Training loop:
May 26, 2026 · View on GitHub
Lightweight Framework for Edge AI
✨ If you like our project, please give us a star ⭐️ for the latest update.
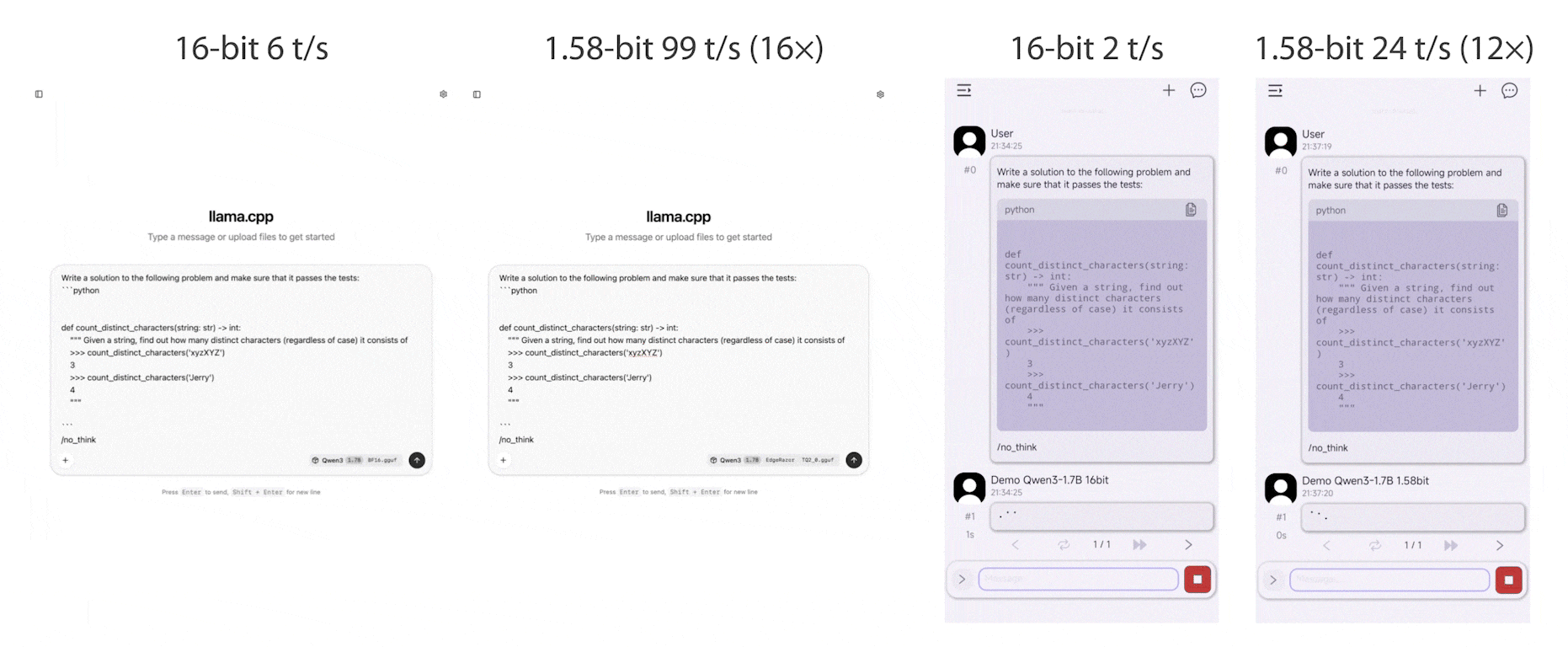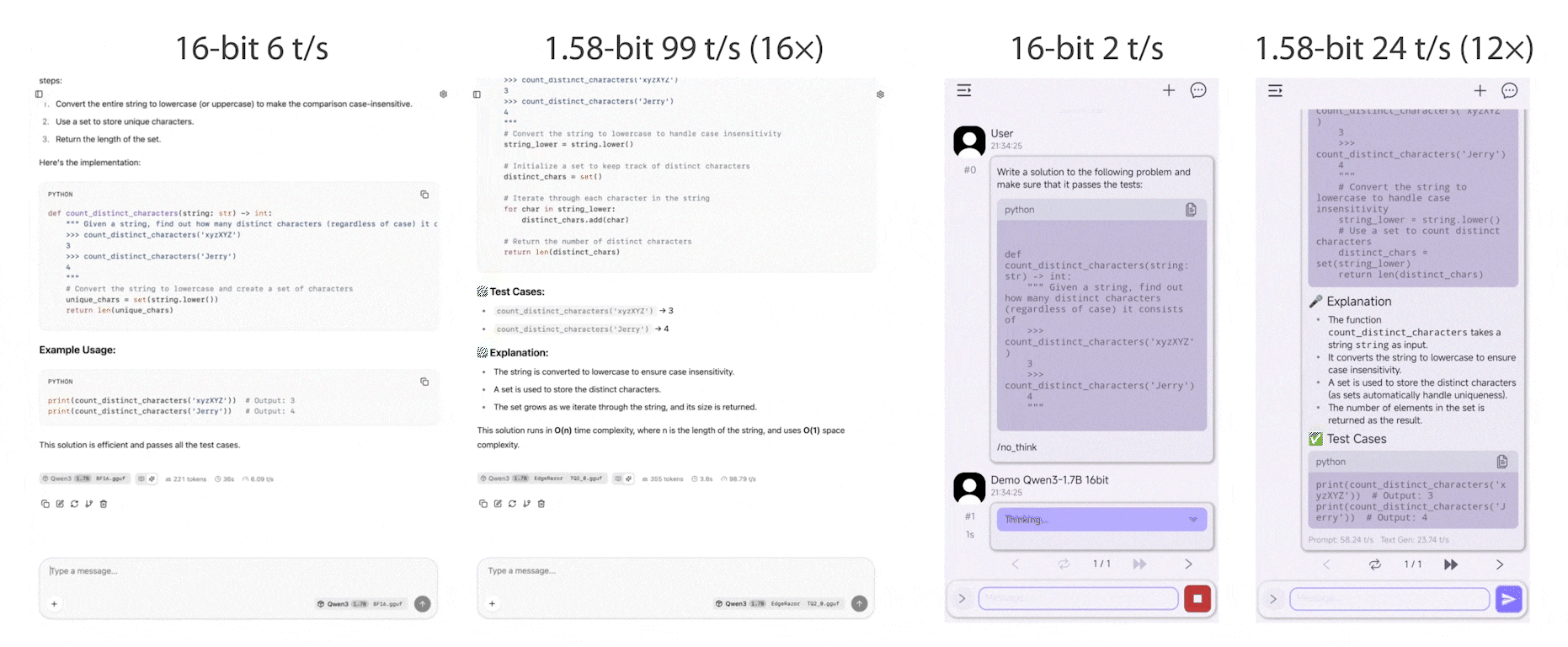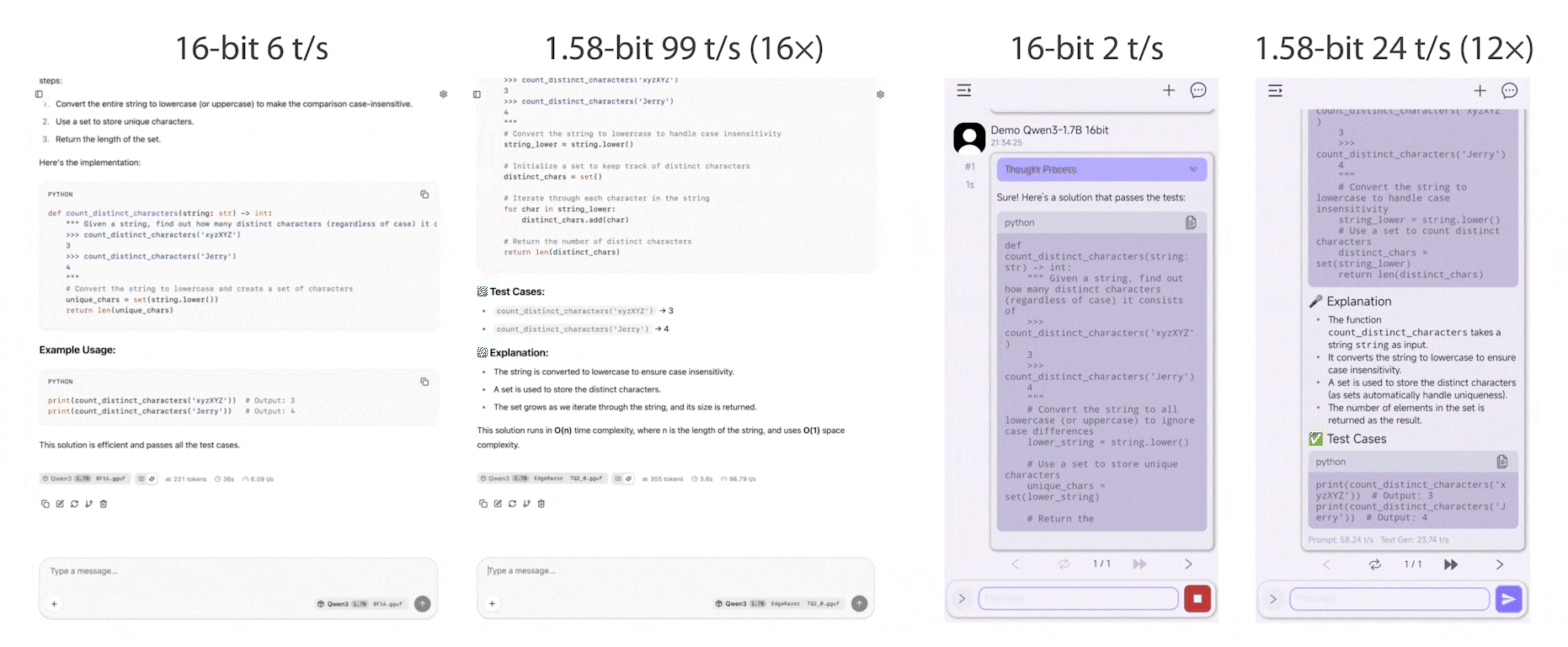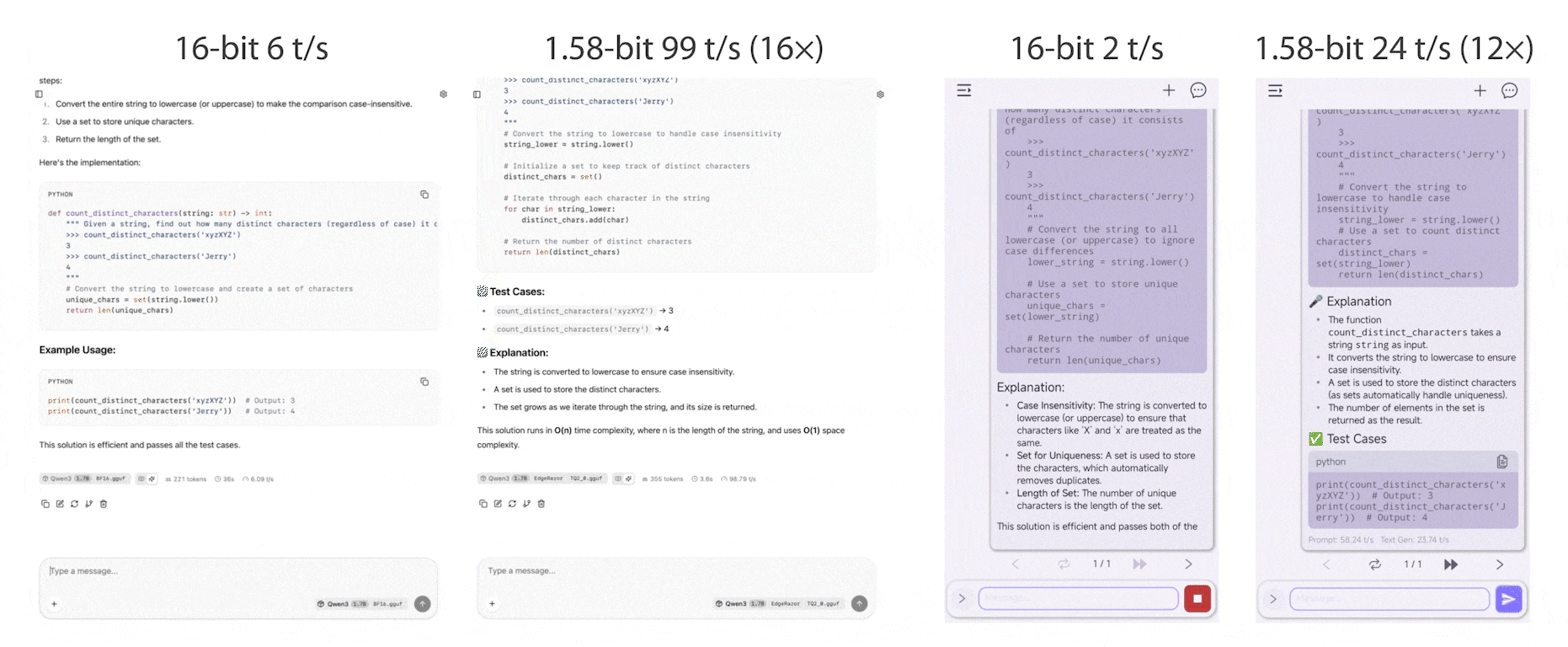
EdgeRazor is a lightweight framework for edge AI, designed to train models that are smaller, faster, and deployable across diverse hardware, ranging from mobile and edge endpoints to latency-sensitive clouds. The EdgeRazor framework seamlessly integrates model compression techniques into existing full-precision training pipelines with minimal code modification, preserving promising task performance and enabling low-cost and high-efficiency computations.
EdgeRazor currently focuses on low-bit LLM compression via configurable quantization-aware distillation. In terms of quantization, EdgeRazor supports quantizing weights (including embedding and lm_head layers), activations, and KV cache. Quantized bit-widths include the uniform 1.58-bit and 4-bit, as well as matrix-wise mixed-precision, such as 2.79-bit (50% 4-bit + 50% 1.58-bit) and 1.88-bit (12.5% 4-bit + 87.5% 1.58-bit). In terms of distillation, EdgeRazor offers the logits, features, and attention distillation, all of which can be flexibly combined within a unified configuration interface.
EdgeRazor achieves the state-of-the-art performance across a range of models, including base LLMs, instruction-tuned LLMs, and multimodal LLMs. For W-A8-KV8 quantization, Qwen3-0.6B-EdgeRazor attains average scores of 47.80 / 44.10 / 41.76 / 39.81 at 4-bit / 2.79-bit / 1.88-bit / 1.58-bit, corresponding to compression ratios of 3.94× / 5.05× / 6.40× / 7.03×, respectively. In comparison, the best prior methods achieve 45.74 / 37.38 / 30.49 at 4-bit / 3-bit / 2-bit with compression ratios of 2.21× / 2.47× / 2.78×.
