1xN Pattern for Pruning Convolutional Neural Networks (paper) .
July 30, 2022 · View on GitHub
Pytorch implementation of our paper accepted by TPAMI 2022 -- "1xN Pattern for Pruning Convolutional Neural Networks".
1) 1×N Block Pruning
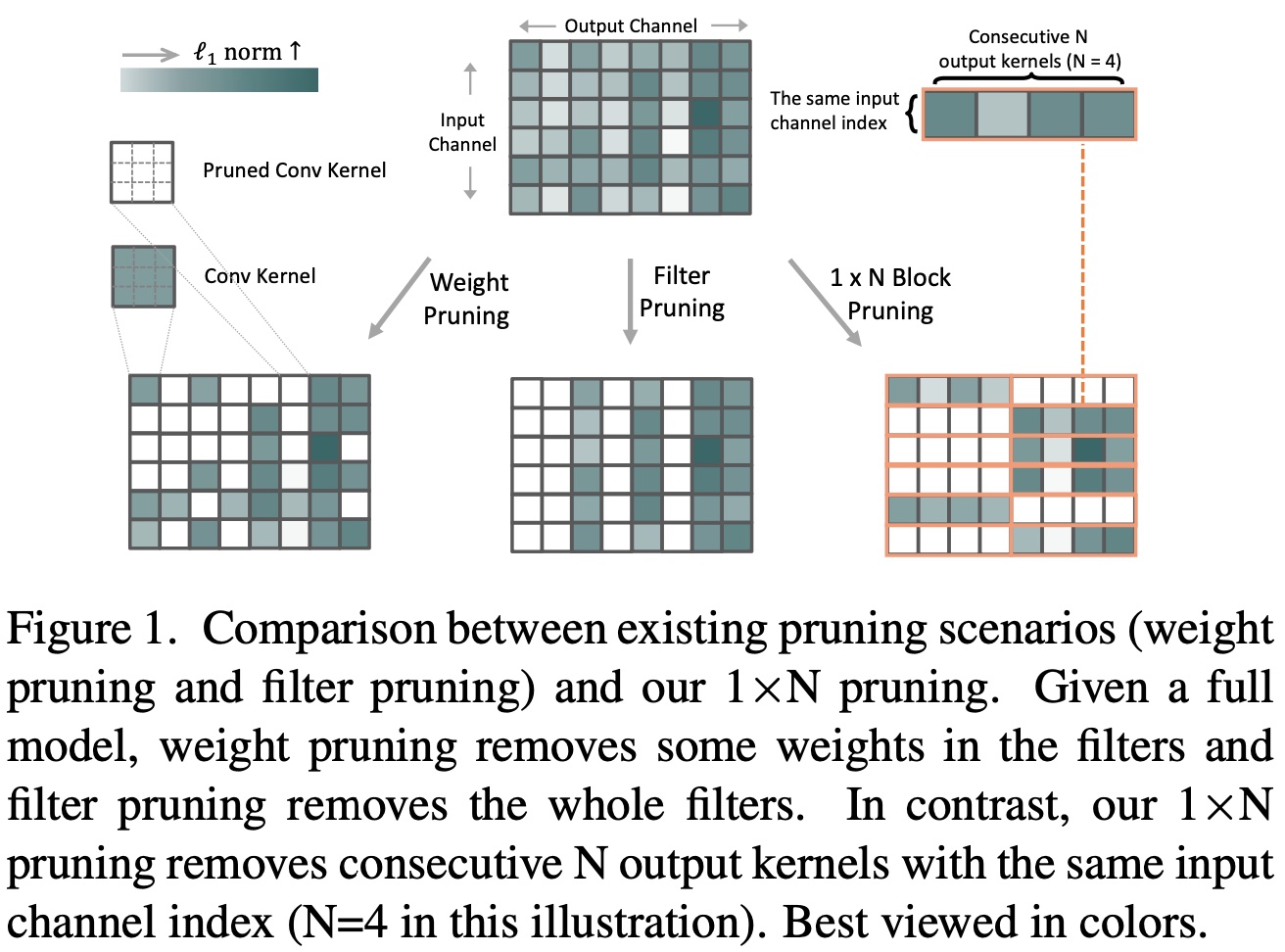
Requirements
- Python 3.7
- Pytorch >= 1.0.1
- CUDA = 10.0.0
Code Running
To reproduce our experiments, please use the following command:
python imagenet.py \
--gpus 0 \
--arch mobilenet_v1 (or mobilenet_v2 or mobilenet_v3_large or mobilenet_v3_small) \
--job_dir ./experiment/ \
--data_path [DATA_PATH] \
--pretrained_model [PRETRAIN_MODEL_PATH] \
--pr_target 0.5 \
--N 4 (or 2, 8, 16, 32) \
--conv_type BlockL1Conv \
--train_batch_size 256 \
--eval_batch_size 256 \
--rearrange \
The pre-trained models can be downloaded at MobileNet-V1, MobileNet-V2, MobileNet-V3-Large, MobileNet-V3-Small and ResNet-50.
