TRIO
June 3, 2026 · View on GitHub
This repository is the official implementation of TRIO.
TRIO: Token Reduction via Inference-Objective Guidance for Efficient Vision-Language Models
Haokui Zhang,
Congyang Ou,
Dawei Yan,
Peng Wang,
Qingsen Yan,
Yu Zhang,
Ying Li,
Rong Xiao,
Overall
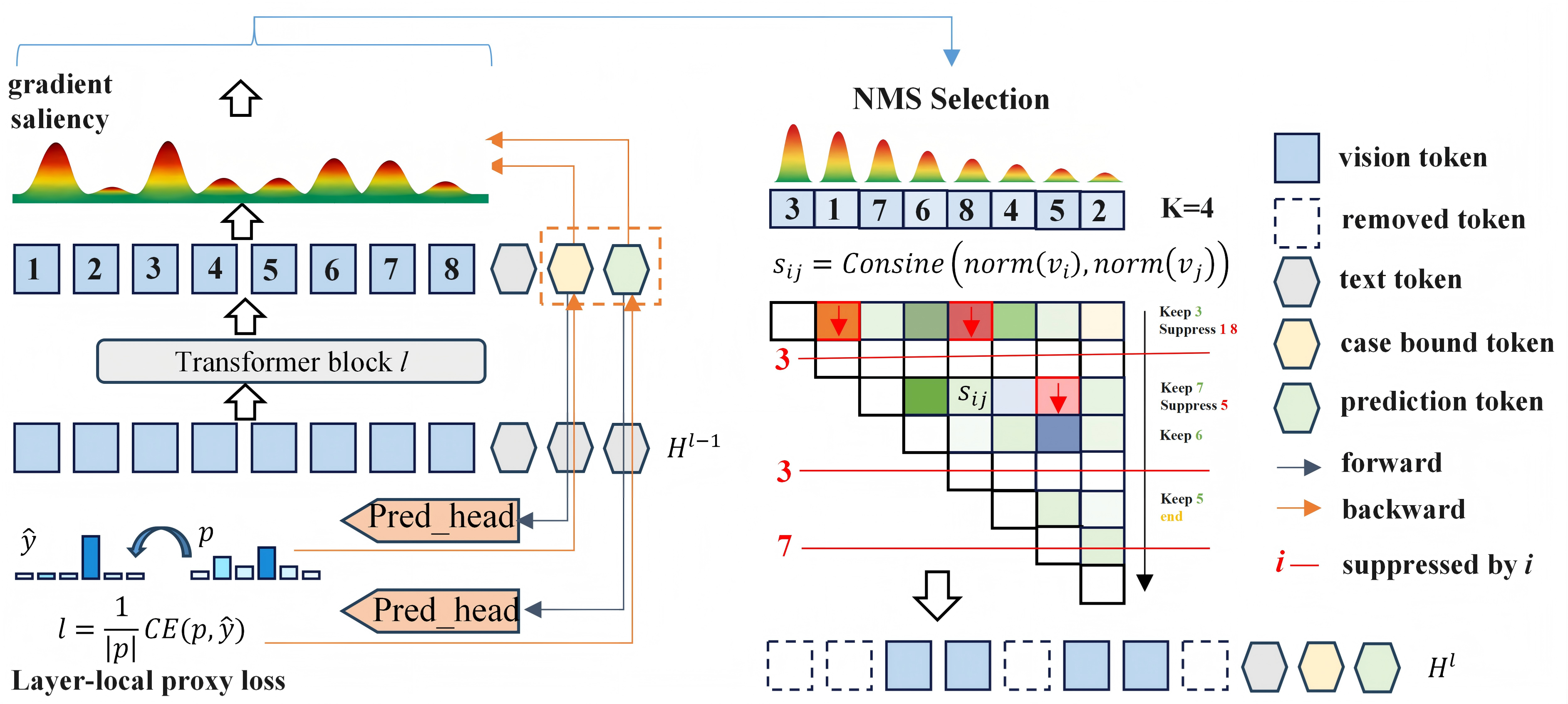
We propose TRIO, a training-free method that selects vision tokens via gradient saliency and a feature-space NMS strategy, improving efficiency while preserving performance and maintaining compatibility with efficient attention operators.
Example

Comparison of different token selection strategies.
Comparison of different token selection strategies. (a) Ours; (b) text-to-image attention based; (c) diversity-oriented selection; (d) CLS-token attention based.
