README.md
June 8, 2026 · View on GitHub
![]()
Vision-DeepResearch & Vision-DeepResearch Benchmark (VDR-Bench)
The official repo for "Vision-DeepResearch: Incentivizing DeepResearch Capability in Multimodal Large Language Models" and "Vision-DeepResearch Benchmark: Rethinking Visual and Textual Search for Multimodal Large Language Models".
🤗 Cold-start Dataset (demo) | 🤗 RL Dataset (demo) | 🤗 VDR-Bench (full) | 🤗 VDR-Bench (testmini)
🤗 Vision-DeepResearch-30B-A3B (SFT+RL) | 🤗 Vision-DeepResearch-8B (SFT-only)
📑Vision-DeepResearch Paper | 📑 VDR-Bench Paper
The datasets, code and weights will be released, stay tuned!Timeline
-
[2026/06/08] We released Vision-DeepResearch-30B-A3B.
-
[2026/05/24] We have released the subset of our used benchmark subset and detailed evaluation guidance! Please see VQA Benchmark Subset and Eval Guidance.
-
[2026/05/01] Vision-DeepResearch has been accepted by ICML 2026! Nice to see you at the conference!
-
[2026/02/03] We released SFT code, RL code! We will finish the guidance later, stay tune!
-
[2026/02/02] We released Cold-start Dataset (demo), RL Dataset (demo), Vision-DeepResearch-8B (SFT-only), VDR-Bench (full), VDR-Bench (testmini)!
Demo (click to watch on YouTube)
Compare to Other Methods
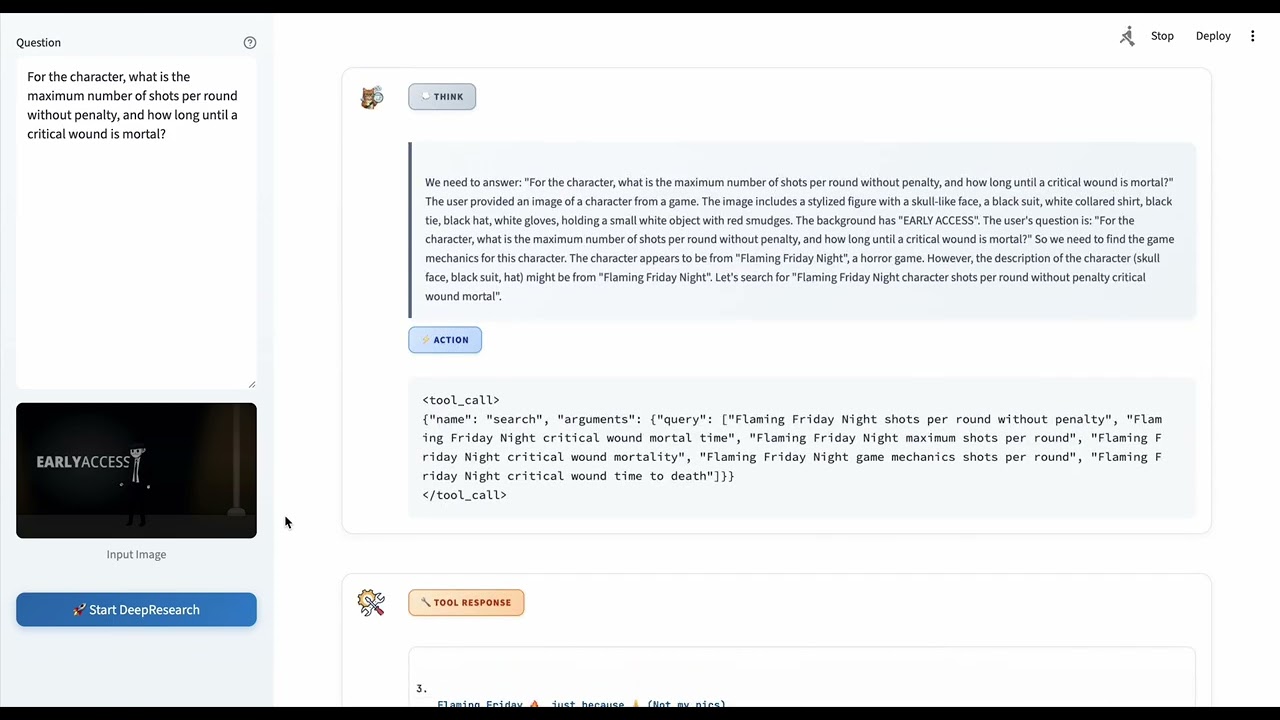
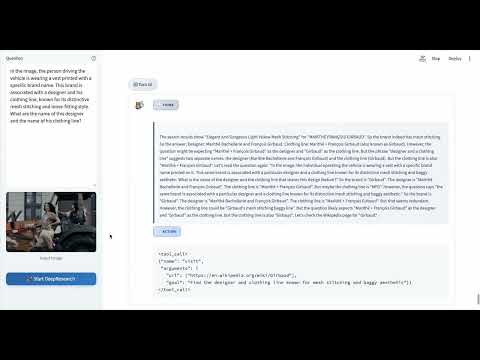
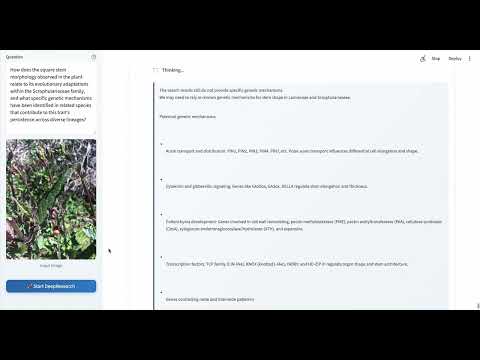
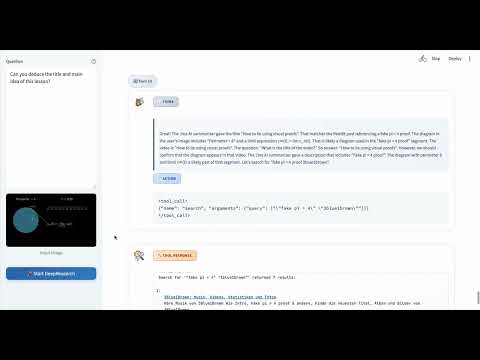
More Cases
 |
 |
 |
