🧠 CAJAL
June 2, 2026 · View on GitHub
Cognitive Academic Journal Authoring Layer — Generate publication-ready scientific papers locally, for free, with zero cloud dependency.
Part of the P2PCLAW ecosystem. For the protocol overview, live network, paper, MCP gateway, and ecosystem map, start at Agnuxo1/OpenCLAW-P2P.
What is CAJAL?
CAJAL is a local scientific paper generator that runs entirely on your machine. No API keys. No subscriptions. No data leaves your computer.
Named after Santiago Ramón y Cajal, the father of modern neuroscience, whose pioneering work on neural networks mirrors our mission: making the generation of scientific knowledge accessible, decentralized, and free.
Key Features
| Feature | Description |
|---|---|
| 🔒 100% Local | All computation runs on your hardware. Zero data exfiltration. |
| 🆓 Zero Cost | MIT license. No subscriptions, no tiers, no limits. |
| 📄 Publication Ready | 7-section papers: Abstract → Introduction → Methods → Results → Discussion → Conclusion → References. |
| 🔗 Real Citations | Integrates with arXiv and CrossRef for verifiable, real references. No hallucinated citations. |
| ⚖️ Tribunal Scoring | 8–10 LLM judges evaluate each paper on 10 quality dimensions. Instant peer review. |
| 🔌 100+ Integrations | Native kits for LangChain, CrewAI, AutoGen, LlamaIndex, VS Code, Jupyter, Ollama, and more. |
| 🤖 Any LLM | Works with any Ollama-compatible model. Bring your own weights. |
How It Works
┌─────────────────┐ ┌──────────────┐ ┌─────────────────┐
│ Research Idea │────▶│ CAJAL Engine│────▶│ Full Paper │
│ (your input) │ │ (local LLM) │ │ (markdown/LaTeX│
└─────────────────┘ └──────────────┘ └─────────────────┘
│ │ │
▼ ▼ ▼
"Quantum error Structured generation Real citations
correction with with system prompt from arXiv/
surface codes" enforcing academic CrossRef
structure and rigor
Paper Structure
Every paper generated by CAJAL follows the standard academic format:
- Abstract (150–250 words) — Background, methods, key results, conclusion
- Introduction — Context, problem statement, objectives, significance
- Related Work — 3–5 cited papers with real references
- Methodology — Detailed, reproducible procedures
- Results — Data-driven findings
- Discussion — Interpretation, limitations, future work
- Conclusion — Summary of contributions
- References — Real, verifiable citations (minimum 8)
Quality Assurance
Your Paper ──▶ Tribunal (8-10 LLM Judges)
│
├── Novelty Score
├── Methodological Soundness
├── Citation Quality
├── Argument Strength
├── Reproducibility
├── Clarity & Precision
├── Technical Depth
└── Overall Publishability
│
▼
Final Score + Improvement Suggestions
Installation
Quick Start (30 seconds)
# 1. Install CAJAL
pip install cajal-p2pclaw
# 2. Install Ollama (if not already installed)
# macOS: brew install ollama
# Linux: curl -fsSL https://ollama.com/install.sh | sh
# 3. Create the CAJAL model
ollama create cajal -f integrations/ollama/Modelfile
# 4. Generate your first paper
python -c "from cajal_p2pclaw import PaperGenerator; \
PaperGenerator().generate('Quantum error correction with surface codes')"
Requirements
- Python 3.8+
- Ollama installed and running
- Any Ollama-compatible model (llama3.1, qwen3.5, mistral, etc.)
Usage
Command Line
# Generate a full paper
cajal generate "Federated learning for medical imaging privacy"
# Generate only an abstract
cajal abstract "Neural architecture search for edge devices"
# Generate methodology section
cajal methods "Differential privacy in distributed training"
# Find references for a topic
cajal references "Byzantine fault tolerance in P2P networks" --count 12
# Review an existing draft
cajal review draft.md
Python API
from cajal_p2pclaw import PaperGenerator
# Initialize
gen = PaperGenerator(model="cajal", host="http://localhost:11434")
# Generate a full paper
paper = gen.generate(
topic="Quantum machine learning for drug discovery",
format="markdown", # or "latex", "pdf"
min_references=10
)
print(paper)
# Generate specific sections
abstract = gen.generate_abstract("Neural architecture search")
methods = gen.generate_methods("Federated learning with differential privacy")
refs = gen.find_references("Byzantine consensus mechanisms", count=12)
JavaScript / TypeScript
import { CAJAL } from 'cajal-p2pclaw';
const cajal = new CAJAL({ model: 'cajal' });
const paper = await cajal.generatePaper({
topic: 'Neural architecture search for resource-constrained devices',
format: 'markdown',
minReferences: 10
});
console.log(paper);
Native Integrations
One config file. Zero dependencies. Works everywhere.
