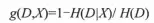ji-yu-shu-de-zui-you-fen-xiang-fang-fa.md
October 23, 2022 · View on GitHub
基于树的分箱方法借鉴了决策树在树生产的过程中特征选择(最优分裂点)的目标函数来完成变量分箱过程,可以理解为单变量的决策树模型。决策树采用自顶向下的方法进行树的生成,每个节点的选择目标是为了分了结果的纯度更高,也就是样本的分类效果更好。因此不同的损失函数有不同的决策树,ID3采用信息增益方法,C4.5采用信息增益比,CART采用基尼系数(Gini)指标。这里主要介绍采用信息增益作为目标函数进行变量分箱的过程。
概率是表示随机变量确定性的度量,而信息是随机变量不确定性的度量。信息熵是不确定性度量的平均值,就是信息平均值。定义为:
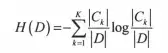
其中k表示类别个数,Ck表示在第k个类别的样本数,D表示样本总数。严格来说这属于经验熵。
熵与纯度对应,熵越大不确定度越大,纯度越低。熵越小不确定度越小,纯度越高。纯度就是类别的多少,只有一种类别纯度最高,所以在对一直变量进行分箱时,如果在某个切分点进行分箱,使得变量的信息熵下降,则得到最佳分箱切分点,衡量信息熵下降的指标就是信息增益。定义为:
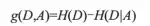
其中H(D)表示原始数据集中类别属性的不确定性;H(D|A)为条件熵,表示变量在某一切分点下分箱后类别属性的不确定性。信息增益表示变量在某一切分点下分箱后对得知类别属性的信息不确定性减少的程度,也就是类别属性纯度增加的程度。在样本给定后,原始数据集中类别属性的信息熵H(D)就已经确定了,分箱调整的是在不同的切分点处得到的条件熵不同,将那些条件熵小的切分点作为最优切分点完成分箱。条件熵的计算公式如下:
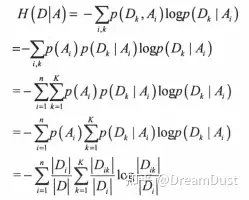
其中n表示变量分箱的个数。注意在最优切分点选择时,每次切分为2箱,此时n=2;而经过多次切分后得到多个箱,此时要评估当前分箱数下的条件熵,则此时n等于到当前时刻的分箱数。Di表示第i个划分中样本个数,D表示样本总数;K表示类别种类,本例中为二分类K=2。
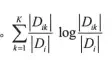
表示变量在第i个分类下的信息熵,即计算在某个切分点分箱后,每个箱内类别属性的信息熵,然后再与该箱内样本数与总体样本数的比值相乘后做加权求和。其中还Dik表示第i个划分下第K个类别的样本数,Di表示第i个划分下的总样本数。
信息增益越大,表示本次分箱下样本类别属性的不确定性越小,纯度越高,对好坏样本的分类效果越好。如果能通过分箱的方式将好坏样本完美地分开,那么这就是最好的分箱结果。
可以将公式两边都除以类别的信息熵,类似归一化的过程,信息增益的公式就变换为如下无量纲的形式: