lora.md
June 19, 2025 · View on GitHub
LORA
LoRA(Low-Rank Adaptation)是一种用于微调大型预训练模型的技术,旨在高效地适应特定任务,同时减少计算和存储开销。
LoRA的核心思想 核心思想是将原始模型的权重矩阵(部分或全部)分解为低秩矩阵,并训练这些矩阵。
只更新少量参数,而不是整个模型,从而减少计算和存储需求。
如图所示,底部网络表示大型预训练模型,而顶部网络表示带有 LoRA 层的模型。
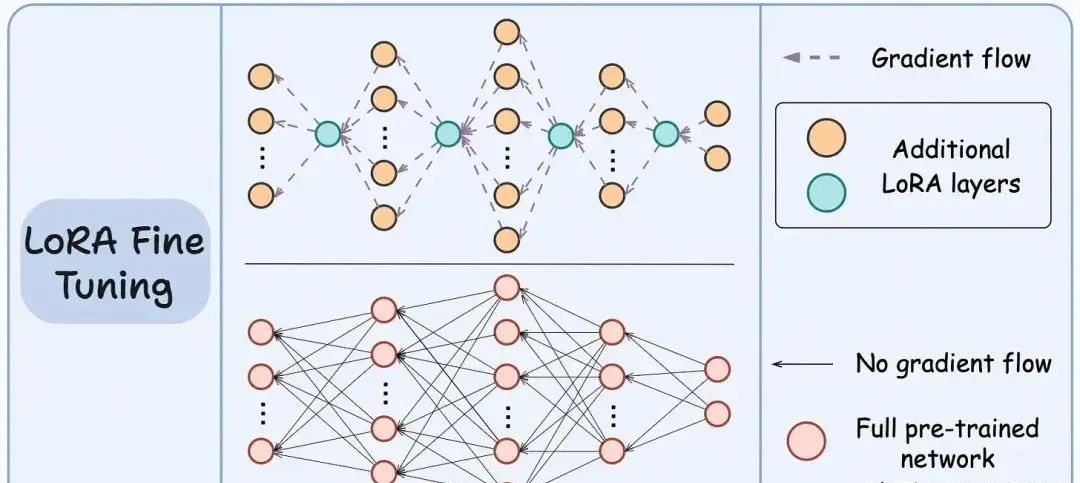
其核心思想是只训练 LoRA 网络,而冻结大型模型。
LORA 的效果会好于其它几种方法。其它方法都有各自的一些问题:
- Adapter Tuning 增加了模型层数,引入了额外的推理延迟
- Prefix-Tuning 难于训练,且预留给 Prompt 的序列挤占了下游任务的输入序列空间,影响模型性能
- P-tuning v2 很容易导致旧知识遗忘,微调之后的模型,在之前的问题上表现明显变差
LORA原理
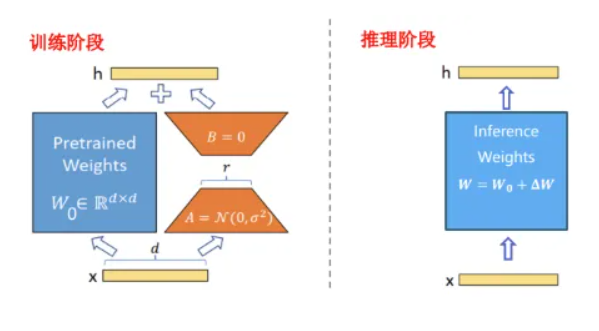
- Lora在不改变模型推理结构的条件下,直接调整少量参数。
- 参数的变化量△W 通常是参数冗余的,使用低秩近似可以很好地表达。
- 普适性强,可以微调任意模型中的线性层。
LORA流程

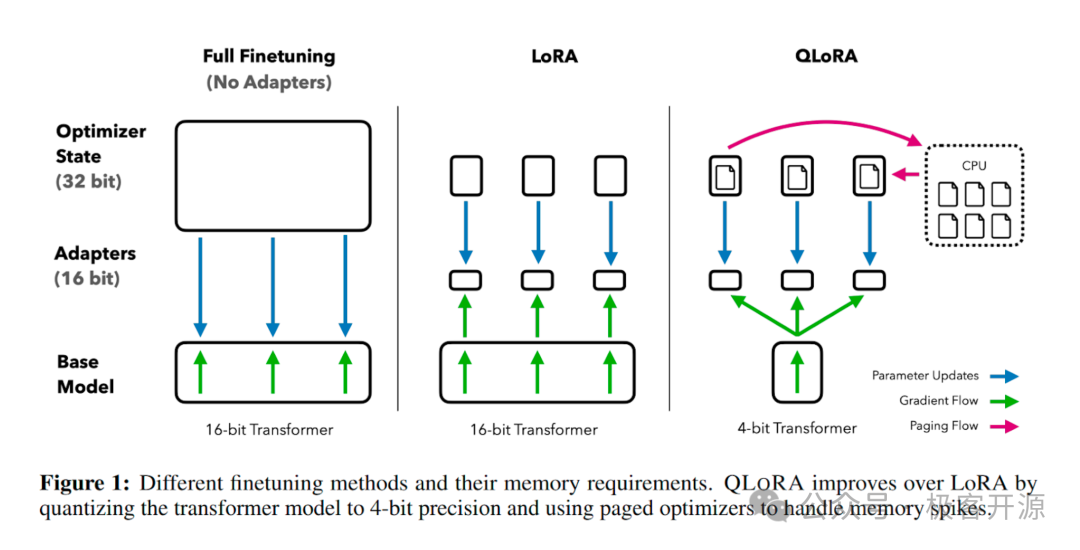
QLoRA:在消费级显卡上微调巨型模型
QLoRA (Quantized LoRA) 是 LoRA 的一个重要变种,它将高精度计算与低精度存储相结合,旨在用极限的显存资源微调超大规模的模型。
QLoRA 的工作原理
QLoRA 的成功秘诀在于三大创新:
-
4-bit NormalFloat (NF4): 一种信息论上最优的新型 4 位数据类型,用于精确地量化模型权重。
-
双重量化 (Double Quantization): 对量化过程中产生的"量化常数"本身再次进行量化,进一步压缩模型大小,平均每个参数能节省约 0.5 比特。
-
分页优化器 (Paged Optimizers): 利用 NVIDIA 统一内存特性,防止在处理长序列时因梯度检查点而导致的内存不足(OOM)问题。
其核心流程是:
-
加载时量化: 将预训练好的大模型(例如 FP16 精度)的权重在加载到显存时,动态量化为极低精度的 4-bit 格式。这使得一个 65B 的模型能从 130GB 压缩到仅 35GB 左右。
-
训练时反量化: 在进行前向和后向传播计算时,将所需的权重动态地"反量化"回 BFloat16 等较高精度格式,并与同样保持较高精度的 LoRA 适配器权重进行计算。
-
误差补偿: 虽然量化会引入微小的误差,但 QLoRA 的巧妙之处在于,LoRA 适配器在训练过程中会自动学习并补偿这些量化误差。
最终结果是,您可以在一个 24GB VRAM 的消费级显卡(如 RTX 4090)上,微调一个 33B 甚至 65B 的大模型,而性能几乎与全量微调无异。 使用 HuggingFace 实现 QLoRA
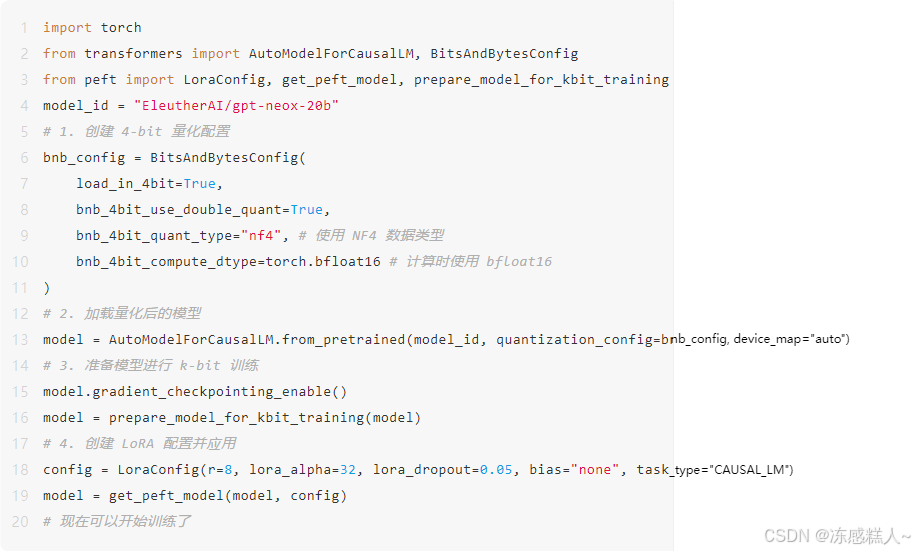
实现 QLoRA 需要 peft, transformers 和 bitsandbytes 库。
LoRA 的其他重要变体
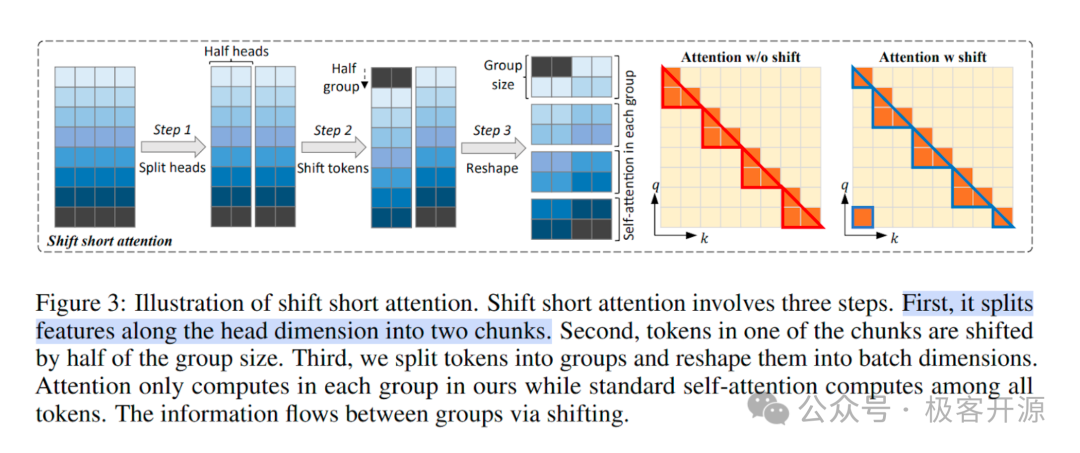
