sft.md
June 19, 2025 · View on GitHub
SFT
预训练模型:如DeepSeek、BERT、GPT等,已在大量数据上训练,具备广泛的语言理解能力。
微调:为适应特定任务,通常需要对整个模型进行微调,但这种方法计算和存储成本高。
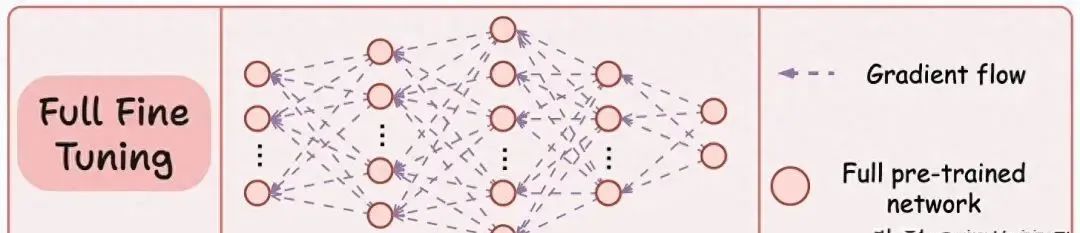
虽然这种微调技术已经成功使用了很长时间,但在用于更大的模型时——例如大语言模型(LLM),就会出现问题,主要因为:
- 模型的大小。
- 微调所有权重的成本。
- 维护所有微调后的大模型的成本。
June 19, 2025 · View on GitHub
SFT
预训练模型:如DeepSeek、BERT、GPT等,已在大量数据上训练,具备广泛的语言理解能力。
微调:为适应特定任务,通常需要对整个模型进行微调,但这种方法计算和存储成本高。
虽然这种微调技术已经成功使用了很长时间,但在用于更大的模型时——例如大语言模型(LLM),就会出现问题,主要因为: