best-ksfen-xiang-fang-fa.md
October 23, 2022 · View on GitHub
Best-KS分箱方法是一种自顶向下的分箱方法。与卡方分箱相比,Best-KS分享方法只是目标函数采用了KS统计量,其余分箱步骤没有差别。这里介绍KS统计量的计算方法与目标变量之间的关系。
KS统计量用于评估模型对好坏样本的区分能力。K-S曲线的绘制方法:做变量排序,以变量的某个值为阈值点,统计样本中好坏样本占总样本中的好坏样本分别的比例。随着变量阈值点的变化,这两个比值也随之改变,这两个比值之差的最大值就是KS统计量。
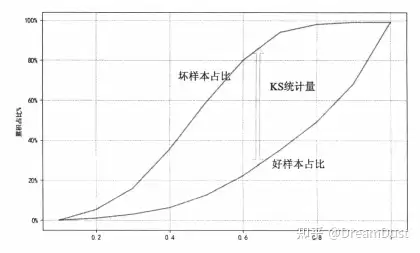
如果采用模型预测的概率值排序,分别计算在不同概率下好坏样本的累计比,所得到的K-S曲线与K-S统计量就可以用来衡量模型的预测效果。如果横坐标是变量排序后的变化值,纵坐标为不同变量取值下的好坏样本数与总体样本中好坏样本数的比,那么此时的K-S曲线与K-S统计量就可以用来评估变量分箱中的最优切分点。
K-S统计量的计算过程如下:
1)将变量进行升序排序,确定初始化阈值点候选集,离散变量可以直接采用变量的可能取值作为候选集,连续变量可以先进行分组,如分10组,将每组的边界作为阈值点。
2)分别计算在小于阈值点的样本中,好坏样本与总体好坏样本数的比值。
3)将好坏样本比值的差作为各个切分点的KS统计值。
Best-KS分享方法不适用于不可排序的离散变量,因为排序没有意义,该方法更适合连续变量的分箱过程。此外,Best-KS方法只能对二分类问题进行分箱操作,基于这些局限性在变量处理的时候需要留意。