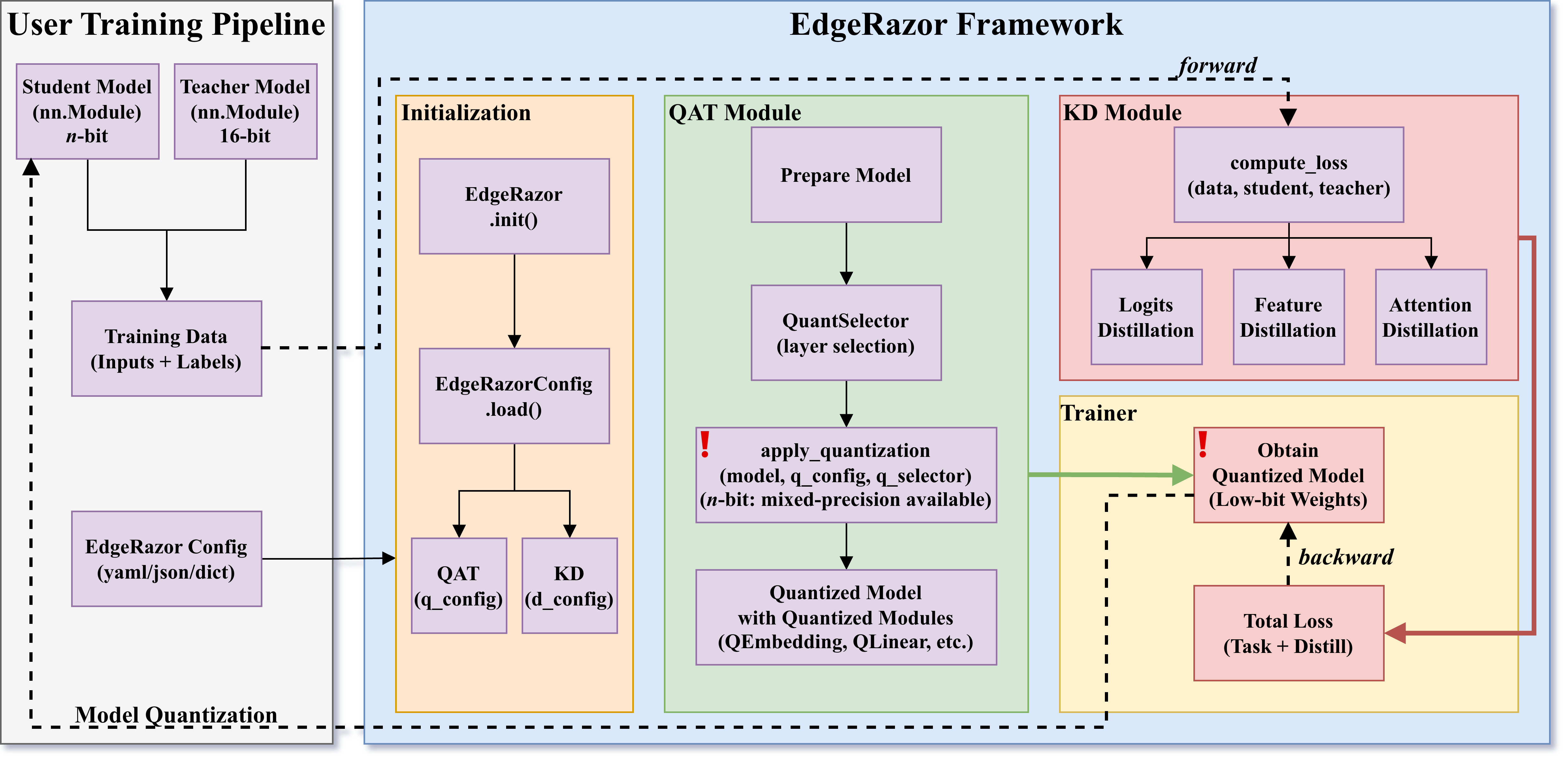
Figure: The EdgeRazor framework with lightweight model training pipeline.
News
- 🔥 [2026-04]: 📄 Paper-EdgeRazor is available on arXiv:2605.04062 and Hugging Face Paper!
- 🔥 [2026-04]: 🚀 EdgeRazor Playground is launched and open-sourced! CPU-friendly! Have a try!
- 🔥 [2026-04]: 🏅 CACC 2025 Final (China Algorithm Capability Competition) apply EdgeRazor as a solution in the AI subject!
- 🔥 [2026-04]: 🏆 Low-bit LLMs by EdgeRazor is released! Check our Hugging Face collection: zhangsq-nju/edgerazor-nbit.
- 🔥 [2026-04]: 🛠️ Open-sourced EdgeRazor-V1 is released! Now configurable on diverse models for seamless integration and customization!
- 🔥 [2025-10]: 📄 Paper-TernaryCLIP is available on arXiv:2510.21879!