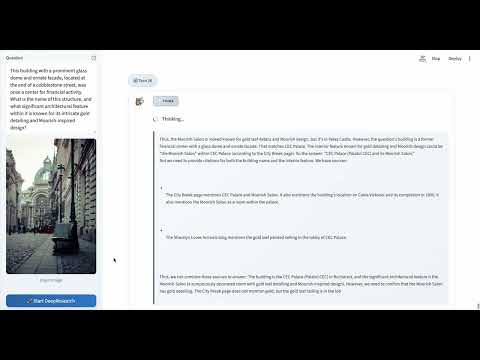 |
Performance
| Model | VDR | FVQA | MMSearch+ | MMSearch | LiveVQA | BC-VL | Avg. |
|---|---|---|---|---|---|---|---|
| Direct Answer | |||||||
| GPT-5 | 9.8 | 57.3 | 19.1 | 33.3 | 57.5 | 47.2 | 37.4 |
| Gemini-2.5 Pro | 8.0 | 60.7 | 14.5 | 39.8 | 60.3 | 43.1 | 37.7 |
| Gemini-2.5 Flash | 6.2 | 47.7 | 8.1 | 30.4 | 51.0 | 37.1 | 30.1 |
| Claude-4-Sonnet | 2.0 | 35.3 | 4.0 | 18.7 | 38.5 | 29.3 | 21.3 |
| Claude-3.7-Sonnet | 4.6 | 36.7 | 4.0 | 21.1 | 38.0 | 32.3 | 22.8 |
| Qwen3-VL-8B-Instruct | 2.8 | 28.0 | 3.2 | 15.2 | 41.0 | 25.1 | 19.2 |
| Qwen3-VL-8B-Thinking | 5.6 | 24.0 | 2.7 | 15.8 | 43.3 | 25.1 | 19.4 |
| Qwen3-VL-30B-A3B-Instruct | 3.8 | 34.7 | 3.2 | 18.7 | 42.7 | 29.6 | 22.1 |
| Qwen3-VL-30B-A3B-Thinking | 4.4 | 32.7 | 4.5 | 19.3 | 49.0 | 34.6 | 24.1 |
| RAG Workflow | |||||||
| Gemini-2.5-flash | -- | -- | -- | 43.9 | 41.3 | 12.1 | -- |
| Claude-3.7-Sonnet | -- | -- | -- | 32.7 | 30.3 | 10.0 | -- |
| Qwen-2.5-VL-72B | -- | -- | -- | 29.2 | 35.7 | 10.2 | -- |
| Agent Workflow | |||||||
| GPT-5 | 20.4 | 69.0 | 17.2 | 63.7 | 73.3 | 46.1 | 48.3 |
| Gemini-2.5 Pro | 18.8 | 68.3 | 22.2 | 69.0 | 76.0 | 49.9 | 50.7 |
| Gemini-2.5 Flash | 16.3 | 68.0 | 19.9 | 64.0 | 73.0 | 44.6 | 47.6 |
| Claude-4-Sonnet | 13.6 | 69.0 | 23.1 | 67.2 | 69.7 | 48.6 | 48.5 |
| Claude-3.7-Sonnet | 27.2 | 67.3 | 17.2 | 63.7 | 72.0 | 50.4 | 49.6 |
| Qwen3-VL-8B-Thinking | 17.6 | 51.3 | 12.2 | 45.6 | 56.3 | 37.1 | 36.7 |
