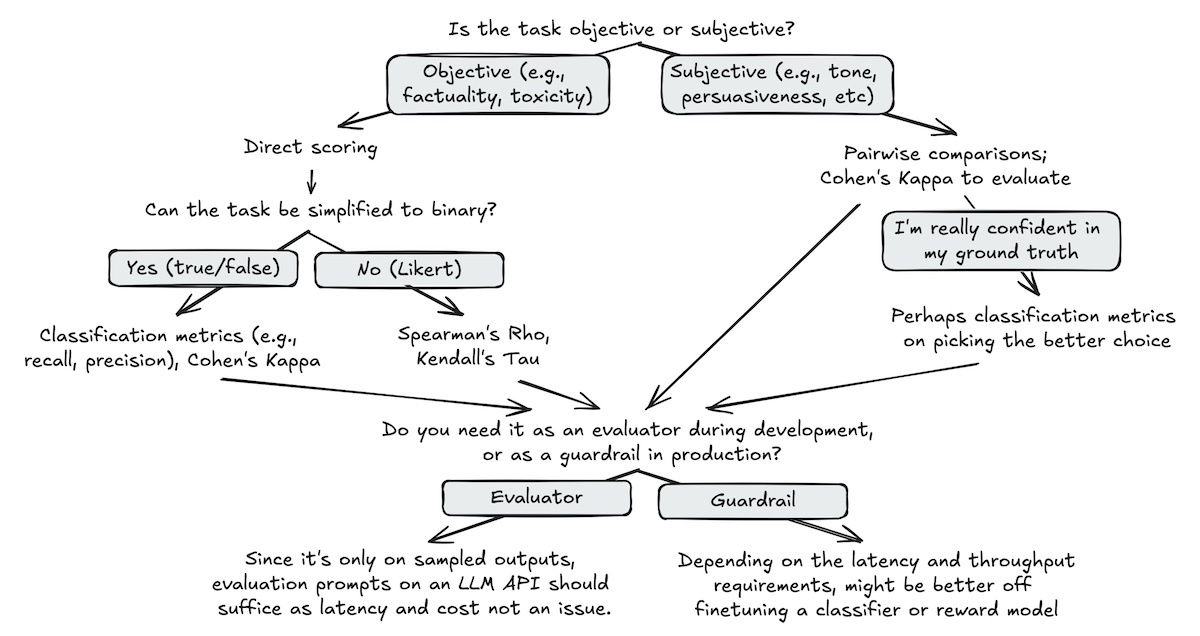
Note: This will be easier to do if it predicts binary outputs, because you'll be able to interpretable classification metrics (accuracy/recall/precision). If it predicts scores on a scale, it will be much harder to estimate the quality of the correlation with a reference.
So, once you have selected your model judge and its prompt, you'll need to do the following.
1. Pick your baseline
You'll need to compare your evaluator judgments to a baseline: it can be human annotations, the output of another judge model that you know is qualitative on your task, a gold truth, itself with another prompt, etc.
You don't necessarily need a lot of examples (50 can be enough), but you need them to be extremely representative of your task, discriminative (representative of edge cases notably), and of as high quality as you can manage.
2. Pick your metric
Your metric will be used to compare your judge's evaluations with your reference.
In general, this comparison is considerably easier to do if your model is predicting binary classes or doing pairwise comparison, as you'll be able to compute accuracy (for pairwise comparison), or precision and recall (for binary classes), which are all very easy to interpret metrics.
Comparing the correlation of scores with human or model scoring will be harder to do. To understand why in more detail, I advise you to read this cool blog section on the topic.
In general, if you're a bit lost about what metrics to pick when (in terms of models, metrics, ...), you can also look at this interesting graph from the same above blog ⭐.
{kind=link}
3. Evaluate your evaluator
For this step, you simply need to use your model and its prompt to evaluate your test samples! Then, once you get the evaluations, use your above metric and reference to compute a score for your evaluations.
You need to decide what your threshold for acceptance is. Depending on how hard your task is, you can aim for 80% to 95% accuracy, if you're doing pairwise comparison. Regarding correlations (if you're using scores), people in the literature tend to seem happy with 0.8 Pearson correlation with a reference. However, I've seen some papers declare that 0.3 indicates a good correlation with human annotators (^^") so ymmv.