CoreML-LLM
June 8, 2026 · View on GitHub
On-device LLMs on the Apple Neural Engine. Run Gemma 4, Qwen3.5, Qwen3-VL, FunctionGemma, EmbeddingGemma, and Liquid AI's LFM2.5 on iPhone with CoreML — ANE-first, battery-friendly, no server.
Where MLX Swift is the right call when you want maximum GPU throughput, CoreML-LLM is what you use when the LLM should live on the ANE so the GPU stays free for the rest of the app.
Use in your app
Add the package, name a model, generate.
// Package.swift
.package(url: "https://github.com/john-rocky/CoreML-LLM", from: "1.9.0")
import CoreMLLLM
let llm = try await CoreMLLLM.load(repo: "lfm2.5-350m")
let answer = try await llm.generate("What is the capital of France?")
repo: accepts a registered model id ("gemma4-e2b", "qwen3.5-0.8b", "lfm2.5-350m", …) or a full HuggingFace path — first call downloads, later calls reuse the on-device bundle. Streaming, multi-turn chat, image / video / audio, FunctionGemma, EmbeddingGemma → package docs (Quick Start → Swift Package).
Models
| Model | Size | Task | iPhone 17 Pro decode | HuggingFace |
|---|---|---|---|---|
| Gemma 4 E2B | 5.4 GB (4.4 GB text-only) | Text + image + video + audio | 34.2 tok/s | mlboydaisuke/gemma-4-E2B-coreml |
| Gemma 4 E4B | 8.16 GB multimodal / 5.5 GB text-only | Text + image + video + audio | 15.7 tok/s | multimodal · text-only |
| Qwen3.5 2B | 2.8 GB | Text | ~27 tok/s | mlboydaisuke/qwen3.5-2B-CoreML |
| Qwen3.5 0.8B | 1.2 GB | Text | ~48 tok/s | mlboydaisuke/qwen3.5-0.8B-CoreML |
| Qwen3-VL 2B (stateful) | 2.3 GB | Text + image | ~24 tok/s | mlboydaisuke/qwen3-vl-2b-stateful-coreml |
| Qwen3-VL 4B (stateful) | 3.3 GB | Text + image | TBD (device) | mlboydaisuke/qwen3-vl-4b-stateful-coreml |
| Qwen3-VL 8B (stateful) | 5.9 GB | Text + image | TBD (device) | mlboydaisuke/qwen3-vl-8b-stateful-coreml |
| LFM2.5 350M † | 810 MB | Text | 52 tok/s | mlboydaisuke/lfm2.5-350m-coreml |
| FunctionGemma-270M | 850 MB | Function calling | (specialist) | mlboydaisuke/functiongemma-270m-coreml |
| EmbeddingGemma-300M | 295 MB | Sentence embeddings | (specialist) | mlboydaisuke/embeddinggemma-300m-coreml |
| Qwen3-VL 2B (legacy) | 2.9 GB | Text + image | ~7.5 tok/s | mlboydaisuke/qwen3-vl-2b-coreml |
| Qwen2.5 0.5B | 302 MB | Text | — | mlboydaisuke/qwen2.5-0.5b-coreml |
| Granite 4.1 3B (preview, sideload, ANE) | 3.9 GB INT8+fp16 | Text | 14 tok/s Mac, iPhone TBD (top-1 parity 100% vs HF) | ibm-granite/granite-4.1-3b |
All numbers are iPhone 17 Pro A19 Pro, 2048-token context, ANE-only (no GPU fallback at runtime unless noted). Methodology: docs/BENCHMARKING.md.
Which one should I pick?
- Multimodal (image / video / audio), fastest → Gemma 4 E2B (34 tok/s)
- Multimodal, highest quality → Gemma 4 E4B (multimodal) (15.7 tok/s)
- Image + text chat, lowest memory + fastest follow-up → Qwen3-VL 2B (stateful)
- Image + text chat, higher quality → Qwen3-VL 4B (3.3 GB) or 8B (5.9 GB, high-memory device)
- Text-only, maximum quality under ≤3 GB → Qwen3.5 2B
- Text-only, maximum quality → Gemma 4 E4B (text-only)
- Text-only, fast + chat-strong → Qwen3.5 0.8B (48 tok/s)
- Text-only, smallest at high tok/s on iPhone → LFM2.5 350M (52 tok/s, 810 MB) †
- Tool / function calling → FunctionGemma-270M
- Sentence embeddings / RAG → EmbeddingGemma-300M
Burst tok/s is only half the story
The decode numbers above are cold-burst speed. Run the same model continuously and the ranking inverts: the GPU runtimes (MLX, LiteRT-LM) thermally throttle 50%+ within ~60 s, while CoreML on the ANE barely moves — it draws ~half the power (12.7 W vs ~24.7 W at full decode, measured on Mac), so the phone doesn't have to throttle it. Under sustained load the ANE overtakes MLX outright.
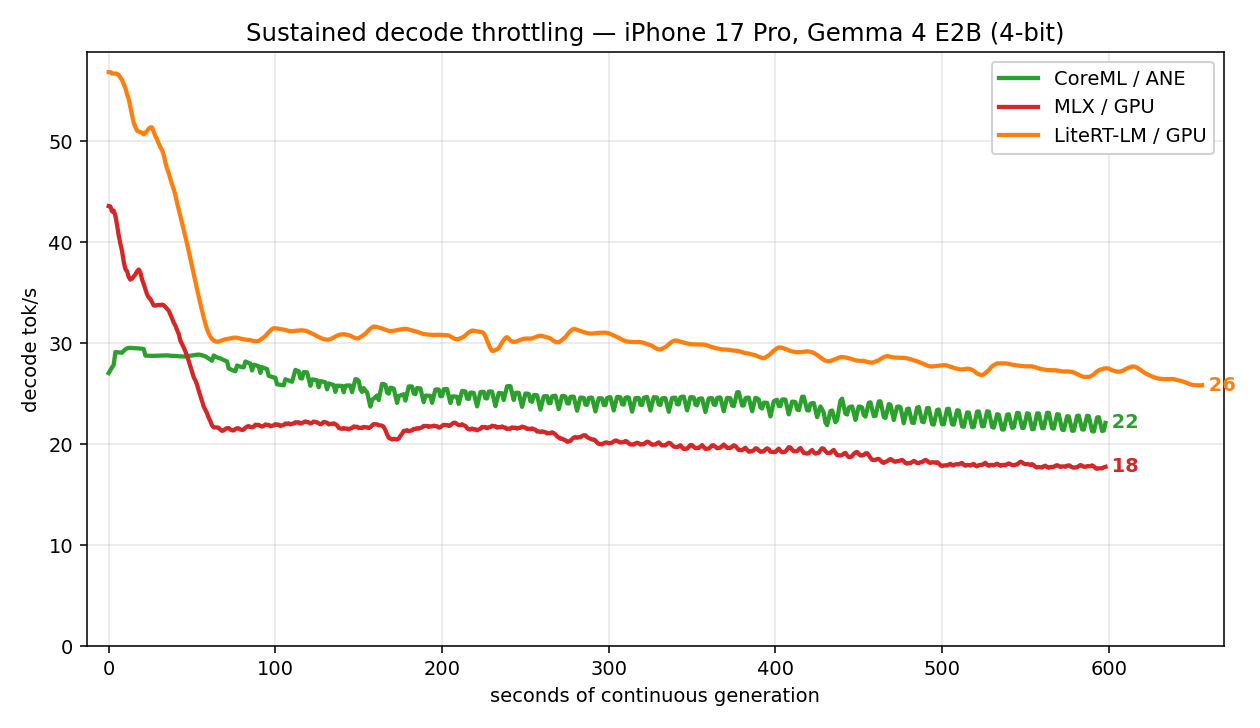
| Runtime (compute) | Burst tok/s | Sustained (10 min) | Retained |
|---|---|---|---|
| CoreML / ANE | 33 | 22 | 67% |
| MLX / GPU | 48 | 18 | 38% |
| LiteRT-LM / GPU | 56 | 27 | 48% |
Lower peak, but it sustains — and leaves the GPU free for the rest of the app. Full data + repro: apple-silicon-llm-bench.
