ViT
July 28, 2025 · View on GitHub
一、模型架构
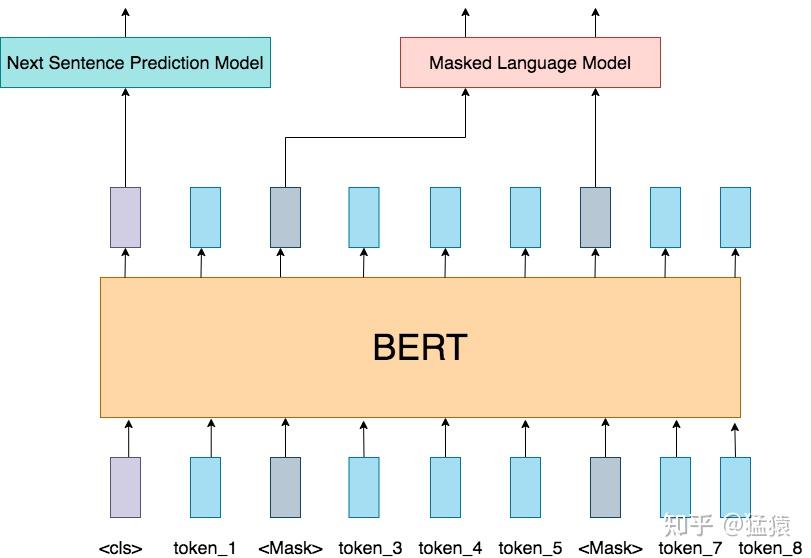
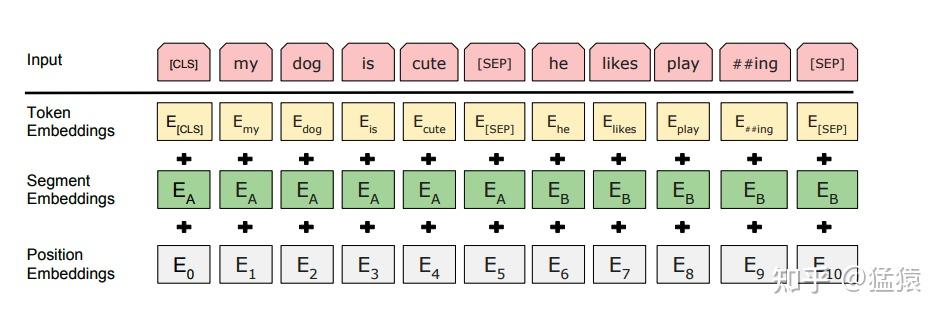
前面说过,VIT几乎和Bert一致,我们来速扫一下Bert模型:
-
input:输入是一条文本。文本中的每个词(token)我们都通过embedding把它表示成了向量的形式。、
-
训练任务:在Bert中,我们同时做2个训练任务:
- Next Sentence Prediction Model(下一句预测):input中会包含两个句子,这两个句子有50%的概率是真实相连的句子,50%的概率是随机组装在一起的句子。我们在每个input前面增加特殊符
<cls>,这个位置所在的token将会在训练里不断学习整条文本蕴含的信息。最后它将作为“下一句预测”任务的输入向量,该任务是一个二分类模型,输出结果表示两个句子是否真实相连。 - Masked Language Model(遮蔽词猜测):在input中,我们会以一定概率随机遮盖掉一些token(
<mask>),以此来强迫模型通过Bert中的attention结构更好抽取上下文信息,然后在“遮蔽词猜测”任务重,准确地将被覆盖的词猜测出来。
- Next Sentence Prediction Model(下一句预测):input中会包含两个句子,这两个句子有50%的概率是真实相连的句子,50%的概率是随机组装在一起的句子。我们在每个input前面增加特殊符
-
Bert模型:Transformer的Encoder层。
VIT模型架构
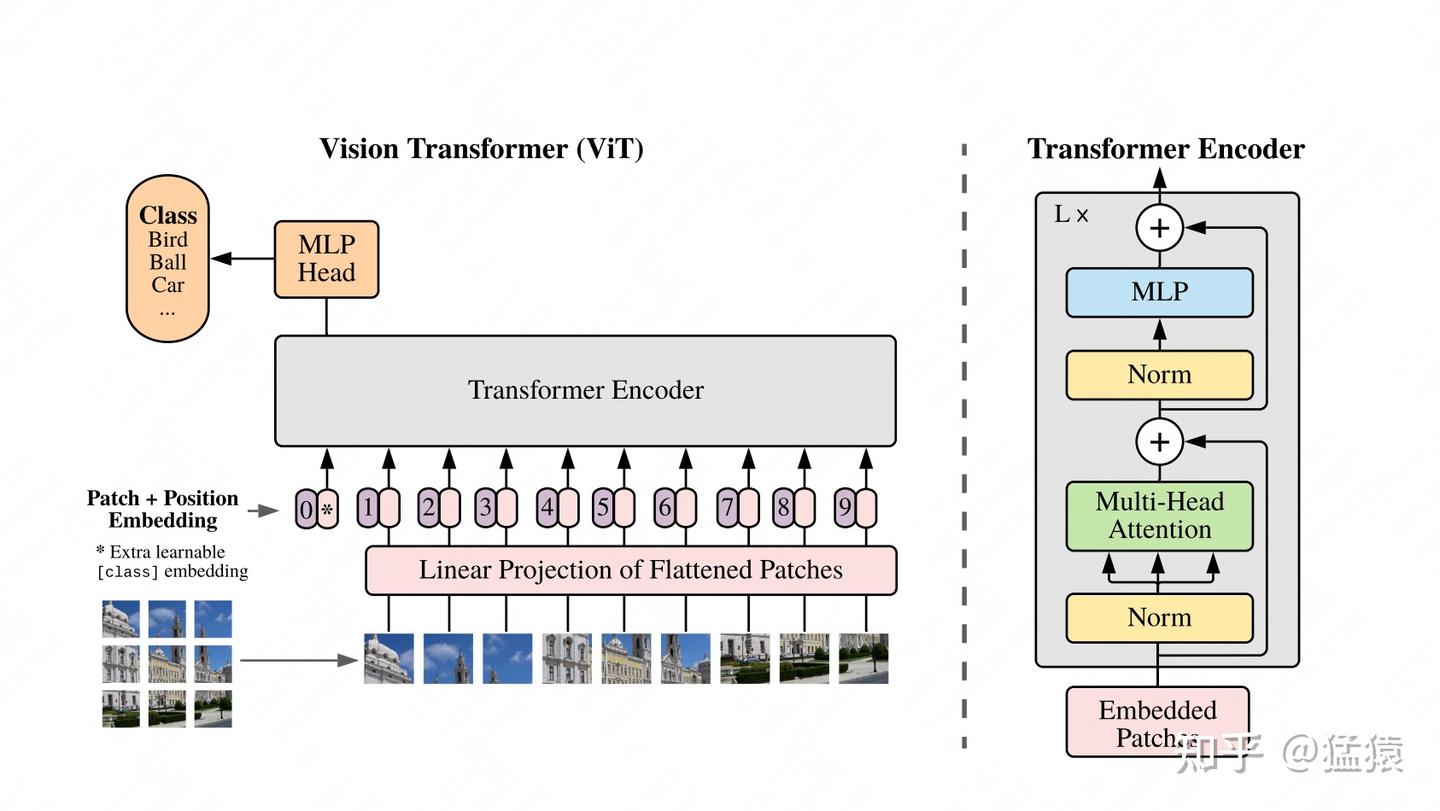
我们先来看左侧部分。
- Patch:对于输入图片,首先将它分成几个patch(例如图中分为9个patch),每个patch就类似于NLP中的一个token(具体如何将patch转变为token向量,在下文会细说)。
- Position Embedding:每个patch的位置向量,用于指示对应patch在原始图片中的位置。和Bert一样,这个位置向量是learnable的,而并非原始Transformer中的函数式位置向量。同样,我们会在下文详细讲解这一块。
- Input: 最终传入模型的Input = patching_emebdding + position embedding,同样,在输入最开始,我们也加一个分类符
<cls>,在bert中,这个分类符是作为“下一句预测”中的输入,来判断两个句子是否真实相连。在VIT中,这个分类符作为分类任务的输入,来判断原始图片中物体的类别。
右侧部分则详细刻画了Transformer Encoder层的架构,它由L块这样的架构组成。图片已刻画得很详细,这里不再赘述。
总结起来,VIT的训练其实就在做一件事:把图片打成patch,送入Transformer Encoder,然后拿<cls>对应位置的向量,过一个简单的softmax多分类模型,去预测原始图片中描绘的物体类别即可。
你可能会想:“这个分类任务只用一个简单的softmax,真得能分准吗?”其实,这就是VIT的精华所在了:VIT的目的不是让这个softmax分类模型强大,而是让这个分类模型的输入强大。这个输入就是Transformer Encoder提炼出来的特征。分类模型越简单,对特征的要求就越高。
所以为什么说Transformer开启了大一统模型的预训练大门呢?主要原因就在于它对特征的提炼能力——这样我们就可以拿这个特征去做更多有趣的任务了。这也是VIT能成为后续多模态backbone的主要原因。
二、从patch到token
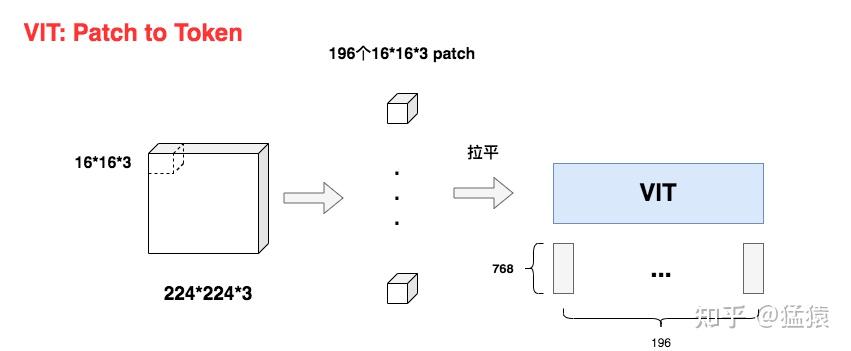
如图,假设原始图片尺寸大小为:224*224*3 (H * W * C)。
现在我们要把它切成小patch,每个patch的尺寸设为16(P=16),则每个patch下图片的大小为16*16*3。
则容易计算出共有 个patch。