LongLoRA: 专为处理长文本而设计。它通过一种"位移短注意力"(Shift Short Attention)机制,将注意力计算分散到不同的 token 组中,从而高效地扩展模型的有效上下文窗口。
AdaLoRA: 自适应 LoRA。它认为不同层的重要性不同,因此不应分配相同的秩 r。AdaLoRA 可以在训练中动态地将参数预算(即秩)分配给更重要的层,从而在有限的参数下实现更好的性能。
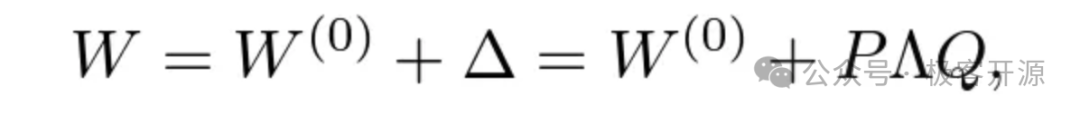
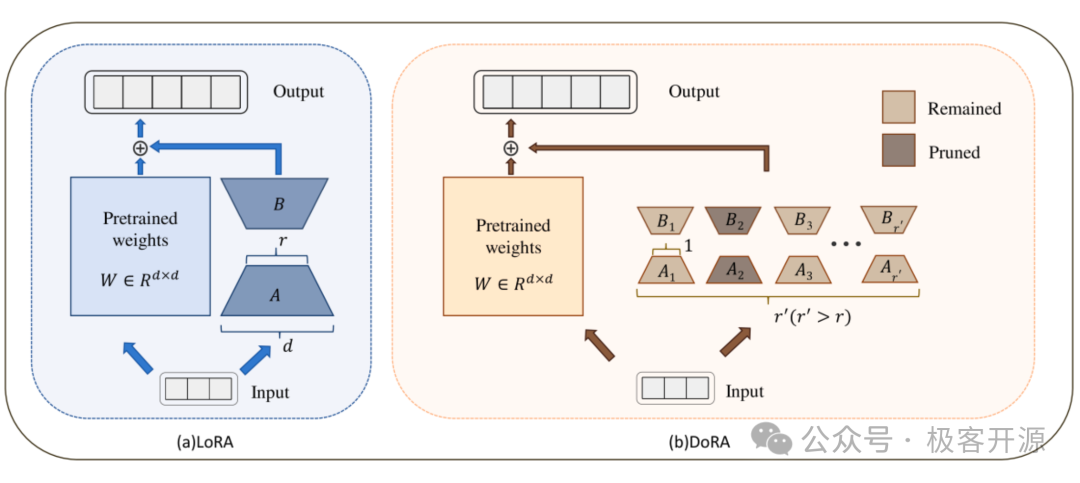
DoRA: 将权重分解为"大小"和"方向"两个部分,并只对"方向"部分进行 LoRA 微调。这被证明是一种更稳定、更高效的训练方式,通常能以更小的秩达到比 LoRA 更好的效果。在PEFT库中,只需在LoraConfig 中设置 use_dora=True 即可启用。
如何选择适合您的微调方案?
面对如此多的选择,您可能会感到困惑。别担心,下面的决策指南将帮助您快速找到最适合的方案。核心在于评估您的主要目标和资源限制。
决策要点解读
- 通用与高效的首选:LoRA
如果您是初次尝试,或者希望在合理的资源下高效完成微调,LoRA 是最理想的起点。它是平衡性能和效率的最佳选择。
- 显存极限挑战者:QLoRA
如果您的核心痛点是显存不足(例如,模型无法加载,或者 batch_size 只能设为 1),请毫不犹豫地选择 QLoRA。它就是为解决显存瓶颈而生的。
- 特定任务优化:
处理长文本: 如果您的任务涉及长篇文档分析、书籍摘要等,LongLoRA 是专门的解决方案。
追求极致性能: 当您对模型性能有极致追求,希望在 LoRA/QLoRA 的基础上更进一步时,可以尝试 AdaLoRA 或 DoRA。它们能更智能地分配参数,通常只需在配置中修改一个参数即可启用,值得一试。