zui-you-qia-fang-fen-xiang-fa.md
October 23, 2022 · View on GitHub
Chi-merge卡方分箱方法是一种自底向上的分箱方法,其思想是将原始数据初始化为多个数据区间,并对相邻区间的样本进行合并,计算合并后的卡方值,用卡方值的大小衡量相邻区间中类分布的差异情况。如果卡方值较小,表面该相邻区间的类分布情况非常相似,可以进行区间合并;反之,卡方值越大,则表面该相邻区间的类分布情况不同,不能进行区间合并操作。卡方值计算公式如下:
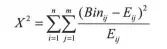
其中n表示区间数,因为是相邻区间进行合并,所以n=2;m表示类别数,如二分类m=2。Eij表示第i个区间第j个类别的期望值,计算方式是第j个类别在总体样本中的占比乘以第i个区间的全部样本数。Binij表示第i个区间第j类样本的个数。
假设样本总数为1000,坏样本与好样本的样本量分别为300和700,计算如图:
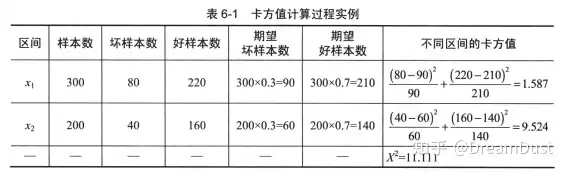
上述过程就是一个卡方检验的过程,因此,根据置信度和自由度可以计算出卡方检验的阈值,当计算的卡方值小于阈值,则认为相邻区间的类分布情况相似,可进行合并。其中自由度为类别个数减1,置信度可以用0.9、0.95和0.99。
另外计算两个卡方值,两者相加即为合并后样本的卡方值。在卡方分箱合并的使用中,每个卡方值都是在检验该区间的类分布情况与总体样本的类分布情况是否相同,卡方值只是衡量这种相似程度的一个量化表示,而两个区间可以合并的前提就是:每个区间的类分布情况都与总体相似,合并后的类分布情况也将与总体的样本分布情况相似,因此可以合并。如果一个区间与总体的类分布情况相似而另一个区间与总体的类分布情况不想死,加和后的卡方值将更大,就不能将这两个区间进行合并。
自底向上的思想是由多至少逐层合并的过程,自顶向下是有少至多逐层切分的过程。为了统一要将卡方自底向上的思想改为自顶向下的方式实现。因此只需要每次切分时令卡方值最大即可(后续采用这种方法)。
在实际进行分箱操作时,如果采用阈值判断的方式,如果不加限制可能导致结果不收敛,从而得到的分箱数太多而失去分箱的意义。因此,实际引用时往往要限制最大分箱数。
基于分箱流程,卡方分箱方法就是目标函数是卡方值,在一定约束条件下的优化问题,约束条件可以自由选择不需要全部使用。根据卡方值的计算公式可知,该方法既可以在二分类问题中,也可以用于多分类中进行变量分箱,同时,对离散变量和连续变量也均适用。