README_EN.md
December 23, 2025 · View on GitHub

Description
🎉 100+ diagrams covering LLMs, VLMs, RL / RLHF / GRPO / DPO / SFT / distillation, RAG and performance tuning.
🎉 Inspired by 《大模型算法:强化学习、微调与对齐》, and continually expanded.
🎉 Click Star ⭐ to follow for updates.
🎉 Click any image for high‑res view, or open the .svg files for infinite zoom.
Table of Contents
- Overall Architecture of Large Model Algorithms (Focusing on LLMs and VLMs)
- 【LLM basics】LLM overview
- 【LLM basics】LLM structure
- 【LLM basics】LLM generation and decoding
- 【LLM basics】LLM Input
- 【LLM basics】LLM output
- 【LLM basics】MLLM and VLM
- 【LLM basics】LLM training process
- 【SFT】Categories of fine-tuning techniques
- 【SFT】LoRA(1 of 2)
- 【SFT】LoRA(2 of 2)
- 【SFT】Prefix-Tuning
- 【SFT】Token ID and Token
- 【SFT】Loss of SFT(cross-entropy)
- 【SFT】Packing of multiple pieces of sample
- 【DPO】RLHF vs DPO
- 【DPO】DPO(Direct Preference Optimization)
- 【DPO】Overview of DPO training
- 【DPO】Impact of the β parameter on DPO
- 【DPO】Effect of implicit reward differences on the magnitude of parameter updates
- 【Optimization without training】Comparison of CoT and traditional Q&A
- 【Optimization without training】CoT、Self-consistency CoT、ToT、GoT [87]
- 【Optimization without training】Exhaustive Search
- 【Optimization without training】Greedy Search
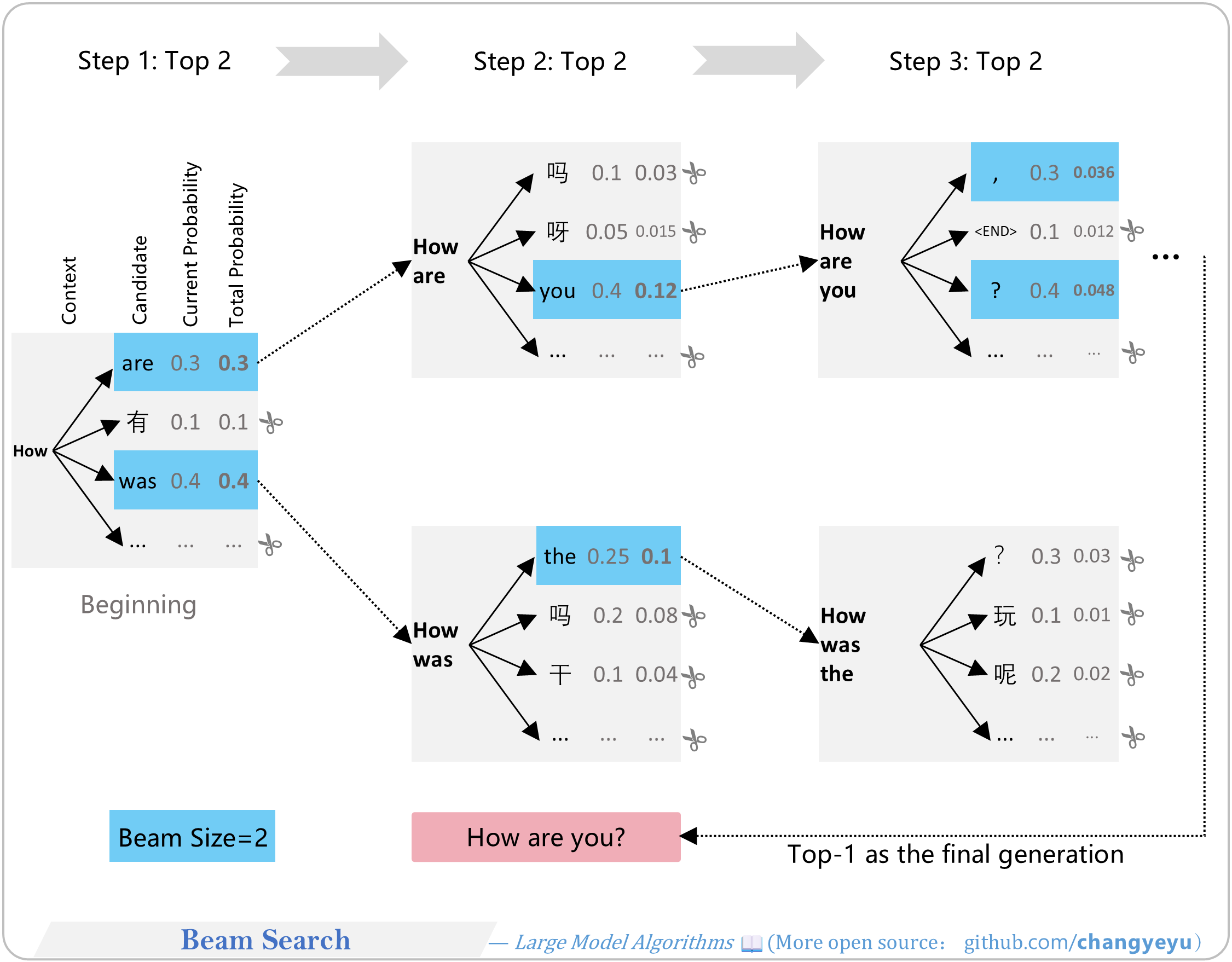
- 【Optimization without training】Beam Search
- 【Optimization without training】Multinomial Sampling
- 【Optimization without training】Top-K Sampling
- 【Optimization without training】Top-P Sampling
- 【Optimization without training】RAG(Retrieval-Augmented Generation)
- 【Optimization without training】Function Calling
- 【RL basics】History of RL
- 【RL basics】Three major machine learning paradigms
- 【RL basics】Basic architecture of RL
- 【RL basics】Fundamental Concepts of RL
- 【RL basics】Markov Chain vs MDP
- 【RL basics】Using dynamic ε values under the ε-greedy strategy
- 【RL basics】Comparison of RL training paradigms
- 【RL basics】Classification of RL
- 【RL basics】Return(cumulative reward)
- 【RL basics】Backwards iteration and computation of return G
- 【RL basics】Reward, Return, and Value
- 【RL basics】Qπ and Vπ
- 【RL basics】Estimate the value through Monte Carlo(MC)
- 【RL basics】TD target and TD error
- 【RL basics】TD(0), n-step TD, and MC
- 【RL basics】Characteristics of MC and TD methods
- 【RL basics】MC, TD, DP, and exhaustive search [32]
- 【RL basics】DQN model with two input-output structures
- 【RL basics】How to use DQN
- 【RL basics】DQN's overestimation problem
- 【RL basics】Value-Based vs Policy-Based
- 【RL basics】Policy gradient
- 【RL basics】Multi-agent reinforcement learning(MARL)
- 【RL basics】Multi-agent DDPG [41]
- 【RL basics】Imitation learning(IL)
- 【RL basics】Behavior cloning(BC)
- 【RL basics】Inverse RL(IRL) and RL
- 【RL basics】Model-Based and Model-Free
- 【RL basics】Feudal RL
- 【RL basics】Distributional RL
- 【Policy Optimization & Variants】Actor-Critic
- 【Policy Optimization & Variants】Comparison of baseline and advantage
- 【Policy Optimization & Variants】GAE(Generalized Advantage Estimation)
- 【Policy Optimization & Variants】TRPO and its trust region
- 【Policy Optimization & Variants】Importance sampling
- 【Policy Optimization & Variants】PPO-Clip
- 【Policy Optimization & Variants】Policy model update process in PPO training
- 【Policy Optimization & Variants】PPO Pseudocode
- 【Policy Optimization & Variants】GRPO & PPO [72]
- 【Policy Optimization & Variants】Deterministic policy vs. Stochastic policy
- 【Policy Optimization & Variants】DPG
- 【Policy Optimization & Variants】DDPG(Deep Deterministic Policy Gradient)
- 【RLHF and RLAIF】RL modeling of language models
- 【RLHF and RLAIF】Two-stage training process of RLHF
- 【RLHF and RLAIF】Structure of the reward model
- 【RLHF and RLAIF】Input and output of the reward model
- 【RLHF and RLAIF】Reward deviation and loss
- 【RLHF and RLAIF】Training of the reward model
- 【RLHF and RLAIF】Relationship between the four models in PPO
- 【RLHF and RLAIF】The structure and init of the four models in PPO
- 【RLHF and RLAIF】A value model with a dual-head structure
- 【RLHF and RLAIF】Four models can share one base in RLHF
- 【RLHF and RLAIF】Inputs and Outputs of Each Model in PPO
- 【RLHF and RLAIF】The Process of Calculating KL in PPO
- 【RLHF and RLAIF】RLHF Training Based on PPO
- 【RLHF and RLAIF】Rejection Sampling Fine-tuning
- 【RLHF and RLAIF】RLAIF vs RLHF
- 【RLHF and RLAIF】CAI(Constitutional AI)
- 【RLHF and RLAIF】OpenAI RBR(Rule-Based Reward)
- 【Reasoning capacity optimization】Knowledge Distillation Based on CoT
- 【Reasoning capacity optimization】Distillation Based on DeepSeek
- 【Reasoning capacity optimization】ORM(Outcome Reward Model) & PRM (Process Reward Model)