Accuracy Performance
Table 1: Performance comparison of our 1×N block sparsity against weight pruning and filter pruning (p = 50%).
| MobileNet-V1 | Top-1 Acc. | Top-5 Acc. | Model Link |
|---|---|---|---|
| Weight Pruning | 70.764 | 89.592 | Pruned Model |
| Filter Pruning | 65.348 | 86.264 | Pruned Model |
| 1 x 2 Block | 70.281 | 89.370 | Pruned Model |
| 1 x 4 Block | 70.052 | 89.056 | Pruned Model |
| 1 x 8 Block | 69.908 | 89.027 | Pruned Model |
| 1 x 16 Block | 69.559 | 88.933 | Pruned Model |
| 1 x 32 Block | 69.541 | 88.801 | Pruned Model |
| MobileNet-V2 | Top-1 Acc. | Top-5 Acc. | Model Link |
|---|---|---|---|
| Weight Pruning | 71.146 | 89.872 | Pruned Model |
| Filter Pruning | 66.730 | 87.190 | Pruned Model |
| 1 x 2 Block | 70.233 | 89.417 | Pruned Model |
| 1 x 4 Block | 60.706 | 89.165 | Pruned Model |
| 1 x 8 Block | 69.372 | 88.862 | Pruned Model |
| 1 x 16 Block | 69.352 | 88.708 | Pruned Model |
| 1 x 32 Block | 68.762 | 88.425 | Pruned Model |
| MobileNet-V3-small | Top-1 Acc. | Top-5 Acc. | Model Link |
|---|---|---|---|
| Weight Pruning | 66.376 | 86.868 | Pruned Model |
| Filter Pruning | 59.054 | 81.713 | Pruned Model |
| 1 x 2 Block | 65.380 | 86.060 | Pruned Model |
| 1 x 4 Block | 64.465 | 85.495 | Pruned Model |
| 1 x 8 Block | 64.101 | 85.274 | Pruned Model |
| 1 x 16 Block | 63.126 | 84.203 | Pruned Model |
| 1 x 32 Block | 62.881 | 83.982 | Pruned Model |
| MobileNet-V3-large | Top-1 Acc. | Top-5 Acc. | Model Link |
|---|---|---|---|
| Weight Pruning | 72.897 | 91.093 | Pruned Model |
| Filter Pruning | 69.137 | 89.097 | Pruned Model |
| 1 x 2 Block | 72.120 | 90.677 | Pruned Model |
| 1 x 4 Block | 71.935 | 90.458 | Pruned Model |
| 1 x 8 Block | 71.478 | 90.163 | Pruned Model |
| 1 x 16 Block | 71.112 | 90.129 | Pruned Model |
| 1 x 32 Block | 70.769 | 89.696 | Pruned Model |

Besides, we provide the raw data for plotting the above figures in ./raw_data_fig4. For example, run python ./raw_data_fig4/resnet50_top1.py to plot top-1 accuracy of ResNet-50 pruned by different methods.
More links for pruned models under different pruning rates and their training logs can be found in MobileNet-V2 and ResNet-50.