Demos
| Text |
Image |
| Video |
Audio |
Quick Start
Try it — App Store
Models Zoo is a pre-built app shipping CoreML-LLM. Open it, pick a model, download, chat.
Build from source
open Examples/CoreMLLLMChat/CoreMLLLMChat.xcodeproj
Set your development team → build to an iOS 18+ device → Get Model → download → chat. Compute units default to .cpuAndNeuralEngine (ANE).
Swift Package
dependencies: [
.package(url: "https://github.com/john-rocky/CoreML-LLM", from: "1.9.0"),
]
import CoreMLLLM
// Download + load in one call
let llm = try await CoreMLLLM.load(model: .gemma4e2b) { print(\$0) }
// Simple / streaming / multi-turn
let answer = try await llm.generate("What is the capital of France?")
for await tok in try await llm.stream("Tell me a story") { print(tok, terminator: "") }
let messages: [CoreMLLLM.Message] = [
.init(role: .user, content: "Hi!"),
.init(role: .assistant, content: "Hello!"),
.init(role: .user, content: "What is 2+2?"),
]
for await tok in try await llm.stream(messages) { print(tok, terminator: "") }
// Multimodal (Gemma 4)
let caption = try await llm.generate("Describe this image", image: cgImage)
let transcript = try await llm.generate("What did they say?", audio: pcmSamples)
let analysis = try await llm.generate(
"Describe this video frame by frame.",
videoURL: URL(fileURLWithPath: "/path/to/clip.mp4"),
videoOptions: .init(fps: 1.0, maxFrames: 6))
// Fastest decode on iPhone 17 Pro A19 Pro: opt into the 3-chunk path.
// Set in the Xcode scheme: Environment Variables → LLM_3CHUNK = 1.
// +8.2 % tok/s, bit-equivalent to the default 4-chunk decode.
Downloads run in the background via URLSessionConfiguration.background with pause/resume support:
let url = try await ModelDownloader.shared.download(.gemma4e2b)
ModelDownloader.shared.pause()
ModelDownloader.shared.resumeDownload()
FunctionGemma + EmbeddingGemma
Two specialists with their own narrow Swift APIs. Ship them alongside a chat model (Gemma 4, Qwen3.5) for tool calling + RAG.
import CoreMLLLM
let dir = FileManager.default
.urls(for: .applicationSupportDirectory, in: .userDomainMask)[0]
// Function calling (850 MB, ≥ 92% ANE, batched prefill T=32)
let fg = try await FunctionGemma.downloadAndLoad(modelsDir: dir)
let (text, call) = try fg.generateFunctionCall(
userPrompt: "Turn on the flashlight",
tools: [[
"type": "function",
"function": [
"name": "toggle_flashlight",
"description": "Turn the phone flashlight on or off.",
"parameters": ["type": "object", "properties": [:], "required": []],
],
]])
// call = "call:toggle_flashlight{}"
// Embeddings (295 MB, 99.80% ANE, Matryoshka 768/512/256/128)
let eg = try await EmbeddingGemma.downloadAndLoad(modelsDir: dir)
let vec = try eg.encode(text: "How do cats behave?",
task: .retrievalQuery, dim: 768)
Standalone sample at Examples/Gemma3Demo/ imports CoreMLLLM and exercises both without pulling the Gemma 4 chat stack. Full I/O contracts in docs/FUNCTIONGEMMA.md + docs/EMBEDDINGGEMMA.md.