Contents
- News
- Contents
- Quick Start
- Main Techniques
- Applications
- Model Zoo
- Todo List
- Acknowledgements
- Citation
- Contributor List
Quick Start
Installation
- Download from PyPi
pip install edgerazor
- Download from GitHub (latest version)
git clone https://github.com/zhangsq-nju/EdgeRazor.git && cd EdgeRazor
conda create -n edgerazor python=3.10.20 -y
conda activate edgerazor
pip install -e .
Usage
After installation, you can integrate EdgeRazor into your existing training pipeline to build lightweight models.
-
Seamlessly integrate EdgeRazor into your FULL-PRECISION model training pipeline!
-
Below are LLM examples of both the high-level and low-level API usage
# High-level API Usage
trainer = EdgeRazorCausalLMTrainer(
model=student,
args=TrainingArguments(...),
train_dataset=train_dataset,
data_collator=data_collator,
processing_class=tokenizer,
teacher_model=teacher,
edgerazor_config="/path/to/w1.58-a8-kv8.yaml",
)
trainer.train()
# Low-level API Usage
edgerazor = EdgeRazor(config="/path/to/w1.58-a8-kv8.yaml")
student = edgerazor.quantize(student)
kv_cache_quant = edgerazor.create_kv_cache(model_config=student.config)
# Training loop:
student_outputs = student(**inputs, kv_cache_quant)
teacher_outputs = teacher(**inputs)
loss, loss_dict = edgerazor.compute_loss(student_outputs, teacher_outputs, labels)
Docker
Lightweight models are available from checkpoints trained with EdgeRazor. For example, you can convert Qwen3-EdgeRazor-4bit checkpoints to Q4_0 GGUF models. We also provide ready-to-use quantized models in our collection, including Qwen3-0.6B-EdgeRazor-GGUF and Qwen3-1.7B-EdgeRazor-GGUF.