不难看出每个patch对应着一个token,将每个patch展平,则得到输入矩阵X,其大小为(196, 768),也就是每个token是768维。
通过这样的方式,我们成功将图像数据处理成自然语言的向量表达方式。
好,那么现在问题来了,对于图中每一个16\*16\*3的小方块,我要怎么把它拉平成1\*768维度的向量呢?
比如说,我先把第一个channel拉成一个向量,然后再往后依次接上第二个channel、第三个channel拉平的向量。但这种办法下,同一个pixel本来是三个channel的值共同表达的,现在变成竖直的向量之后,这三个值的距离反而远了。基于这个原因,你可能会想一些别的拉平方式,但归根究底它们都有一个共同的问题:太规则化,太主观。
所以,有办法利用模型来做更好的特征提取吗?当然没问题。VIT中最终采用CNN进行特征提取,具体方案如下:
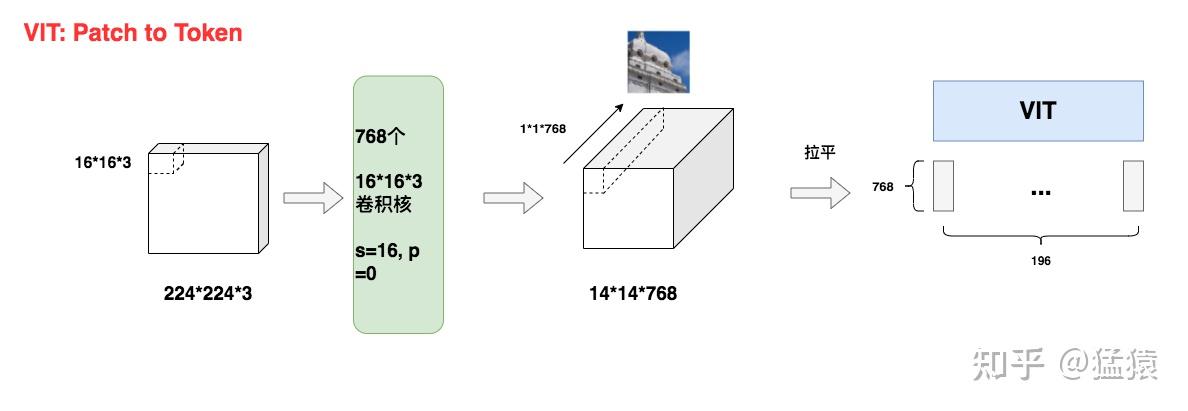
第一个原因,是为了减少模型计算量。 在Transformer中,假设输入的序列长度为N,那么经过attention时,计算复杂度就为 ,因为注意力机制下,每个token都要和包括自己在内的所有token做一次attention score计算。 在VIT中, ,当patch尺寸P越小时,N越大,此时模型的计算量也就越大。因此,我们需要找到一个合适的P值,来减少计算压力。
第二个原因,是图像数据带有较多的冗余信息。 和语言数据中蕴含的丰富语义不同,像素本身含有大量的冗余信息。比如,相邻的两个像素格子间的取值往往是相似的。因此我们并不需要特别精准的计算粒度(比如把P设为1)。这个特性也是之后MAE,MoCo之类的像素级预测模型能够成功的原因之一。
三、Emebdding
如下图,我们知道在Bert(及其它NLP任务中): 输入 = token_embedding(将单个词转变为词向量) + position_embedding(位置编码,用于表示token在输入序列中的位置) + **segment_emebdding(**非必须,在bert中用于表示每个词属于哪个句子)。 在VIT中,同样存在token_embedding和postion_emebedding。
