Bidirectional Retrieval Made Simple
June 21, 2018 · View on GitHub
Code for our CVPR"18 paper Bidirectional Retrieval Made Simple. Given that the original code from our work cannot be publicly shared, we adapted the code from VSE++ in order to provide a public version.
Overview:
Summary
Code for training and evaluating our novel CHAIN-VSE models for efficient multimodal retrieval (image annotation and caption retrieval). In summary, CHAIN-VSE uses convolutional layers directly over character-level inputs fully replacing the use of RNNs and word-embeddings. Despite being lighter and conceptually much simpler, those models achieve state-of-the-art results in MS COCO and in some text classification datasets.
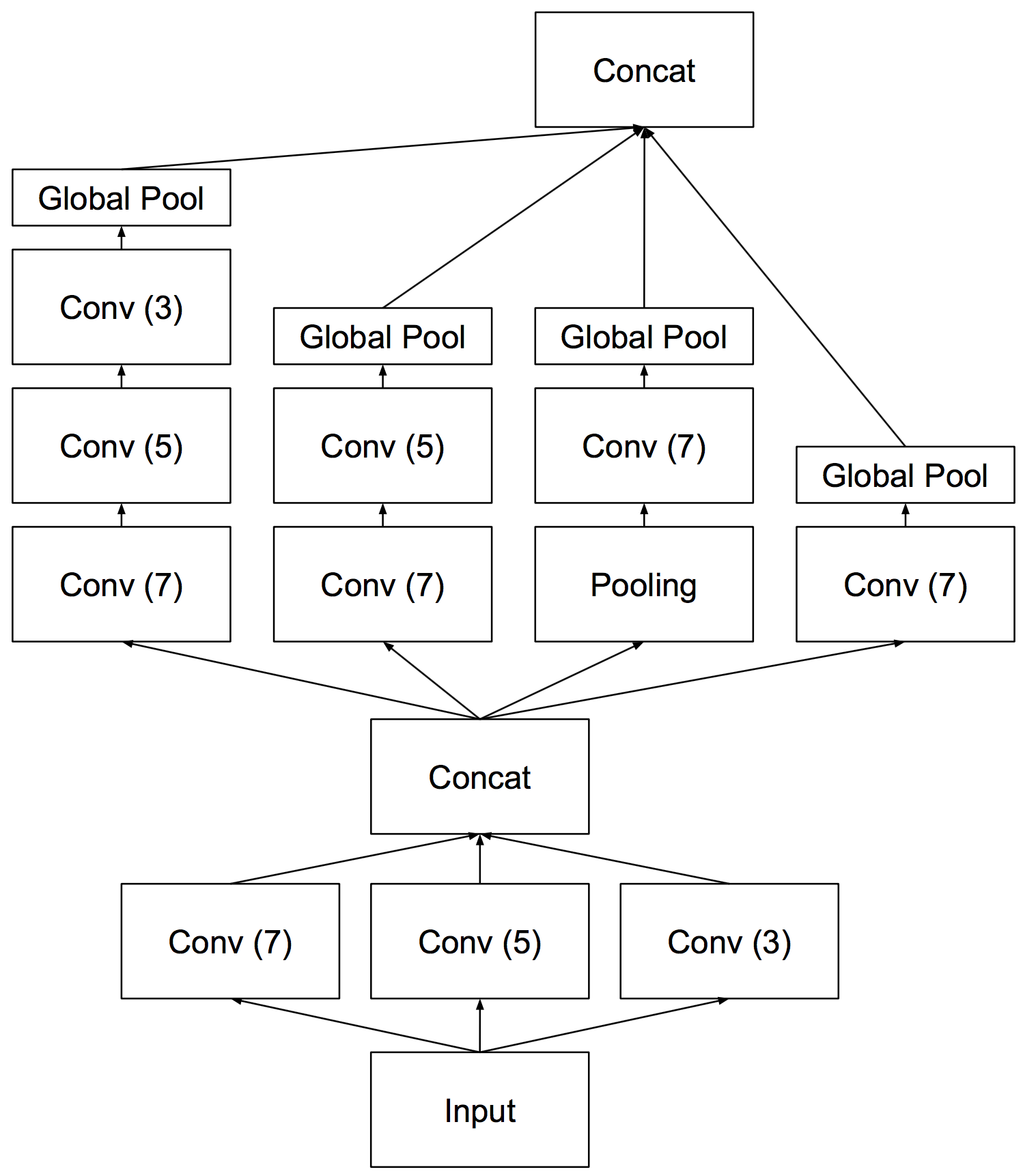
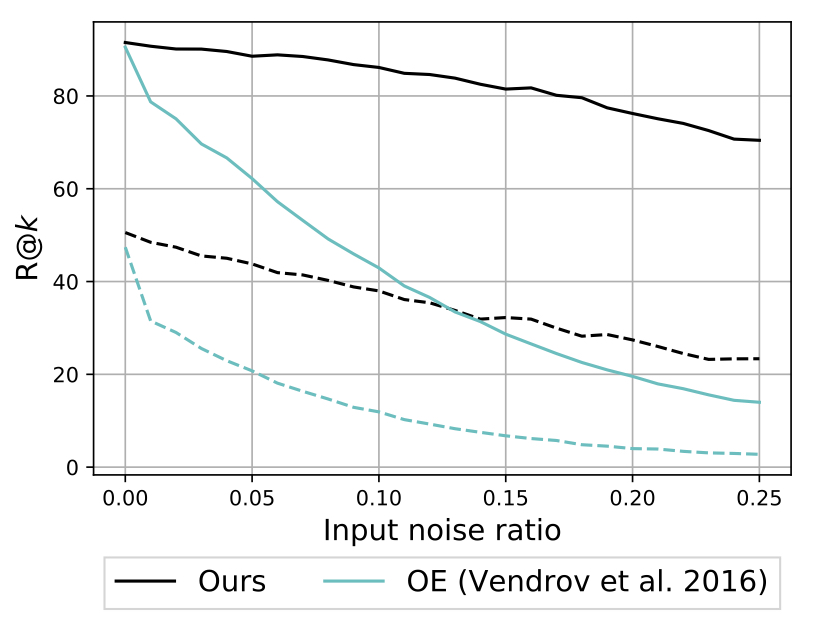
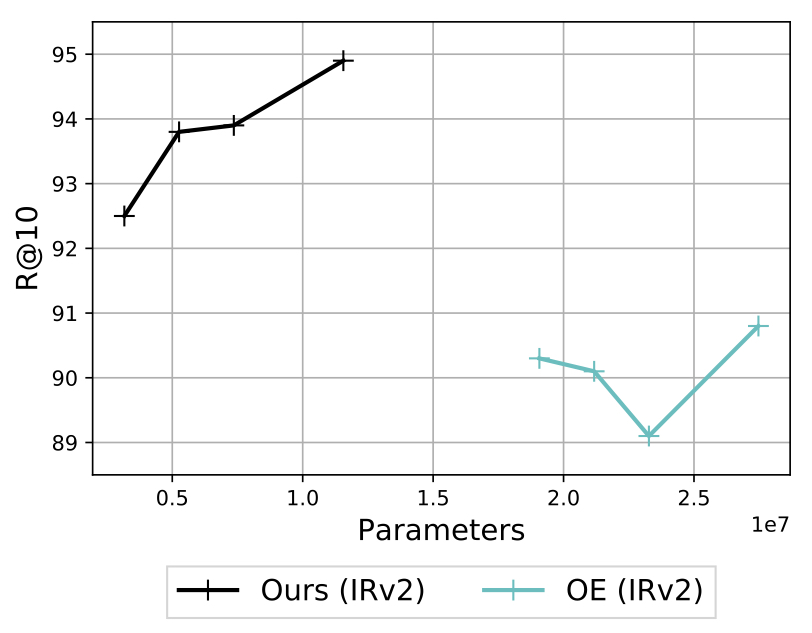
Highlights
- Independent from word-embeddings and RNNs
- Naturally suited for multi-language scenarios without increase of memory requirements due to larger vocabulary
- Much more robust to input noise
- Fewer parameters
- Simple, yet effective
Bidirectional Retrival Results
Results achieved using this repository (COCO-1k test set) using pre-computed features (note that we do not finetune the network in this experiment):
| Method | Features | R@1 | R@10 | R@1 | R@10 |
|---|---|---|---|---|---|
| RFF-net [baseline@ICCV"17] | ResNet152 | 56.40 | 91.50 | 43.90 | 88.60 |
chain-v1 (p=1, d=1024) | resnet152_precomp | 57.80 | 95.60 | 44.18 | 90.66 |
chain-v1 (p=1, d=2048) | resnet152_precomp | 59.90 | 94.80 | 45.08 | 90.54 |
chain-v1 (p=1, d=8192) | resnet152_precomp | 61.20 | 95.80 | 46.60 | 90.92 |
Getting Started
For getting started you will need to setup your environment and download the required data.
Dependencies
We recommended to use Anaconda for the following packages.
- Python 2.7
- PyTorch (>0.1.12)
- NumPy (>1.12.1)
- TensorBoard
- Punkt Sentence Tokenizer (used in our baselines):
import nltk
nltk.download()
> d punkt
Download data
Pre-computed features:
wget http://lsa.pucrs.br/jonatas/seam-data/irv2_precomp.tar.gz
wget http://lsa.pucrs.br/jonatas/seam-data/resnet152_precomp.tar.gz
wget http://lsa.pucrs.br/jonatas/seam-data/vocab.tar.gz
- The directory of the
*_precomp.tar.gzfiles are referred as$DATA_PATH - Extract
vocab.tar.gzto./vocabdirectory (required for baselines only).
Training new models
Run train.py:
To train CHAIN-VSE (p=1, d=2048) using resnet152_precomp features, run:
python train.py \
--data_path "$DATA_PATH" \
--data_name resnet152_precomp \
--logger_name runs/chain-v1/resnet152_precomp/ \
--text_encoder chain-v1 \
--embed_size 2048 \
--vocab_path char
Evaluate pre-trained models
from vocab import Vocabulary
import evaluation
evaluation.evalrank("$RUN_PATH/model_best.pth.tar", data_path="$DATA_PATH", split="test")'
To evaluate in COCO-1cv test set, pass fold5=True with a model trained using
--data_name coco.
Citation
If you found this code/paper useful, please cite the following papers:
@InProceedings{wehrmann2018cvpr,
author = {Wehrmann, Jônatas and Barros, Rodrigo C.},
title = {Bidirectional Retrieval Made Simple},
booktitle = {The IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2018}
}
@article{faghri2017vse++,
title={VSE++: Improving Visual-Semantic Embeddings with Hard Negatives},
author={Faghri, Fartash and Fleet, David J and Kiros, Jamie Ryan and Fidler, Sanja},
journal={arXiv preprint arXiv:1707.05612},
year={2017}
}