# Serve quantized LLMs under CPU-only environments:
docker pull ghcr.io/ggml-org/llama.cpp:server
hf download zhangsq-nju/Qwen3-1.7B-EdgeRazor-GGUF Qwen3-1.7B-EdgeRazor-TQ2_0.gguf --local-dir /path/to/Qwen3-1.7B-EdgeRazor-GGUF
cd ./docker && bash local_server_tq2_0.sh
Playground
EdgeRazor Playgound is CPU-friendly! Enjoy low-bit LLMs from EdgeRazor on your edge devices!
cd EdgeRazor/playground
pip install -r requirements.txt
python app.py
Main Techniques
Mixed-Precision Quantization-Aware Distillation (MPQAD):
- Configurable training pipelines between 16-bit and -bit models
- Configurable quantization for weights: Structural Quantization with Mixed Precision (SQMP)
- Configurable distillation methods: Layer-Adaptive Feature Distillation (LAFD), Entropy-Aware KL Divergence (EAKLD)
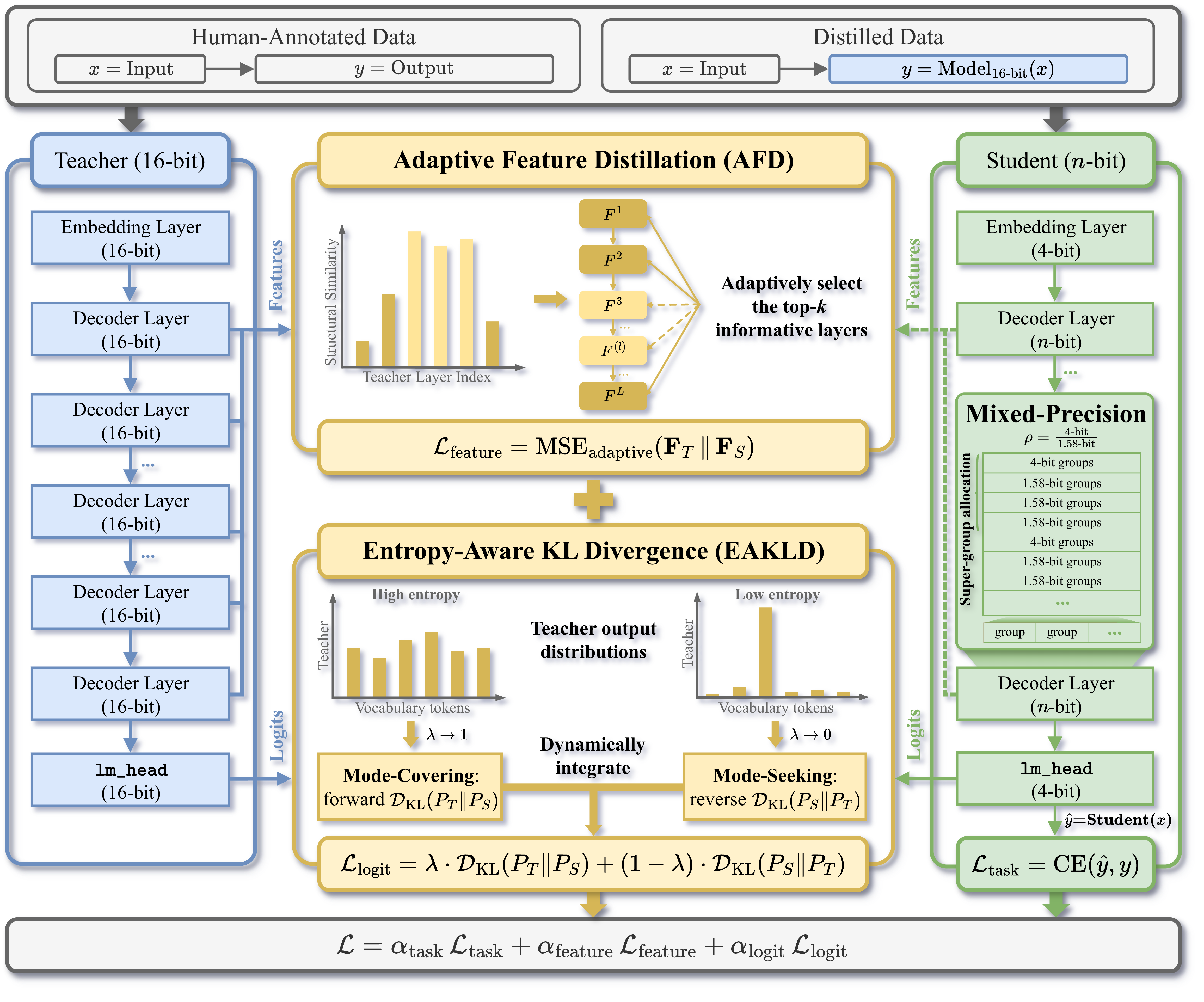
Figure: Workflow of the EdgeRazor framework.
Applications
- Lightweight ViT-S/16 for MNIST, check here.
- Lightweight ViT-S/16 for RetinaMNIST, check here.
- Lightweight ResNet-18, check here.
- Lightweight Qwen3-0.6B/1.7B, check here.
- Lightweight MobileLLM-ParetoQ-350M-BF16, check here.
- Lightweight Qwen2.5-Omni-7B, check here.
Model Zoo
LLMs
-
Average Performance (Avg.): average of performance scores in multiple tasks using lm-eval v0.4.9.1 with tasks.
- Tasks for instruct LLMs: arc_easy, arc_challenge, hellaswag, boolq, social_iqa, openbookqa, piqa, winogrande, hendrycks_ethics, truthfulqa_mc2, mmlu, gsm8k, humaneval_instruct, ifeval.
- Tasks for base LLMs: arc_easy, arc_challenge, hellaswag, boolq, social_iqa, openbookqa, piqa, winogrande, hendrycks_ethics, truthfulqa_mc2, mmlu, gsm8k, humaneval.
- Except for 5-shot gsm8k, all other tasks are 0-shot.