Performance Results
The following table presents a detailed comparison of our method (TRIO) against various state-of-the-art baselines across multiple benchmarks under different token retention budgets.
| Methods | Venue | GQA | MMB | MMB-cn | MME | POPE | SQA | VQAv2 | TextVQA | Average |
|---|---|---|---|---|---|---|---|---|---|---|
| Upper Bound (576 Tokens) | ||||||||||
| Vanilla | – | 61.9 | 64.7 | 58.1 | 1862 | 85.9 | 69.5 | 78.5 | 58.2 | 100% |
| w/o VE (192 Tokens, 33.3%) | ||||||||||
| FastV | ECCV’24 | 52.7 | 61.2 | 57.0 | 1612 | 64.8 | 67.3 | 67.1 | 52.5 | 89.0% |
| PDrop | CVPR’25 | 57.1 | 63.2 | 56.8 | 1766 | 82.3 | 68.8 | 75.1 | 56.1 | 96.2% |
| SparseVLM | ICML’25 | 59.5 | 64.1 | 53.7 | 1787 | 85.3 | 68.7 | 75.6 | 57.8 | 97.2% |
| DART | EMNLP’25 | 60.0 | 63.6 | 57.0 | 1856 | 82.8 | 69.8 | 76.7 | 57.4 | 98.3% |
| TRIO (Ours) | Ours | 61.0 | 64.4 | 57.6 | 1789 | 86.5 | 69.0 | 77.7 | 57.2 | 98.8% |
| w/ VE (192 Tokens, 33.3%) | ||||||||||
| VisionZip | CVPR’25 | 59.3 | 63.0 | 57.3 | 1782 | 85.3 | 68.9 | 76.8 | 57.3 | 97.8% |
| HoloV | NeurIPS’25 | 59.0 | 65.4 | 58.0 | 1820 | 85.6 | 69.8 | 76.7 | 57.4 | 98.7% |
| SCOPE | NeurIPS’25 | 60.1 | 63.6 | 56.8 | 1804 | 86.4 | 68.8 | 77.2 | 57.7 | 98.3% |
| TRIO (Ours) | Ours | 61.1 | 64.2 | 57.9 | 1808 | 86.4 | 68.2 | 77.9 | 57.4 | 98.9% |
| w/o VE (128 Tokens, 22.2%) | ||||||||||
| FastV | ECCV’24 | 49.6 | 56.1 | 56.4 | 1490 | 59.6 | 60.2 | 61.8 | 50.6 | 83.2% |
| PDrop | CVPR’25 | 56.0 | 61.1 | 56.6 | 1644 | 82.3 | 68.3 | 72.9 | 55.1 | 94.0% |
| SparseVLM | ICML’25 | 58.4 | 64.5 | 51.1 | 1746 | 85.0 | 68.6 | 73.8 | 56.7 | 95.6% |
| DART | EMNLP’25 | 58.7 | 63.2 | 57.5 | 1840 | 80.1 | 69.1 | 75.9 | 56.4 | 97.0% |
| TRIO (Ours) | Ours | 60.0 | 62.9 | 57.1 | 1807 | 86.7 | 68.5 | 76.5 | 57.2 | 98.1% |
| w/ VE (128 Tokens, 22.2%) | ||||||||||
| VisionZip | CVPR’25 | 57.6 | 62.0 | 56.7 | 1761.7 | 83.2 | 68.9 | 75.6 | 56.8 | 96.4% |
| HoloV | NeurIPS’25 | 57.7 | 63.9 | 56.5 | 1802 | 84.0 | 69.8 | 75.5 | 56.8 | 97.2% |
| SCOPE | NeurIPS’25 | 59.7 | 62.5 | 56.9 | 1776 | 86.1 | 68.4 | 76.5 | 57.2 | 97.5% |
| TRIO (Ours) | Ours | 60.0 | 62.9 | 56.7 | 1799 | 86.4 | 69.2 | 77.1 | 57.0 | 98.1% |
| w/o VE (64 Tokens, 11.1%) | ||||||||||
| FastV | ECCV’24 | 46.1 | 48.0 | 52.7 | 1256 | 48.0 | 51.1 | 55.0 | 47.8 | 74.0% |
| PDrop | CVPR’25 | 41.9 | 33.3 | 50.5 | 1092 | 55.9 | 68.6 | 69.2 | 45.9 | 74.4% |
| SparseVLM | ICML’25 | 53.8 | 60.1 | 52.7 | 1589 | 77.5 | 69.8 | 68.2 | 53.4 | 90.6% |
| DART | EMNLP’25 | 55.9 | 60.6 | 53.2 | 1765 | 73.9 | 69.8 | 72.4 | 54.4 | 92.8% |
| TRIO (Ours) | Ours | 58.0 | 61.6 | 53.7 | 1681 | 84.3 | 68.5 | 74.8 | 54.9 | 94.7% |
| w/ VE (64 Tokens, 11.1%) | ||||||||||
| VisionZip | CVPR’25 | 55.1 | 60.1 | 55.4 | 1690 | 77.0 | 69.0 | 72.4 | 55.5 | 93.0% |
| HoloV | NeurIPS’25 | 55.3 | 63.3 | 55.1 | 1715 | 80.3 | 69.5 | 72.8 | 55.4 | 94.4% |
| SCOPE | NeurIPS’25 | 58.3 | 61.7 | 54.4 | 1698 | 83.9 | 68.6 | 75.3 | 56.6 | 95.4% |
| TRIO (Ours) | Ours | 58.3 | 61.6 | 56.5 | 1744 | 86.4 | 68.6 | 75.9 | 56.2 | 96.6% |
Note: Base model used is LLaVA-1.5-7B. The baseline "Upper Bound" utilizes all 576 tokens.