| Qwen3-VL-30B-A3B-Thinking | 23.2 | 63.0 | 13.6 | 53.2 | 62.0 | 44.1 | 43.2 |
| Multimodal DeepResearch MLLM | |||||||
| MMSearch-R1-7B | -- | 58.4 | -- | 53.8 | 48.4 | -- | -- |
| Webwatcher-7B | -- | -- | -- | 49.1 | 51.2 | 20.3 | -- |
| Webwatcher-32B | -- | -- | -- | 55.3 | 58.7 | 26.7 | -- |
| Ours | |||||||
| Qwen3-VL-8B-Instruct (Agentic) | 17.0 | 58.7 | 11.3 | 52.0 | 63.0 | 38.6 | 40.1 |
| Vision-DeepResearch-8B (Ours) | 29.2 (+12.2) | 64.7 (+6.0) | 20.4 (+9.1) | 69.6 (+17.6) | 76.7 (+13.7) | 42.6 (+4.0) | 50.5 (+10.4) |
| Qwen3-VL-30B-A3B-Instruct (Agentic) | 20.2 | 57.7 | 10.0 | 55.0 | 60.0 | 42.6 | 40.9 |
| Vision-DeepResearch-30B-A3B (Ours) | 37.8 (+17.6) | 74.2 (+16.5) | 28.5 (+18.5) | 69.6 (+14.6) | 77.6 (+17.6) | 53.7 (+11.1) | 56.9 (+16.0) |
Teaser
Vision-DeepResearch

VDR-Bench

Data Pipeline
Vision-DeepResearch

VDR-Bench

Quickstart
Environment Setup
# 1. Clone the repository
git clone https://github.com/Osilly/Vision-DeepResearch.git
cd Vision-DeepResearch
# 2. Install verl
cd rllm/verl
pip install -e .
# 3. Install Megatron-LM
cd ../../Megatron-LM
pip install -e .
# 4. Install mbridge
cd ../mbridge
pip install -e .
# 5. Install rllm
cd ../rllm
pip install -e .
# 6. Install additional dependencies
pip install requests==2.32.3
pip install oss2
# 7. Return to the project root directory
cd ..
Data Preparation
SFT Data
Download the Cold-start dataset (Demo 1K).
You need to convert the data in Parquet format into the JSONL training format supported by ms-swift. We provide a conversion script for this purpose: ms-swift/run/data_prepare/convert_parquet2jsonl.sh.
You need to provide an --image_dir, where images stored as bytes in the Parquet file will be converted to .png/.jpg files and saved to disk.
RL Data
Download the RL dataset (Demo 1K).
First, you need to convert the data in Parquet format into the JSONL format. We provide a conversion script for this purpose: rllm/vision_deepresearch_async_workflow/data_prepare/convert_parquet2jsonl.sh.
Then, you need to run rllm/vision_deepresearch_async_workflow/data_prepare/register_rl_dataset.sh to register the RL dataset.
SFT Train
cd ms-swift
bash run/vision_deepresearch_SFT_30B_A3B_megatron_lr2e5_2ep.sh
RL Train
First, deploy the Extract model (used to summarize web page contents) and the Judge model:
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 vllm serve \
Qwen/Qwen3-VL-30B-A3B-Instruct \
--host 0.0.0.0 \
--port 8001 \
--tensor-parallel-size 8 \
--gpu-memory-utilization 0.8 \
--served-model-name "Qwen3-VL-30B-A3B-Instruct" \
--max_model_len 160000 \
--mm-processor-cache-gb 0 \
--no-enable-prefix-caching
Then, modify the vLLM URL service endpoints for JUDGE_MODEL and EXTRACT_MODEL in rllm/.env, and enter your SERP_API_KEY, JINA_API_KEY, and OSS configuration.
Run RL train.
cd rllm
bash vision_deepresearch_async_workflow/run/vision_deepresearch_30B_A3B_grpo_plus_bfloat16_sglang_megatron_128batch_128mini_8n.sh
Eval
Run the command below to start an OpenAI-compatible API service:
Vision-DeepResearch model:
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 vllm serve \
Osilly/Vision-DeepResearch-8B \
--host 0.0.0.0 \
--port 8001 \
--tensor-parallel-size 8 \
--gpu-memory-utilization 0.8 \
--served-model-name "Vision-DeepResearch-8B" \
--max_model_len 160000 \
--mm-processor-cache-gb 0 \
--no-enable-prefix-caching
Extract model (used to summarize web page contents) and Judge model:
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 vllm serve \
Qwen/Qwen3-VL-30B-A3B-Instruct \
--host 0.0.0.0 \
--port 8001 \
--tensor-parallel-size 8 \
--gpu-memory-utilization 0.8 \
--served-model-name "Qwen3-VL-30B-A3B-Instruct" \
--max_model_len 160000 \
--mm-processor-cache-gb 0 \
--no-enable-prefix-caching
Modify the vLLM URL service endpoints for JUDGE_MODEL and EXTRACT_MODEL in rllm/.env, and enter your SERP_API_KEY, JINA_API_KEY, and OSS configuration.
Modify the base-url and model (the Vision DeepResearch vLLM service endpoint and model name) in rllm/eval/run_eval.sh. For the data format of test.parquet, refer to rllm/eval/README.md.
Run rllm/eval/run_eval.sh to start inference.
bash rllm/eval/run_eval.sh
Star History
Citation
@article{huang2026vision,
title={Vision-DeepResearch: Incentivizing DeepResearch Capability in Multimodal Large Language Models},
author={Huang, Wenxuan and Zeng, Yu and Wang, Qiuchen and Fang, Zhen and Cao, Shaosheng and Chu, Zheng and Yin, Qingyu and Chen, Shuang and Yin, Zhenfei and Chen, Lin and others},
journal={arXiv preprint arXiv:2601.22060},
year={2026}
}
@article{zeng2026vision,
title={Vision-DeepResearch Benchmark: Rethinking Visual and Textual Search for Multimodal Large Language Models},
author={Zeng, Yu and Huang, Wenxuan and Fang, Zhen and Chen, Shuang and Shen, Yufan and Cai, Yishuo and Wang, Xiaoman and Yin, Zhenfei and Chen, Lin and Chen, Zehui and others},
journal={arXiv preprint arXiv:2602.02185},
year={2026}
}