guo-lv-fa.md
October 23, 2022 · View on GitHub
过滤法变量选择是一种与模型无关的变量选择方法,先进行变量选择得到入模变量,再进行模型训练。整个变量选择过程与所采用哪种模型无关,变量选择的过程只是从变量自身的预测能力处罚。过滤法变量选择进一步分解可以分为单变量选择、多变量选择、有监督选择与无监督选择。
既然过滤法变量选择与模型无关,就要尽量从变量的预测能力及对标签的区分能力考虑,因此,任何可以反映或衡量变量预测能力的指标都可以用于变量选择。这样的指标有信息增益、信息增益比、基尼系数和IV值等。从数据源角度考虑:缺失值情况和变量自身的方差情况也可以进行变量选择。从相关性角度考虑:要求最大相关、最小冗余,即变量与标签之间要尽可能相关性较高,而变量与变量之间要尽可能没有相关性,即没有多重共线性问题。
1、数据缺失情况变量筛选
弱某个变量有过多的缺失值,则在模型训练中不会起太大作用,一般缺失值大于80%就应该将该变量删除。但具体要看实际的数据情况,如果数据源的属性非常少,则可以自行将该标准放宽。另外,还有这样的考虑:在变量分箱或WOE编码时,将缺失值作为特征进行编码了,这里为什么非要删除缺失值较多的变量?使得,缺失值确实作为特征进行了编码,而且在评分卡模型中缺失值是非常重要的特征。但是需要变量选择表示我们有很多变量可用,并且评分卡模型最后只要求10-20个变量,而缺失值本身就是一种不确定性,因此那些缺失情况较多的变量不需要保留。而且缺失值的产生原因很多,如果是因为数据源不同而在做多表关联时产生了更多的缺失值,这时的缺失值和没有合并前的缺失值是完全不同意义的缺失值,所以缺失值问题还是需要考虑的。
2、方差变量筛选
一般我们希望输入变量与标签变量具有一定相关性,这种相关性可以直接计算输入变量与标签变量之间的相关系数来衡量,也可以从变量自身来衡量。从变量自身衡量就可以考虑方差这一统计量,标签一定是变化的,至少是一个二分类问题,我们希望输入变量的方差不要过小,过小的方差意味着变量的变化优先。一种极端情况是变量的取值只有一种,即方差为0,因此方差较小的变量是需要剔除的,可以认为这样的变量没有预测能力。
3、预测能力变量筛选
预测能力相关指标有信息增益、信息增益比、基尼系数和卡方值等。信息增益越大,表示按照改变了对样本进行划分,其类别属性的不确定性越小,纯度越高,对好坏样本的分类效果越好。假设有100个变量,可以计算每个变量的信息增益值,然后按照信息增益值进行排序,仿照PCA中计算累计贡献率的方法,计算信息增益值的累计占比,可以取累计贡献率达到80%的样本作为初步变量选择结果,这样可以减少到几十维。
变量选择的过程不可能单纯依赖一种方法就可以得到很好的结果,因此可以采用多种方法相结合的方式逐步完成变量选择。
4、业务理解的变量筛选
这里指的是一些可量化的客观业务指标。某些专家经验属于更高层的业务理解,比较主观且无法抽象为指标,并不适合进行量化描述。一般可用于变量选择且与评分卡业务紧密相关的指标为IV值和PSI值。
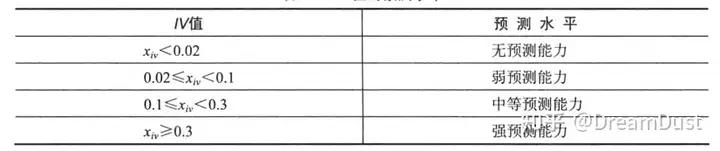
IV值就是对称化的K-L距离,可以衡量类别分布的差异情况,反映输入变量对标签的预测能力。IV值的预测水平如下表。可以给定一个阈值来进行变量选择。注意如果IV值太高,如大于0.5,则要验证以下变量是否存在问题。
PSI指标其实是一种模型评估指标,一方面可以用于评估模型上线后预测结果与建模时的结果是否存在偏差;另一方面也可以用于变量选择,衡量变量的稳定性。我们介绍过分箱的好处之一就是可以使训练集与测试集更容易满足来自同一总体分布的要求,PSI指标正是从变量的角度衡量变量随时间的变化稳定性是否变差,如果稳定水平变差,则该变量需要删除,否则,会影响模型的性能。PSI计算公式如下:

其中M为组数,如按照概率分为10组;traini与testi分别表示第i组训练样本与测试样本的数量;traintotal与testtotal为训练样本与测试样本的总量。
当然,可以将数据分为多组,而不仅分为训练集与测试集,这样就可以得到PSI值随时间变化的曲线,可以更加直观地观察PSI值的变化情况。

从PSI值的计算公式可以看出,PSI指标也是从K-L距离角度量化建模数据与测试数据之间的距离,但希望PSI指标越小越好,即K-L距离越小越好,表示两个分布函数的距离越小,月容易满足来自同一个总体分布的假设。
5、相关性指标变量筛选
相关性度量的准则就是“最大相关最小冗余”,即输入变量与标签变量之间要有强相关,而输入变量之间要若相关,以去除变量间的冗余,消除多重共线性问题。一般可以采用相关系数反映,计算公式如下:
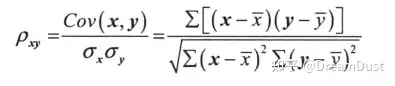
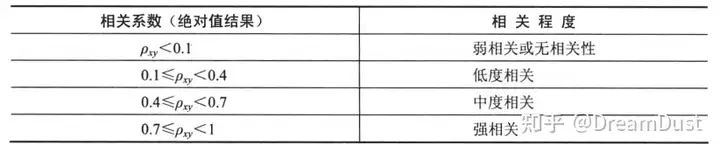
相关系数结果是有正负之分,在变量选择时我们只关心相关性高就代表变量有意义。
需要说明的是相关系数是计算连续变量之间的相关性,如果计算离散变量之间的相关性,则需要用卡方检验的方法。当然也可以用对称的K-L距离来衡量,两个变量的分布越相似,相关性就越高。因此需要区分离散变量与连续变量。而计算离散变量与连续变量之间的相关性,则需要将连续变量进行分箱,再按照离散变量与离散变量的方式计算相关性。在传统评分卡的建模过程中,离散变量要WOE编码后进行数值化,而连续变量要分箱后进行WOE编码,这样在求相关性时只需考虑连续变量之间的相关性问题,不需要考虑离散变量与连续变量混合的问题。