Table 2: Performance studies of our 1×N pruning with kernel-wise pruning.
| ResNet-50 | Top-1 Acc. | Top-5 Acc. | Model Link |
|---|---|---|---|
| 1x4 Block | 76.506 | 93.239 | Pruned Model |
| kernel (random) | 74.834 | 92.178 | Pruned Model |
| kernel () | 75.370 | 92.582 | Pruned Model |
Evaluate our models
To verify the performance of our pruned models, download our pruned models from the links provided above and run the following command:
python imagenet.py \
--gpus 0 \
--arch mobilenet_v1 (or mobilenet_v2 or mobilenet_v3_large or mobilenet_v3_small) \
--data_path [DATA_PATH] \
--conv_type DenseConv \
--evaluate [PRUNED_MODEL_PATH] \
--eval_batch_size 256 \
Arguments
optional arguments:
-h, --help show this help message and exit
--gpus Select gpu_id to use. default:[0]
--data_path The dictionary where the data is stored.
--job_dir The directory where the summaries will be stored.
--resume Load the model from the specified checkpoint.
--pretrain_model Path of the pre-trained model.
--pruned_model Path of the pruned model to evaluate.
--arch Architecture of model. For ImageNet :mobilenet_v1, mobilenet_v2, mobilenet_v3_small, mobilenet_v3_large
--num_epochs The num of epochs to train. default:180
--train_batch_size Batch size for training. default:256
--eval_batch_size Batch size for validation. default:100
--momentum Momentum for Momentum Optimizer. default:0.9
--lr LR Learning rate. default:1e-2
--lr_decay_step The iterval of learn rate decay for cifar. default:100 150
--lr_decay_freq The frequecy of learn rate decay for Imagenet. default:30
--weight_decay The weight decay of loss. default:4e-5
--lr_type lr scheduler. default: cos. optional:exp/cos/step/fixed
--use_dali If this parameter exists, use dali module to load ImageNet data (benefit in training acceleration).
--conv_type Importance criterion of filters. Default: BlockL1Conv. optional: BlockRandomConv, DenseConv
--pr_target Pruning rate. default:0.5
--full If this parameter exists, prune fully-connected layer.
--N Consecutive N kernels for removal (see paper for details).
--rearrange If this parameter exists, filters will be rearranged (see paper for details).
--export_onnx If this parameter exists, export onnx model.
2)Filter Rearrangement

Table 2: Performance studies of our 1×N block sparsity with and without filter rearrangement (p=50%).
| N = 2 | Top-1 Acc. | Top-5 Acc. | Model Link |
|---|---|---|---|
| w/o Rearange | 69.900 | 89.296 | Pruned Model |
| Rearrange | 70.233 | 89.417 | Pruned Model |
| N = 4 | Top-1 Acc. | Top-5 Acc. | Model Link |
|---|---|---|---|
| w/o Rearange | 69.521 | 88.920 | Pruned Model |
| Rearrange | 69.579 | 88.944 | Pruned Model |
| N = 8 | Top-1 Acc. | Top-5 Acc. | Model Link |
|---|---|---|---|
| w/o Rearange | 69.206 | 88.608 | Pruned Model |
| Rearrange | 69.372 | 88.862 | Pruned Model |
| N = 16 | Top-1 Acc. | Top-5 Acc. | Model Link |
|---|---|---|---|
| w/o Rearange | 68.971 | 88.399 | Pruned Model |
| Rearrange | 69.352 | 88.708 | Pruned Model |
| N = 32 | Top-1 Acc. | Top-5 Acc. | Model Link |
|---|---|---|---|
| w/o Rearange | 68.431 | 88.315 | Pruned Model |
| Rearrange | 68.762 | 88.425 | Pruned Model |
3)Encoding and Decoding Efficiency
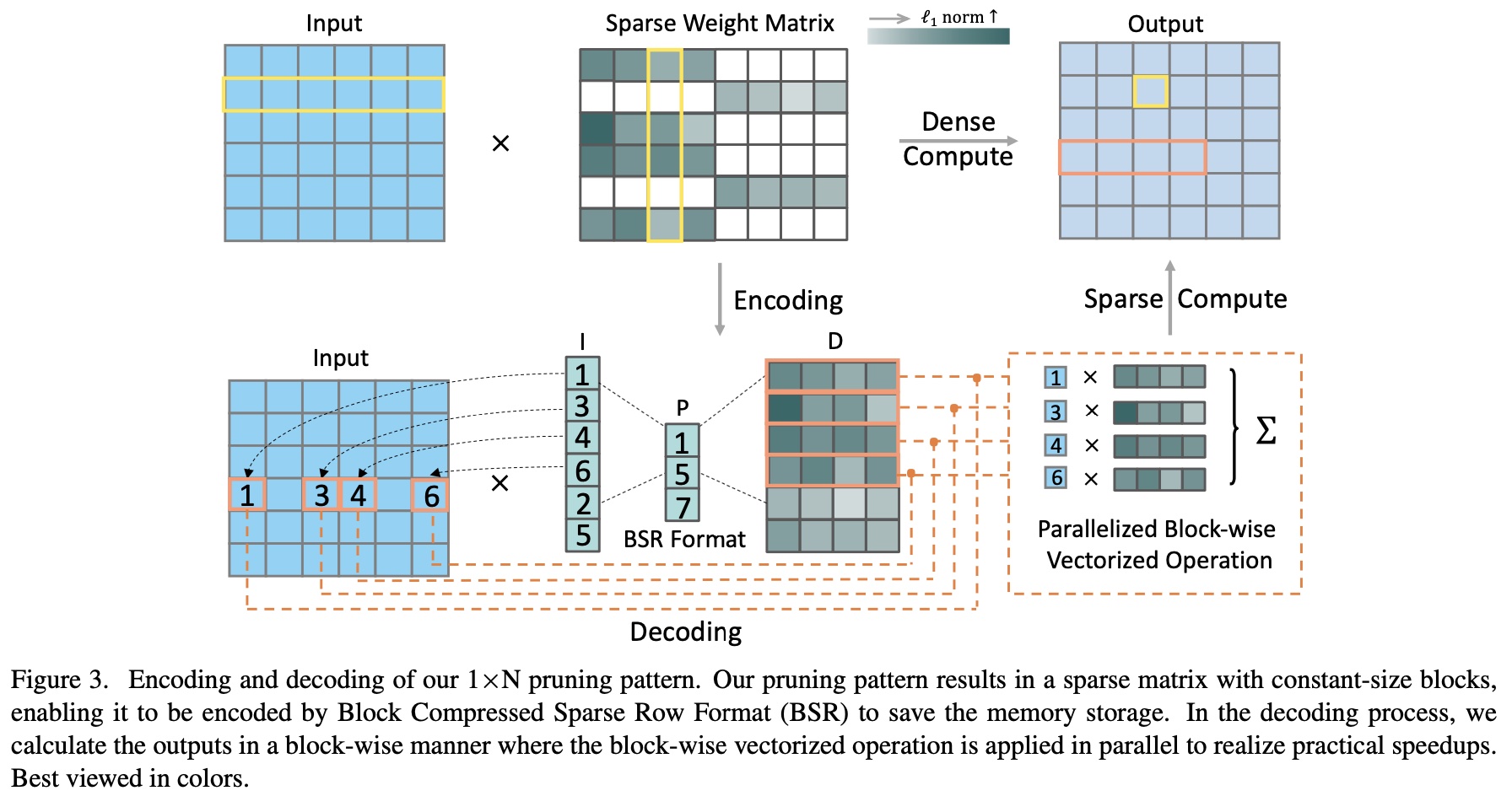
Performance and latency comparison

Our sparse convolution implementation has been released to TVM community.
To verify the performance of our pruned models, convert onnx model and run the following command:
python model_tune.py \
--onnx_path [ONNX_MODEL_PATH] \
--bsr 4 \
--bsc 1 \
--sparsity 0.5
The detail tuning setting is referred to TVM.
4)Contact
Any problem regarding this code re-implementation, please contact the first author: lmbxmu@stu.xmu.edu.cn or the second author: yuxinzhang@stu.xmu.edu.cn.
Any problem regarding the sparse convolution implementation, please contact the third author: xiamenlyc@gmail.com.