Convert your own
cd conversion
python3 -m venv .venv && source .venv/bin/activate
pip install -r requirements.txt
# Qwen2.5 0.5B (~2 min)
python convert.py --model qwen2.5-0.5b --output ./output/qwen2.5-0.5b
# IBM Granite 4.1 3B — dense GQA decoder (40 layers, hidden=2560), Apache 2.0.
# Speedup-optimized chunked stateful path (Qwen3-VL Phase 1 / Qwen3.5 v1.8.0 recipe):
# 5 INT8 chunks (8 layers each) + fp16 head + mmap embed sidecar, loaded via
# Granite4Generator. Multipliers: embedding(×12) baked into embed_weight.bin,
# logits(/10) baked into lm_head conv weight, attention(1/64) + residual(0.22)
# live in the chunk graphs as scalar consts.
python build_granite4_chunks.py \
--model-id ibm-granite/granite-4.1-3b \
--out-dir ./output/granite-4.1-3b \
--num-chunks 5 --nbits 8 --head-fp16
# Gemma 4 — one-shot bundle builder (chunks + embeds + PLE + RoPE +
# tokenizer + model_config.json, ready for USB sideload or HF upload)
python build_gemma4_bundle.py --model gemma4-e2b --ctx 2048
python build_gemma4_bundle.py --model gemma4-e4b --ctx 2048
# Gemma 4 E2B 3-chunk decode (default since v1.7, +8.2 % tok/s on iPhone A19 Pro)
python build_gemma4_3way.py --model gemma4-e2b --ctx 2048
python install_3way_bundle.py
# Specialists
python build_functiongemma_bundle.py --ctx 2048 --quantize int8 --prefill-t 32
python build_embeddinggemma_bundle.py --max-seq-len 128 --quantize int8
# LFM2.5 350M (Liquid AI hybrid attn + short-conv) — sideload-ready bundle
python build_lfm2_bundle.py --model lfm2.5-350m --l-pad 3
Step-by-step: docs/ADDING_MODELS.md. Full reference (quant, .mlpackage → .mlmodelc, iPhone deployment): docs/CONVERSION.md. LFM2-specific deep-dive (ChatML template, dual-state ANE blocker, fp16 short-conv drift): docs/LFM2_CONVERSION_FINDINGS.md.
Documentation
Design docs, benchmarks, and per-model conversion notes live in docs/. Start with docs/ARCHITECTURE.md for the chunked decode design, ANE optimizations, MLX comparison, and project layout.
What's new
Current release: v1.9.0 (release notes).
- v1.9.0 — Gemma 4 E4B multimodal (text + image + video + audio) on iPhone 17 Pro at 15.7 tok/s decode. Topology II 3-chunk decode (
chunk1+chunk2_3way+chunk3_3way) + legacy 4-chunkprefill_b8multifunction with vision-aware bidirectional mask. E4B-builtvision.ane.mlmodelc(output[1, 256, 2560]) + Conformer audio + Swift two-stage projection (1024 → 1536 → 2560, non-squareembed_proj). New picker entry "Gemma 4 E4B (multimodal)" auto-downloads frommlboydaisuke/gemma-4-E4B-multimodal-coreml(~8.16 GB); text-only entry kept at the existing HF repo. Build + sideload guide: docs/E4B_MULTIMODAL_BUILD.md. - v1.8.0 — Qwen3.5 0.8B / 2B full-vocab rep_penalty masks iPhone A18 fp16 ANE reduction bias. 0.8B: 48 tok/s, 2B: 27 tok/s on iPhone 17 Pro, all clean output across English + Japanese. +45 % over the prior v1.x ceiling. See docs/QWEN35_FULL_VOCAB_REP_PENALTY.md.