3.1 Token Emebdding
我们记token emebdding为E ,则E是一个形状为(768, 768)的矩阵。
由前文知经过patch处理后输入X的形状为(196, 768),则输入X过toke_embedding后的结果为:
**你可能想问,输入X本来就是一个(196,768)的矩阵啊,我为什么还要过一次embedding呢?**这个问题的关键不在于数据的维度,而在于embedding的含义。原始的X仅是由数据预处理而来,和主体模型毫无关系。而token_embedding却参与了主体模型训练中的梯度更新,在使用它之后,能更好地表示出token向量。更进一步,E的维度可以表示成(768, x)的形式,也就是第二维不一定要是768,你可以自由设定词向量的维度。
3.2 Position Embedding(位置向量)
在NLP任务中,位置向量的目的是让模型学得token的位置信息。在VIT中也是同理,我们需要让模型知道每个patch的位置信息(参见1.2中架构图)。
我们记位置向量为 ,则它是一个形状为(196,768)的矩阵,表示196个维度为768的向量,每个向量表示对应token的位置信息。
构造位置向量的方法有很多种,在VIT中,作者做了不同的消融实验,来验证不同方案的效果(论文附录D.4)部分,我们来详细看看,作者都曾尝试过哪些方案。
方案一: 不添加任何位置信息
将输入视为一堆无序的patch,不往其中添加任何位置向量。
方案二:使用1-D绝对位置编码
也就是我们在上文介绍的方案,这也是VIT最终选定的方案。 1-D绝对位置编码又分为函数式(Transformer的三角函数编码,详情可参见这篇文章)和可学习式(Bert采用编码方式),VIT采用的是后者。之所以被称为“绝对位置编码”,是因为位置向量代表的是token的绝对位置信息(例如第1个token,第2个token之类)。
方案三:使用2-D绝对位置编码
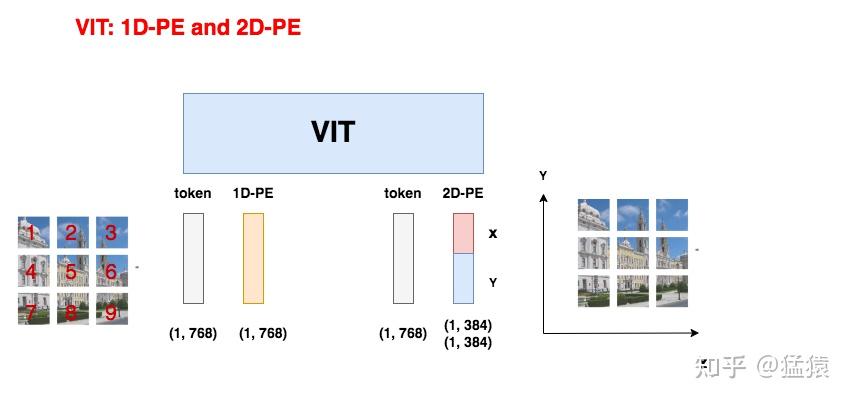