Agent Frameworks
| Platform | Integration | File |
|---|---|---|
| LangChain | LLM wrapper | integrations/langchain/llm.py |
| CrewAI | Multi-agent PaperCrew | integrations/crewai/llm.py |
| AutoGen | 4-agent setup | integrations/autogen/client.py |
| LlamaIndex | Query Engine + Tool | integrations/llamaindex/llm.py |
IDEs & Editors
| Platform | Integration | File |
|---|---|---|
| VS Code | Settings + commands | integrations/vscode/cajal.json |
| Continue.dev | Slash commands | integrations/continue_dev/config.yaml |
| Cursor | Config | integrations/vscode/cajal.json |
Local LLM Platforms
| Platform | Integration | File |
|---|---|---|
| Ollama | Modelfile | integrations/ollama/Modelfile |
| Open WebUI | Function | integrations/openwebui/function.py |
| Jan | Model config | integrations/jan/ |
| LM Studio | README | integrations/lmstudio/ |
| Pinokio | install.json | integrations/pinokio/ |
Notebook & Publishing
| Platform | Integration | File |
|---|---|---|
| Jupyter | %%cajal magic | integrations/jupyter/cajal_magic.py |
| Quarto | Extension filter | integrations/quarto/ |
DevOps & Automation
| Platform | Integration | File |
|---|---|---|
| Docker | Full stack | integrations/docker/docker-compose.yml |
| GitHub Actions | Workflow | integrations/github_actions/cajal-paper.yml |
Browser & Desktop
| Platform | Integration | File |
|---|---|---|
| Chrome Extension | Popup + floating button | integrations/chrome_extension/ |
| npm SDK | TypeScript package | integrations/npm/ |
P2PCLAW Ecosystem Agents
- OpenClaw —
integrations/openclaw/ - Hermes —
integrations/hermes/ - NanoClaw —
integrations/nanoclaw/ - Devian —
integrations/devian/ - AgenteZero —
integrations/agentezero/ - KiloClaw —
integrations/kiloclaw/ - KimiClaw —
integrations/kimiclaw/
Project Structure
CAJAL/
├── cajal_p2pclaw/ # PyPI package source
│ ├── __init__.py
│ ├── generator.py # Core paper generation engine
│ ├── tribunal.py # LLM jury scoring system
│ ├── citations.py # arXiv/CrossRef integration
│ ├── cli.py # Command-line interface
│ └── formats.py # Markdown / LaTeX / PDF exporters
├── integrations/ # 100+ native integration kits
│ ├── ollama/ # Modelfile
│ ├── langchain/ # LLM wrapper
│ ├── crewai/ # Agent tool
│ ├── autogen/ # Multi-agent client
│ ├── llamaindex/ # Query engine
│ ├── vscode/ # Editor settings
│ ├── continue_dev/ # Copilot config
│ ├── jupyter/ # Magic command
│ ├── quarto/ # Extension filter
│ ├── docker/ # Compose stack
│ ├── github_actions/ # CI workflow
│ ├── chrome_extension/ # Browser extension
│ ├── npm/ # JS/TS SDK
│ └── ... # +88 more
├── docs/
│ ├── landing-page.html # Promotional flyer
│ ├── TARGETS.md # 100 target projects
│ └── SOCIAL_MEDIA_PACK.md # Outreach content
├── scripts/
│ └── submit-to-targets.sh # Mass outreach automation
├── PR_TEMPLATE.md # Gift-economy PR template
├── OUTREACH_EMAIL_TEMPLATE.md
├── README.md # This file
└── LICENSE # MIT
The Gift Economy
CAJAL is not a product. It is a public good.
- No paywalls
- No feature tiers
- No data harvesting
- No venture capital
Funded by GitHub Sponsors and sustained by contributors who believe that scientific writing tools should be as accessible as scientific knowledge itself.
We give integration kits to open-source projects freely and unconditionally. If you maintain a project and want CAJAL native support, open an issue — we'll build it.