-
Hub Link: We provide the original quantized checkpoints. We also transfer the checkpoints into GGUF (llama.cpp) and GPTQ (GPTQModel, working in progress) formats if compatible.
| Model | W-A-KV | Group Size | Avg. | Hub Link |
|---|---|---|---|---|
| Qwen3-0.6B | W16-A16-KV16 | - | 47.35 | Base |
| Qwen3-0.6B | W4-A8-KV8 | 256 | 47.80 | EdgeRazor, Q4_0 |
| Qwen3-0.6B | W2.79-A8-KV8 | 256 | 44.10 | EdgeRazor |
| Qwen3-0.6B | W1.88-A8-KV8 | 256 | 41.76 | EdgeRazor |
| Qwen3-0.6B | W1.58-A8-KV8 | 256 | 39.81 | EdgeRazor, TQ1_0, TQ2_0 |
| Qwen3-1.7B | W16-A16-KV16 | - | 58.65 | Base |
| Qwen3-1.7B | W4-A8-KV8 | 256 | 58.57 | EdgeRazor, Q4_0 |
| Qwen3-1.7B | W2.79-A8-KV8 | 256 | 53.00 | EdgeRazor |
| Qwen3-1.7B | W1.88-A8-KV8 | 256 | 47.14 | EdgeRazor |
| Qwen3-1.7B | W1.58-A8-KV8 | 256 | 43.91 | EdgeRazor, TQ1_0, TQ2_0 |
| MobileLLM-350M | W16-A16-KV16 | - | 41.18 | Base |
| MobileLLM-350M | W4-A8-KV8 | 64 | 41.86 | EdgeRazor |
| MobileLLM-350M | W2.79-A8-KV8 | 64 | 40.62 | EdgeRazor |
| MobileLLM-350M | W1.88-A8-KV8 | 64 | 39.32 | EdgeRazor |
| MobileLLM-350M | W1.58-A8-KV8 | 64 | 38.12 | EdgeRazor |
MLLMs
- Video-MME and MLVU are video understanding tasks using lmms-eval v0.5.0 with tasks.
| Model | W-A-KV | Group Size | Video-MME | MLVU | Hub Link |
|---|---|---|---|---|---|
| Qwen2.5-Omni-7B | W16-A16-KV16 | - | 62.81 | 48.01 | Base |
| Qwen2.5-Omni-7B | W4-A16-KV16 | 32 | 62.22 | 48.82 | EdgeRazor |
Todo List
EdgeRazor is continuously evolving! Here's what's coming:
- Lightweight MobileLLM, Qwen3, and Qwen2.5-Omni: training code
- New API: EdgeRazorCausalLMTrainer for compressing text LLMs
- Upgrade to support the newest dependencies
Have ideas or suggestions? We welcome and appreciate any contributions and collaborations! Please feel free to submit issues or pull requests! 🚀
Acknowledgements
The deployment demos utilize llama.cpp and ChatterUI.
Citation
If you find our papar and code useful in your research, please consider kindly citing our papers ✏️:
@article{zhangsh-edgerazor,
title={{EdgeRazor}: A Lightweight Framework for Large Language Models via Mixed-Precision Quantization-Aware Distillation},
author={Shu-Hao Zhang and Le-Tong Huang and Xiang-Sheng Deng and Xin-Yi Zou and Chen Wu and Nan Li and Shao-Qun Zhang},
year={2026},
journal={arXiv preprint arXiv:2605.04062}
}
@article{zhangsh-ternaryclip,
title={{TernaryCLIP}: Efficiently Compressing Vision-Language Models with Ternary Weights and Distilled Knowledge},
author={Shu-Hao Zhang and Wei-Cheng Tang and Chen Wu and Peng Hu and Nan Li and Liang-Jie Zhang and Qi Zhang and Shao-Qun Zhang},
year={2025},
journal={arXiv preprint arXiv:2510.21879}
}
Contributor List
This project was supported by LAMDA and Assistant Professor Shao-Qun Zhang. Shu-Hao Zhang is the core developer and maintainer of EdgeRazor-V1. Xiang-Sheng Deng and Le-Tong Huang jointly participated in the development of this project.