Performance Results
Here is the performance comparison of our method against the baseline LLaVA models. Our approach significantly reduces computation overhead (Prefill Time, Total Time, FLOPs, and KV Cache) while maintaining competitive performance on the POPE benchmark.
| Methods | Prefill Time↓ (s) | Total Time↓ (s) | Avg FLOPs↓ (T) | KV Cache↓ (MB) | POPE (Acc) |
|---|---|---|---|---|---|
| LLaVA-1.5-7B | 1401 (1.00×) | 2234 (1.00×) | 2.98 (1.00×) | 318 (1.00×) | 85.9 |
| +Ours(%11.1) | 1106 (1.27×) | 1978 (1.13×) | 0.45 (6.62×) | 62 (5.13×) | 84.3 |
| LLaVA-NEXT-7B | 4934 (1.00×) | 5921 (1.00×) | 16.67 (1.00×) | 1156 (1.00×) | 86.5 |
| +Ours(%11.1) | 1844 (2.67×) | 2810 (2.11×) | 2.68 (6.22×) | 191 (6.05×) | 84.5 |
Note: > *
↓indicates that lower is better.
- Values in parentheses represent the reduction ratio/speedup compared to the respective baseline.
Set Up
LLaVA
- Clone this repository.
git clone https://github.com/ocy1/TRIO
cd TRIO
2.Environment Setup and Preparation
conda activate TRIO
pip install -e .
pip install flash-attn --no-build-isolation
3.Download Multimodal Benchmark Please follow the detailed instruction in https://github.com/haotian-liu/LLaVA/blob/main/docs/Evaluation.md
Qwen2.5-VL
conda create -n TRIO_Qwen25VL python=3.10 -y
conda activate TRIO_Qwen25VL
pip install -U transformers==4.55.4
pip install flash-attn --no-build-isolation
pip install -e .
Usage
LLaVA
For LLaVA-1.5 and LLaVA-NeXT, you can run evaluation with the scripts under scripts/. A typical example is:
python -m llava.eval.model_vqa_loader \
--model-path ../data/model/llava-v1.5-7b \
--question-file ../data/eval/MME/llava_mme.jsonl \
--image-folder ../data/eval/MME/MME_Benchmark_release_version/MME_Benchmark \
--answers-file ../data/eval/MME/answers/llava-v1.5-7b.jsonl \
--temperature 0 \
--layer_list '[16]' \
--image_token_list '[32]' \
--visual_token_num 96 \
--conv-mode vicuna_v1
Please replace --model-path with your own checkpoint path. --question-file specifies the evaluation file, --image-folder should point to the corresponding image directory, and --answers-file is the path used to save model predictions.
The pruning behavior is mainly controlled by --layer_list, --image_token_list, and --visual_token_num. By default, we use:
--layer_list '[16]'--image_token_list '[32]'--visual_token_num 96
This means 96 visual tokens are kept after the visual encoder, and then reduced to 32 at the 16th LLM layer. Under this setting, the model maintains an average of 64 visual tokens across all 32 layers.
Both --layer_list and --image_token_list support multiple entries. For example, you may set:
--layer_list '[8,16]' --image_token_list '[188,96]'
to perform progressive pruning at multiple layers, similar to PyramidDrop-style scheduling.
Qwen2.5-VL
For Qwen2.5-VL, the evaluation command is:
python -m qwen.eval.model_vqa_loader \
--model-path ../data/model/Qwen2.5-VL-7B-Instruct \
--question-file ../data/eval/MME/llava_mme.jsonl \
--image-folder ../data/eval/MME/MME_Benchmark_release_version/MME_Benchmark \
--answers-file ../data/eval/MME/answers/Qwen2.5-VL-7B-Instruct.jsonl \
--temperature 0 \
--layer-list '[14]' \
--image-token-ratio-list '[0.333]' \
--image-token-ratio 0.167
Since Qwen2.5-VL uses dynamic-resolution visual encoding, the number of visual tokens varies across images. Therefore, ratio-based settings are used instead of fixed token counts.
By default:
--image-token-ratio 0.167keeps 16.7% of visual tokens after visual encoding--image-token-ratio-list '[0.333]'further reduces them to 33.3% at the 14th LLM layer
This results in an average visual token retention ratio of 11.1% across the 28 LLM layers.
Citation
If you find our work helpful or use our code in your research, please consider citing our paper:
@misc{zhang2026triotokenreductioninferenceobjective,
title={TRIO: Token Reduction via Inference-Objective Guidance for Efficient Vision-Language Models},
author={Haokui Zhang and Congyang Ou and Dawei Yan and Peng Wang and Qingsen Yan and Yu Zhang and Ying Li and Rong Xiao},
year={2026},
eprint={2602.04657},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2602.04657},
}