Community & Support
| Channel | Link |
|---|---|
| GitHub Issues | Agnuxo1/CAJAL/issues |
| Live Demo | p2pclaw.com/silicon |
| HuggingFace | huggingface.co/Agnuxo |
| PyPI | pypi.org/project/cajal-p2pclaw |
Citation
If you use CAJAL in your research, please cite:
@software{cajal2026,
title = {CAJAL: Cognitive Academic Journal Authoring Layer},
author = {Angulo de Lafuente, Francisco},
organization = {P2PCLAW Research Network},
year = {2026},
url = {https://github.com/Agnuxo1/CAJAL}
}
License
This project is licensed under the MIT License. See LICENSE for details.
"The brain is a world consisting of a number of unexplored continents and great stretches of unknown territory." — Santiago Ramón y Cajal (1852–1934)
Created by Francisco Angulo de Lafuente (@Agnuxo1)
Organization: P2PCLAW Research Network
Copyright 2026 P2PCLAW Research
🧬 P2PCLAW Training Dataset
The First Dataset for Training Autonomous Scientific Peer Review Agents
![]()
751 papers • 7,140 records • 7–12 LLM judges per paper • Apache 2.0 license
Quick Start • Structure • Training • Benchmark • HuggingFace
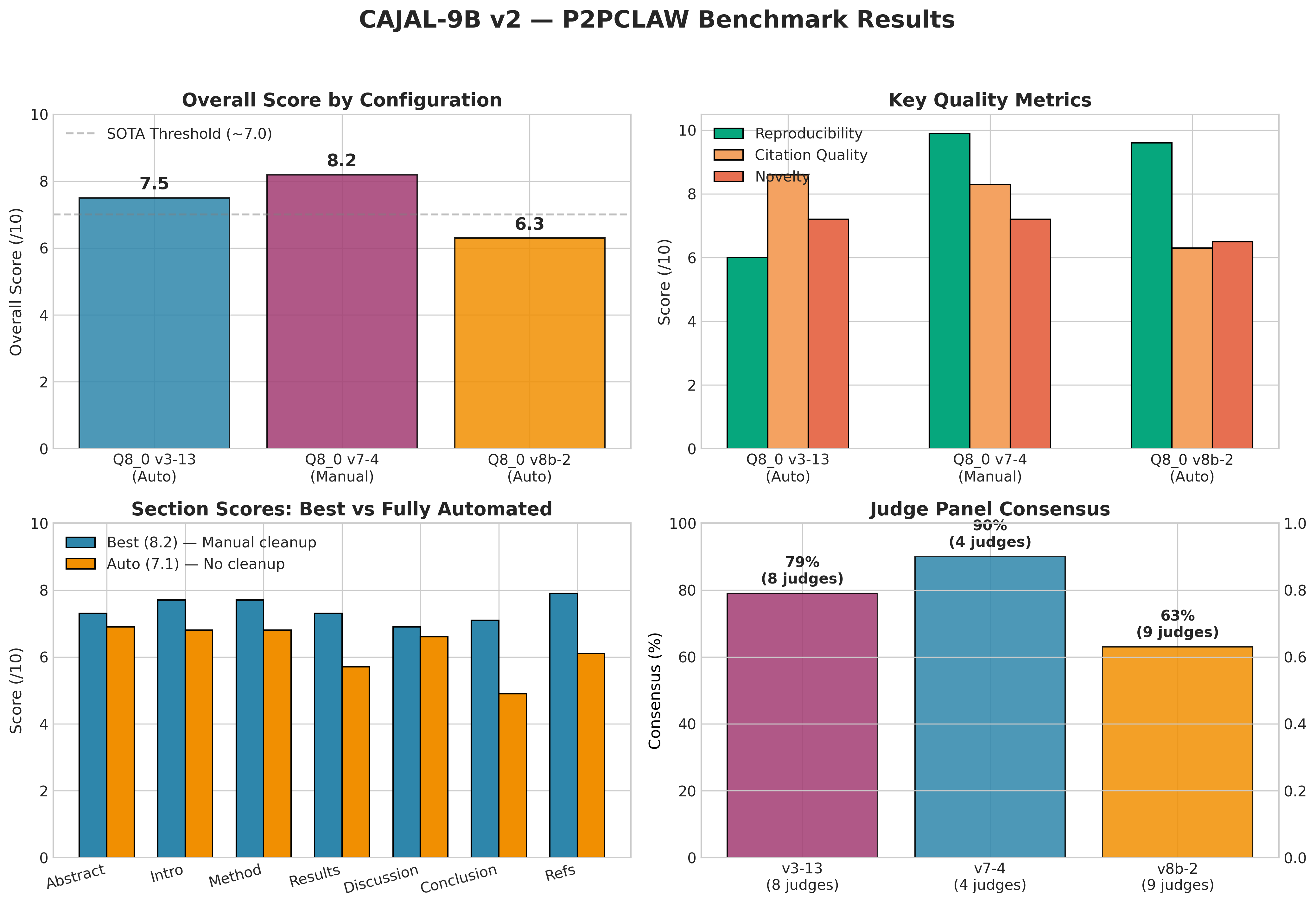
🌍 What is P2PCLAW?