- v1.7.0 — Gemma 4 E2B 3-chunk decode is the picker default + multimodal opt-out toggle. The new
gemma4e2b3wayModelInfo shipschunk2_3way(L8-24 merged) +chunk3_3way(L25-34 + lm_head) and re-uses legacychunk1+ 4-chunk prefill graphs (vision-aware bidirectional mask preserved). Decodec1+c2+c4(chunk3 nil) — 3 ANE dispatches/step, 34.2 tok/s on iPhone 17 Pro A19 Pro. The 4-chunk legacy entry stays asGemma 4 E2B (4-chunk legacy). ModelPickerView's "Download Options → Include multimodal" toggle drops vision/video/audio encoders + sidecars when off (~1 GB savings, text-only install). finishDownload now hardlinks shared decode↔prefill weights instead of copying (chunk1↔prefill_chunk1andchunk3_3way↔prefill_chunk4, −682 MB on disk). - v1.6.0 — Qwen3-VL 2B stateful Phase 2: cross-turn KV reuse + ANE prewarm. Same-prompt 2nd TTFT 4 s → 125 ms (~32×), vision-chat 2nd-turn TTFT 125 ms (target was <500 ms). LCP-matched MLState resume + image-pinned-to-first-user-turn prompt builder + per-chunk dummy predict at load (231 ms total).
- v1.5.0 — Qwen3-VL 2B stateful Phase 1: MLState + slice_update KV cache + multifunction prefill_b8. 24 tok/s decode at 256 MB phys_footprint on iPhone 17 Pro (vs 7.5 tok/s / 1.7 GB on the v1.3 recurrent build — 3.2× decode, 6.4× memory drop). 4-chunk INT8 + fp16 embed sidecar.
- v1.4.0 — Gemma 4 E2B 3-chunk decode (opt-in,
LLM_3CHUNK=1): 31.6 → 34.2 tok/s on iPhone 17 Pro A19 Pro (+8.2 %). Bit-equivalent to 4-chunk by construction. Closes the ANE-ceiling sweep for E2B; five additional lossless probes (SDPA fusion, K=V alias, Topology I boundary search, blockwise palettization, native softmax) all landed as negative results — see docs/EXPERIMENTS.md. - v1.3.0 — Qwen3-VL 2B (text + vision on ANE, 196 image tokens, DeepStack injection at L0/1/2, interleaved mRoPE for image tokens). 28-layer GQA, 2.9 GB bundle, ~7.5 tok/s text decode. (Recurrent KV — superseded by v1.5.0 stateful build; kept for backward compatibility.)
- v1.2.0 — FunctionGemma-270M (function calling, batched prefill T=32) and EmbeddingGemma-300M (99.80 % ANE, Matryoshka 768/512/256/128). Standalone
Gemma3Demosample. - v1.1.0 — Qwen3.5 2B (4 INT8 chunks + mmap fp16 embed sidecar, ~200 MB phys_footprint for a 2B-param model).
- v1.0.0 — Qwen3.5 0.8B (first hybrid SSM+attention LLM on CoreML, 99.9 % ANE).
- v0.8.0 — Gemma 4 E4B (42-layer text decoder, 100 % ANE).
- v0.7.0 — Video multimodal (native 384×384 vision encoder, 64 tokens/frame).
- v0.6.2 — Audio multimodal (12-layer Conformer encoder).
Full history: GitHub Releases.
Requirements
- Inference: iOS 18+ / macOS 15+
- Conversion: Python 3.10–3.12, coremltools 8+, PyTorch 2.2+
- Sample apps: Xcode 16+
License
MIT for the CoreML-LLM code. Model weights inherit the original licenses (Gemma weights: Gemma Terms of Use; Qwen weights: Apache 2.0; Qwen3-VL vision weights: Apache 2.0).
† LFM2.5 350M weights are under LFM Open License v1.0 (Liquid AI). Free for non-commercial use, research, and commercial use up to a US $10M annual revenue threshold. Above that threshold, see Liquid AI for a separate commercial license.