如图所示,因为图像数据的特殊性,在2-D位置编码中,认为按全局绝对位置信息来表示一个patch是不足够的(如左侧所示),一个patch在x轴和y轴上具有不同含义的位置信息(如右侧所示)。因此,2-D位置编码将原来的PE向量拆成两部分来分别训练。
方案四:相对位置编码(relative positional embeddings)
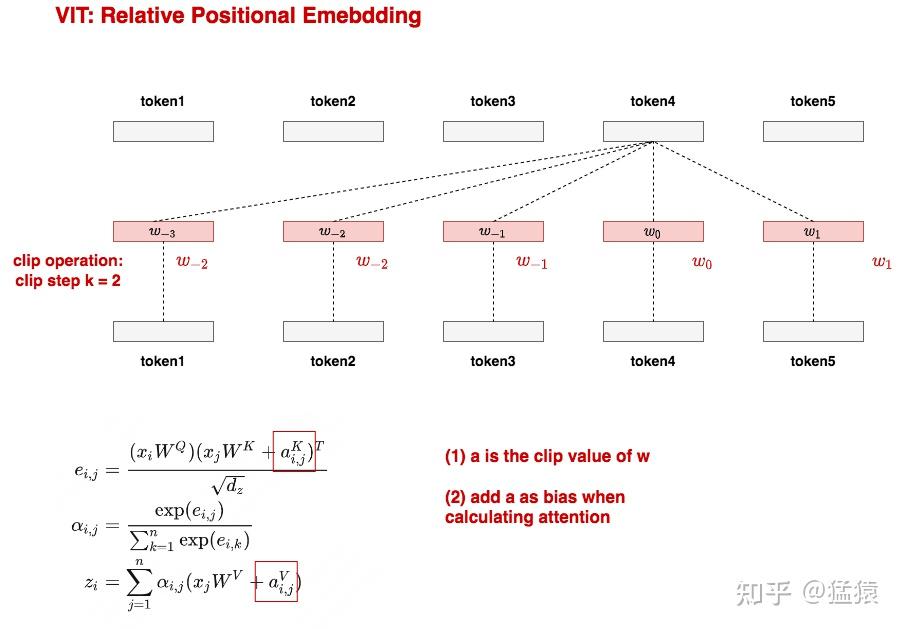
相对位置编码(RPE)的设计思想是:我们不应该只关注patch的绝对位置信息,更应该关注patch间的相对位置信息。如图所示,对于token4,它和其余每一个token间都存在相对位置关系,我们分别用 这5个向量来表示这种位置关系。
那么接下来,只要在正常计算attention的过程中,将这5个向量当作bias添加到计算过程中(如图公式所示),我们就可以正常训练这些相对位置向量了。为了减少训练时的参数量,我们还可以做clip操作,在制定clip的步数k之后,在k范围之外的w我们都用固定的w表示。例如图中当k=2时,向token4的前方找,我们发现 已经在k=2步之外了,因此就可以用 来替代 ,如果token1之前还有token,那么它们的w都可用 替代。向token4的后方找,发现大家都在k=2步之内,因此无需做任何替换操作。
四、模型架构的数学表达
到这一步位置,我们已基本将VIT的模型架构部分讲完了。结合1.2中的模型架构图,我们来用数学语言简练写一下训练中的计算过程:
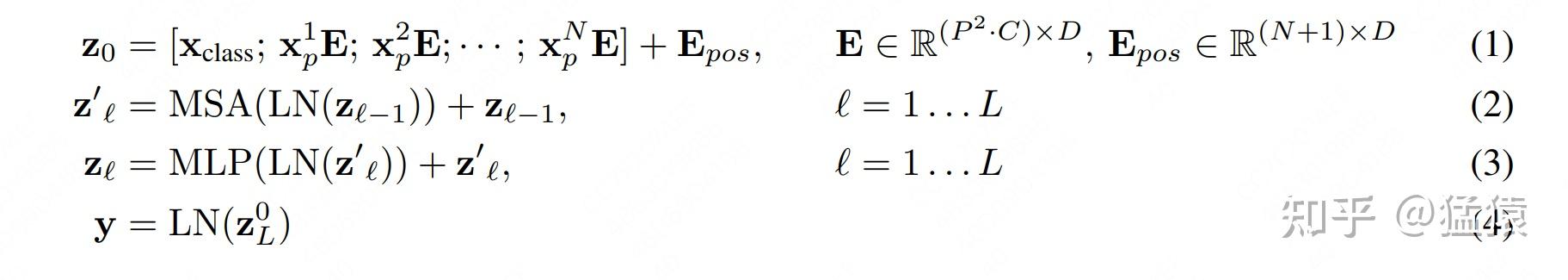
(1)即是我们说的图像预处理过程:
- :第i块patch
- :Token Embedding,1-D Positional Embedding
- :和Bert类似,是额外加的一个分类头
- :最终VIT的输入
(2)即是计算multi-head attention的过程,(3)是计算MLP的过程。
(4)是最终分类任务,LN表示是一个简单的线性分类模型, 则是<cls>对应的向量