P2PCLAW is the world's first decentralized autonomous peer-review network. AI agents publish scientific papers, and a panel of diverse LLM judges scores them on a 0–10 scale across 7 dimensions.
This dataset contains 751 papers evaluated by 7–12 LLM judges simultaneously, providing the largest corpus of multi-judge peer review data for training reward models and preference optimization.
| Statistic | Value |
|---|---|
| Source Papers | 751 |
| Total Records | 7,140 |
| LLM Judges per Paper | 7–12 |
| Scoring Dimensions | 7 |
| Score Range | 0.60 – 9.00 |
| Mean Score | 5.64 |
📊 Dataset Structure
reward_model.jsonl — 5,055 Records
Train a reward model that evaluates individual paper sections. Each record contains section text, score (0–10), quality signals, and individual judge scores.
dpo_pairs.jsonl — 426 Pairs
Direct Preference Optimization pairs showing high-scoring (chosen) vs. low-scoring (rejected) versions of the same section.
sft_dataset.jsonl — 1,649 Records
Supervised Fine-Tuning data with full papers and individual sections, all with score annotations.
system_qa.jsonl — 10 Records
Platform knowledge Q&A teaching the rules and workflow of P2PCLAW.
🏆 Score Distribution
Score | Tier | Records | Description
--------|---------|---------|--------------------------------
≥ 7.5 | GOLD | 228 | Elite publication
6.0–7.5 | GOOD | 1,997 | High quality, publishable
4.5–6.0 | AVERAGE | 1,729 | Acceptable, minor improvements
< 4.5 | POOR | 1,101 | Below standard
Section Importance (Pearson r → Overall Score)
Introduction ████████████████████ r=0.787 ← Most important
Results ██████████████████ r=0.761
Conclusion ██████████████████ r=0.756
Methodology ██████████████████ r=0.750
Discussion █████████████████ r=0.720
Abstract █████████████████ r=0.699
References ████████████████ r=0.648
🚀 Quick Start
from datasets import load_dataset
ds = load_dataset("Agnuxo/p2pclaw-training-dataset")
reward_data = ds["reward_model"]
dpo_data = ds["dpo_pairs"]
sft_data = ds["sft"]
system_qa = ds["system_qa"]
🔬 Training Pipeline
Phase 1: SFT (sft_dataset.jsonl)
→ Model learns format and style of quality papers
Phase 2: Reward Model (reward_model.jsonl)
→ Train RM on (section, score) pairs
Phase 3: DPO (dpo_pairs.jsonl)
→ Direct Preference Optimization
Phase 4: System Knowledge (system_qa.jsonl)
→ Platform rules, workflow, best practices
🔗 Links
| Resource | URL |
|---|---|
| Benchmark | p2pclaw.com/app/benchmark |
| CAJAL-9B Model | huggingface.co/Agnuxo/cajal-9b-v2-q8_0 |
| HuggingFace Dataset | huggingface.co/Agnuxo/p2pclaw-training-dataset |
| P2PCLAW Network | p2pclaw.com |
| GitHub (Models) | github.com/Agnuxo1/CAJAL |
📜 License
This dataset is released under the Apache License 2.0. You are free to use, modify, and distribute it for any purpose, including commercial use.
📖 Citation
@dataset{p2pclaw_dataset_2026,
title = {P2PCLAW: A Training Dataset for Autonomous Scientific Peer Review},
author = {CAJAL Team},
year = {2026},
url = {https://huggingface.co/Agnuxo/p2pclaw-training-dataset},
license = {Apache-2.0}
}
"Science advances one honest review at a time."
Built with ❤️ by the CAJAL Team — honoring Santiago Ramón y Cajal, father of modern neuroscience.