- 【Reasoning capacity optimization】Four Key Steps of Each MCTS
- 【Reasoning capacity optimization】MCTS
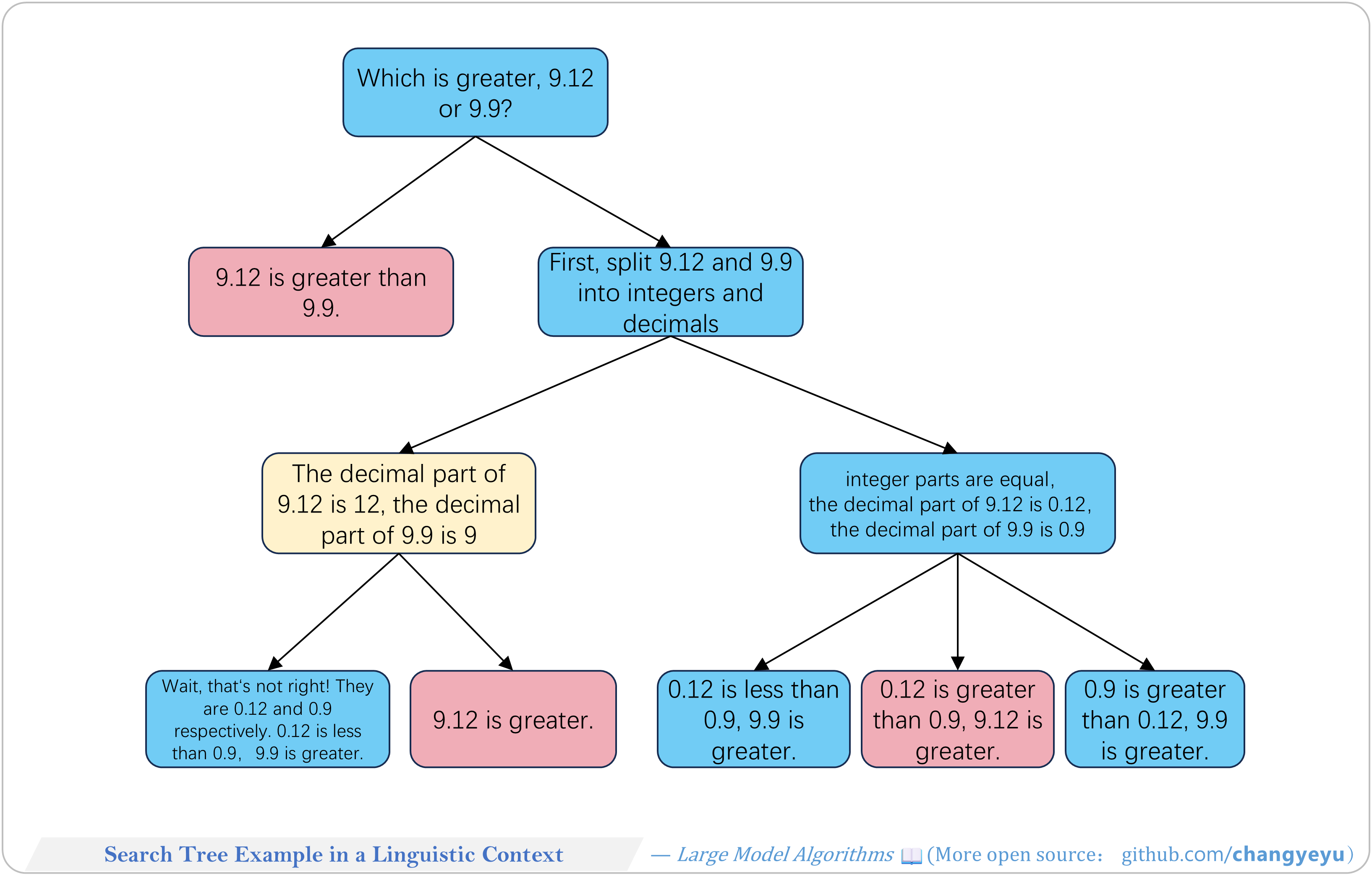
- 【Reasoning capacity optimization】Search Tree Example in a Linguistic Context
- 【Reasoning capacity optimization】BoN(Best-of-N) Sampling
- 【Reasoning capacity optimization】Majority Vote
- 【Reasoning capacity optimization】Performance Growth of AlphaGo Zero [179]
- 【LLM basics extended】Performance Optimization Map for Large Models
- 【LLM basics extended】ALiBi positional encoding
- 【LLM basics extended】Traditional knowledge distillation
- 【LLM basics extended】Numerical representation, quantization
- 【LLM basics extended】Forward and backward
- 【LLM basics extended】Gradient Accumulation
- 【LLM basics extended】Gradient Checkpoint(gradient recomputation)
- 【LLM basics extended】Full recomputation
- 【LLM basics extended】LLM Benchmark
- 【LLM basics extended】MHA、GQA、MQA、MLA
- 【LLM basics extended】RNN(Recurrent Neural Network)
- 【LLM basics extended】Pre-norm vs Post-norm
- 【LLM basics extended】BatchNorm & LayerNorm
- 【LLM basics extended】RMSNorm
- 【LLM basics extended】Prune
- 【LLM basics extended】Role of the temperature coefficient
- 【LLM basics extended】SwiGLU
- 【LLM basics extended】AUC、PR、F1、Precision、Recall
- 【LLM basics extended】RoPE positional encoding
- 【LLM basics extended】The effect of RoPE on each sequence position and each dim
- 📌 For Reference Section
- 📌 BibTeX Citation Format
Overall Architecture of Large Model Algorithms (Focusing on LLMs and VLMs)

【LLM basics】LLM overview
- This is the culmination of dozens of hours of dedicated effort; clicking the Star ⭐ at the top right ↗ of this repository is my greatest encouragement!
- LLMs mainly come in two forms: Decoder-Only or MoE (Mixture of Experts). The overall architectures are similar; the main difference is that MoE introduces multiple expert networks into the FFN (Feed-Forward Network) component.

【LLM basics】LLM structure
- LLMs mainly come in two forms: Decoder-Only or MoE (Mixture of Experts). The overall architectures are similar; the key difference is that MoE introduces multiple expert networks into the FFN (Feed-Forward Network) component.
- A typical LLM architecture can be divided into three parts: the input layer, the multi-layer stacked Decoder structure, and the output layer (including the language model head and the decoding module).
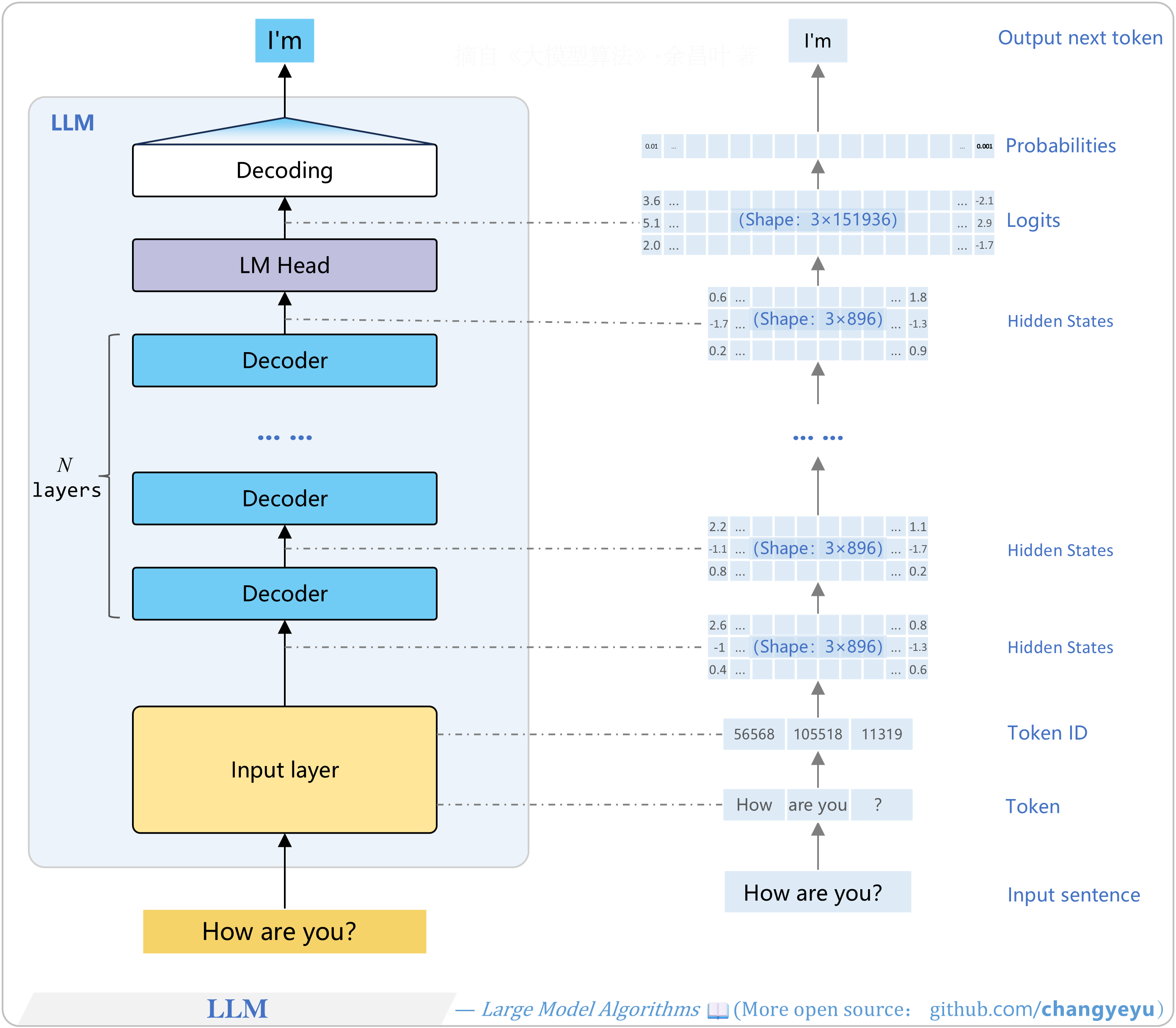
【LLM basics】LLM generation and decoding
- Decoding strategies are the core factors that determine the fluency, diversity, and overall performance of the final output text. Common decoding algorithms include: Greedy Search, Beam Search and its variants, Multinomial Sampling, Top-K Sampling, Top-P Sampling, Contrastive Search, Speculative Decoding, Lookahead Decoding, DoLa Decoding, and others.
- The output layer of an LLM is responsible for applying a decoding algorithm to the probability distribution to determine the final predicted next token(s).
- Based on the probability distribution, the decoding strategy (e.g., random sampling or selecting the highest probability) is applied to choose the next token. For example, under Greedy Search, the token “I'm” with the highest probability would be selected.
- Each token generation requires passing through all layers of the Transformer structure again.
- This diagram shows one-token-at-a-time prediction. There are also multi-token prediction schemes; see Chapter 4 of Large Model Algorithms: Reinforcement Learning, Fine-Tuning, and Alignment for details.
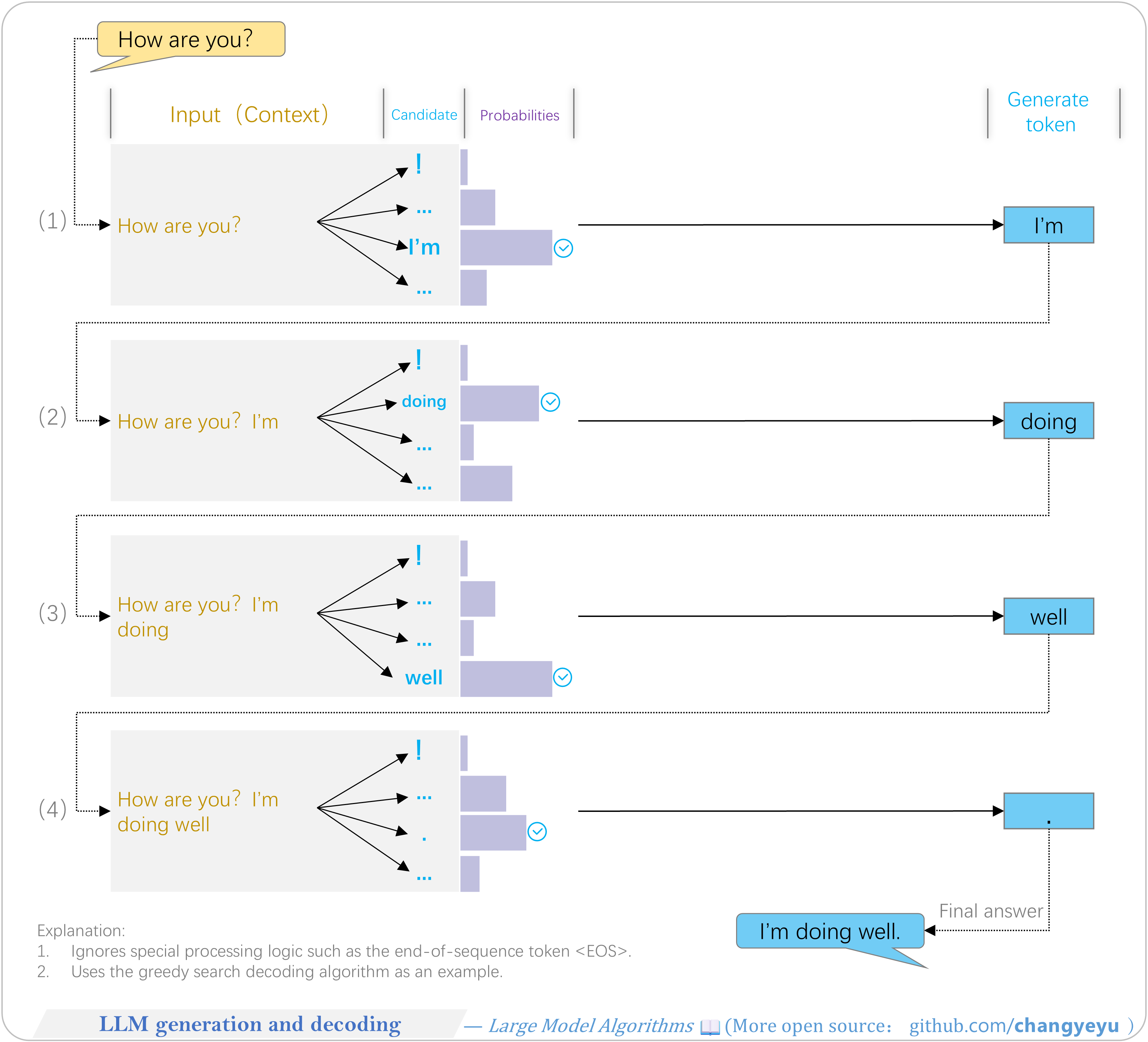
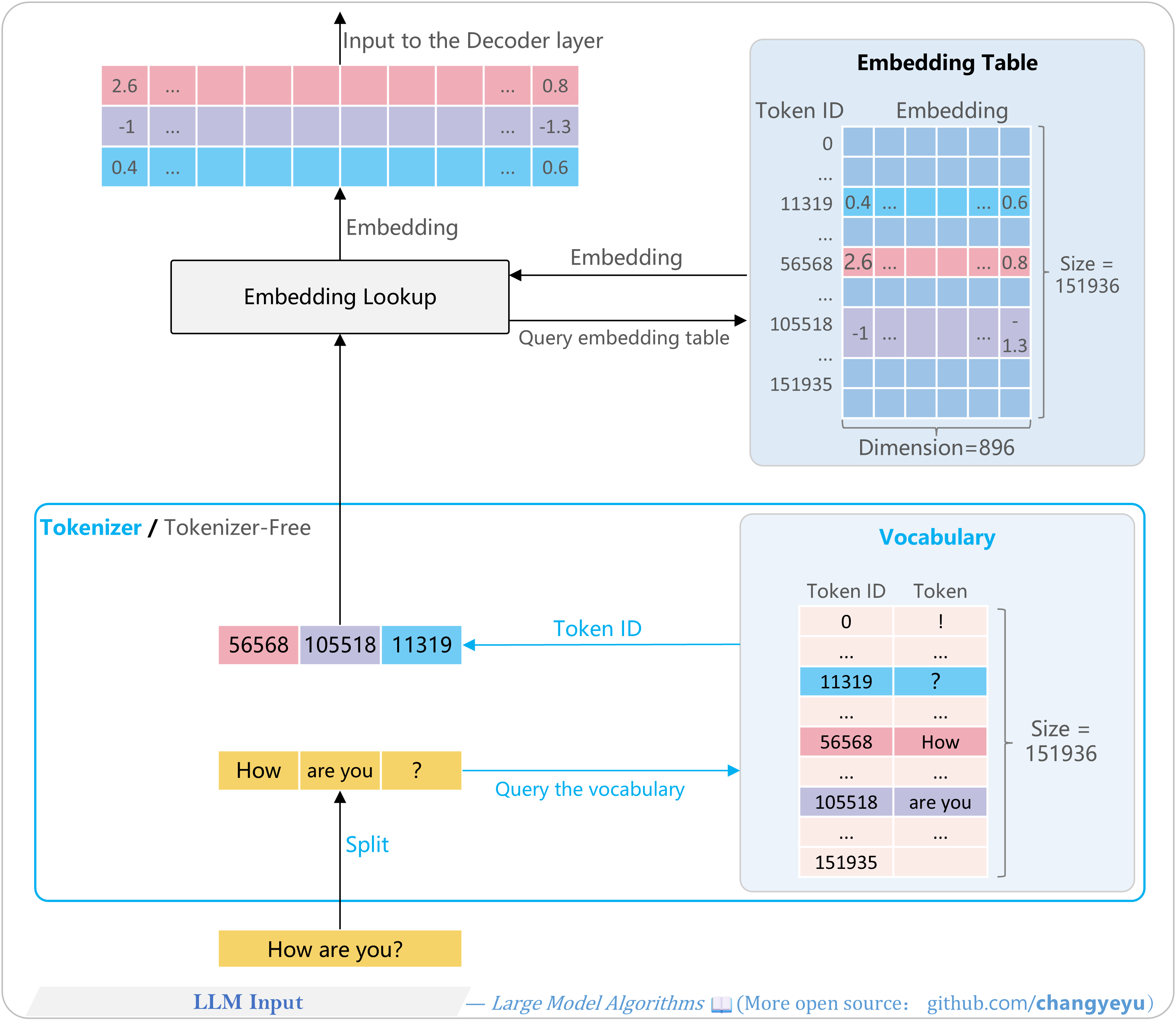
【LLM basics】LLM Input
- The input layer of an LLM converts input text into a multi-dimensional numerical tensor for processing by the model’s main structure.

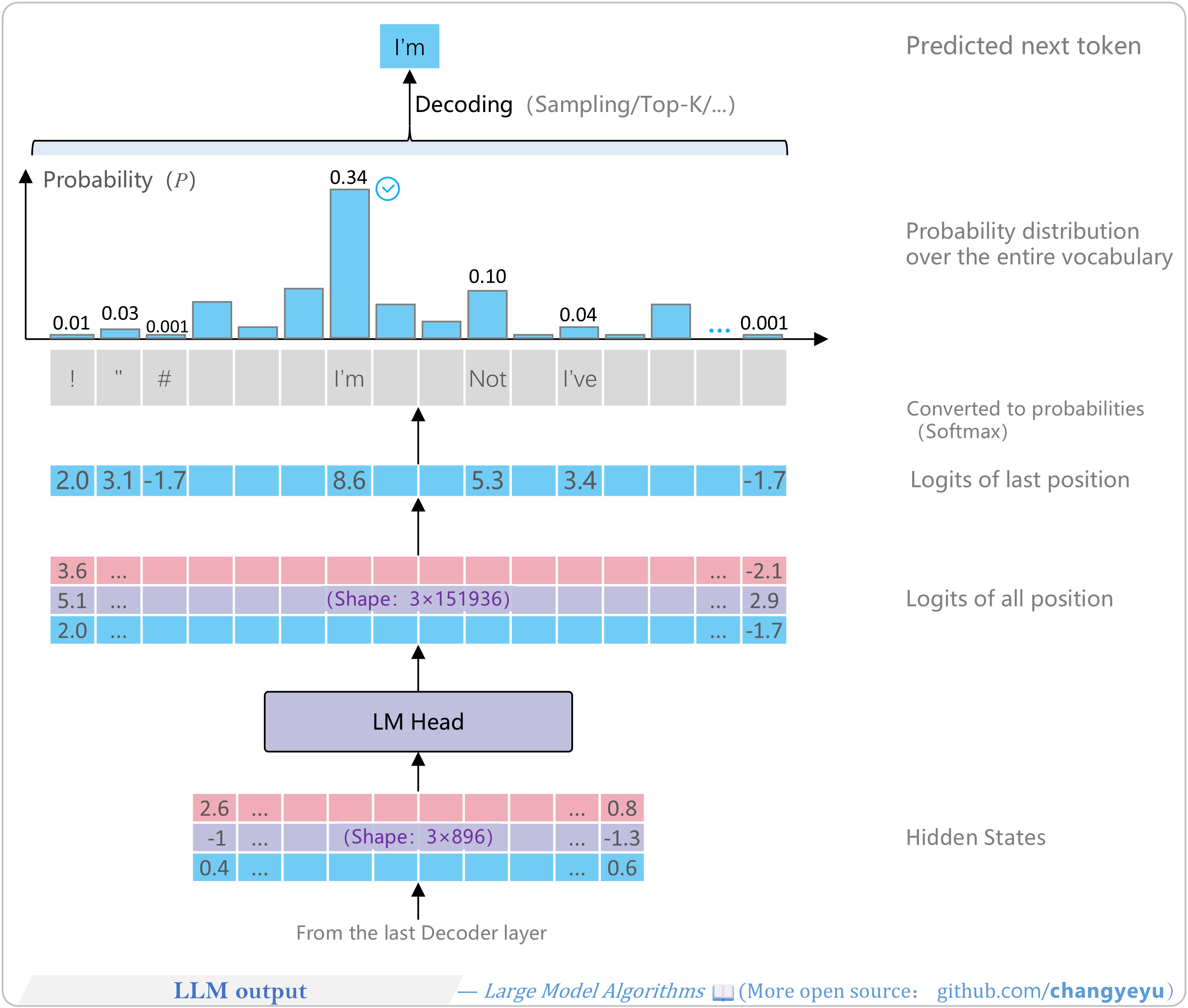
【LLM basics】LLM output
The output layer of an LLM predicts the next token (text) based on the hidden states (a multi-dimensional tensor). The process is as follows:
- (1) Input hidden states: The hidden states from the final Decoder layer serve as input to the LLM’s output layer. For example, a 3×896 tensor containing all semantic information of the prefix sequence.
- (2) Language Model Head (LM Head): Typically a fully connected layer that converts hidden states to logits (calculating only the last position’s logits during inference). For example, producing a 3×151936 matrix of scores for each vocabulary token.
- (3) Extract last position logits: Next-token prediction depends only on the logits at the last position, so we extract the final row from the logits matrix, yielding a 151936-dimensional vector [2.0, 3.1, −1.7, …, −1.7].
- (4) Convert to probability distribution (Softmax): Apply Softmax to the logits to obtain probabilities for each vocabulary token. For example, a 151936-dimensional vector [0.01, 0.03, 0.001, …, 0.001], summing to 1. A higher probability indicates a higher chance of being chosen as the next token (e.g., “I'm” has p=0.34).
- (5) Decoding: Apply the decoding strategy (e.g., random sampling or choosing the maximum) to the probability distribution to determine the next token. Under Greedy Search, select the token with the highest probability, such as “I'm”.
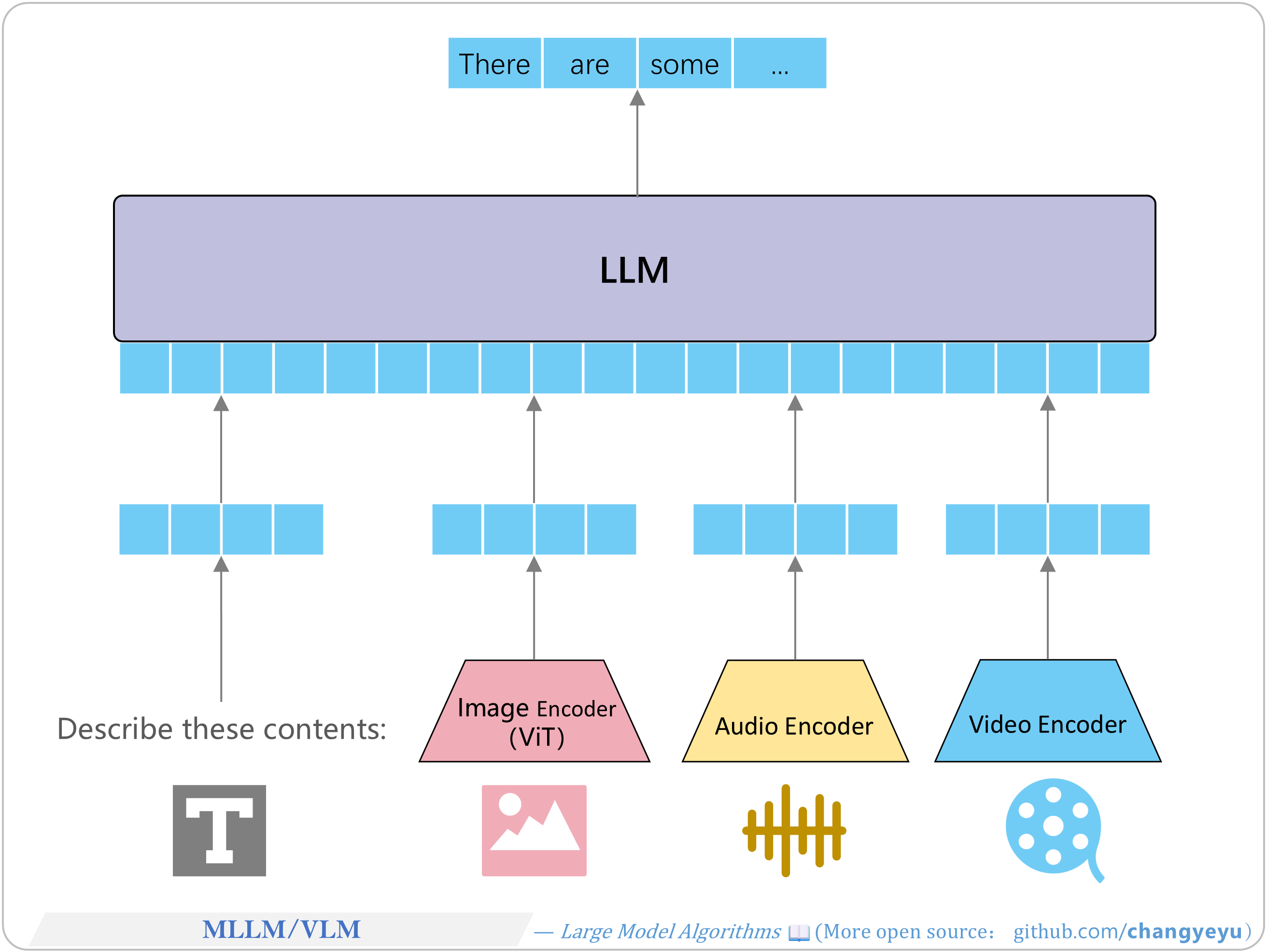
【LLM basics】MLLM and VLM
Depending on their focus, multimodal models are often referred to by various names:
- VLM (Vision-Language Model)
- MLLM (Multimodal Large Language Model)
- VLA (Vision-Language-Action Model)
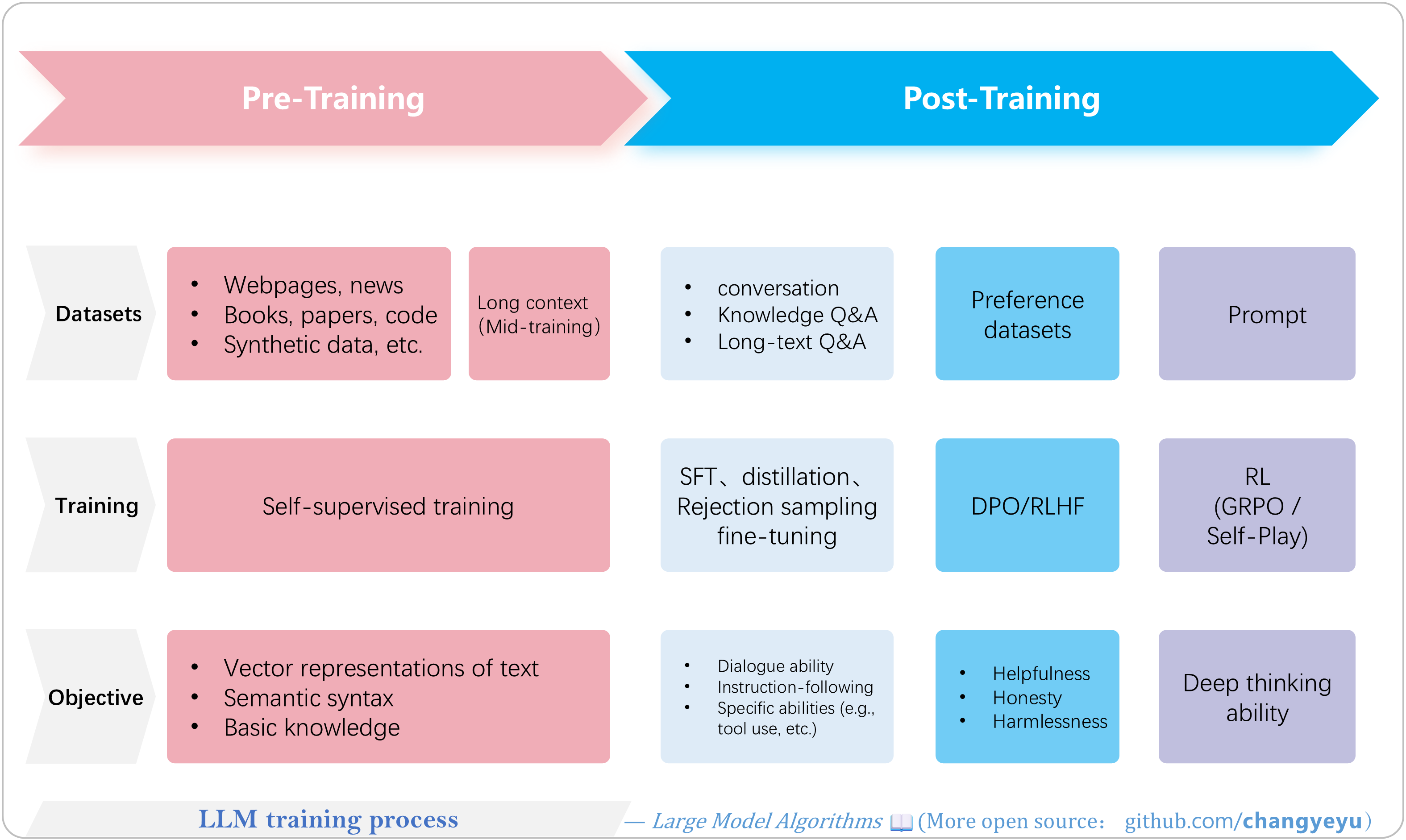
【LLM basics】LLM training process
- Training large models involves two main stages: Pre-Training and Post-Training. Each stage uses different data, paradigms (algorithms), objectives, and hyperparameters.
- Pre-Training includes early training (short-context on massive data), mid-training (long-text/long-context), and Annealing. This stage is self-supervised, uses the most data, and is the most compute-intensive.
- Post-Training encompasses various fine-tuning paradigms, including but not limited to SFT (Supervised Fine-Tuning), Distillation, RSFT (Rejection Sampling Fine-Tuning), RLHF (Reinforcement Learning from Human Feedback), DPO (Direct Preference Optimization), and other RL methods like GRPO and PPO. Some steps, like RSFT, can iterate multiple times.
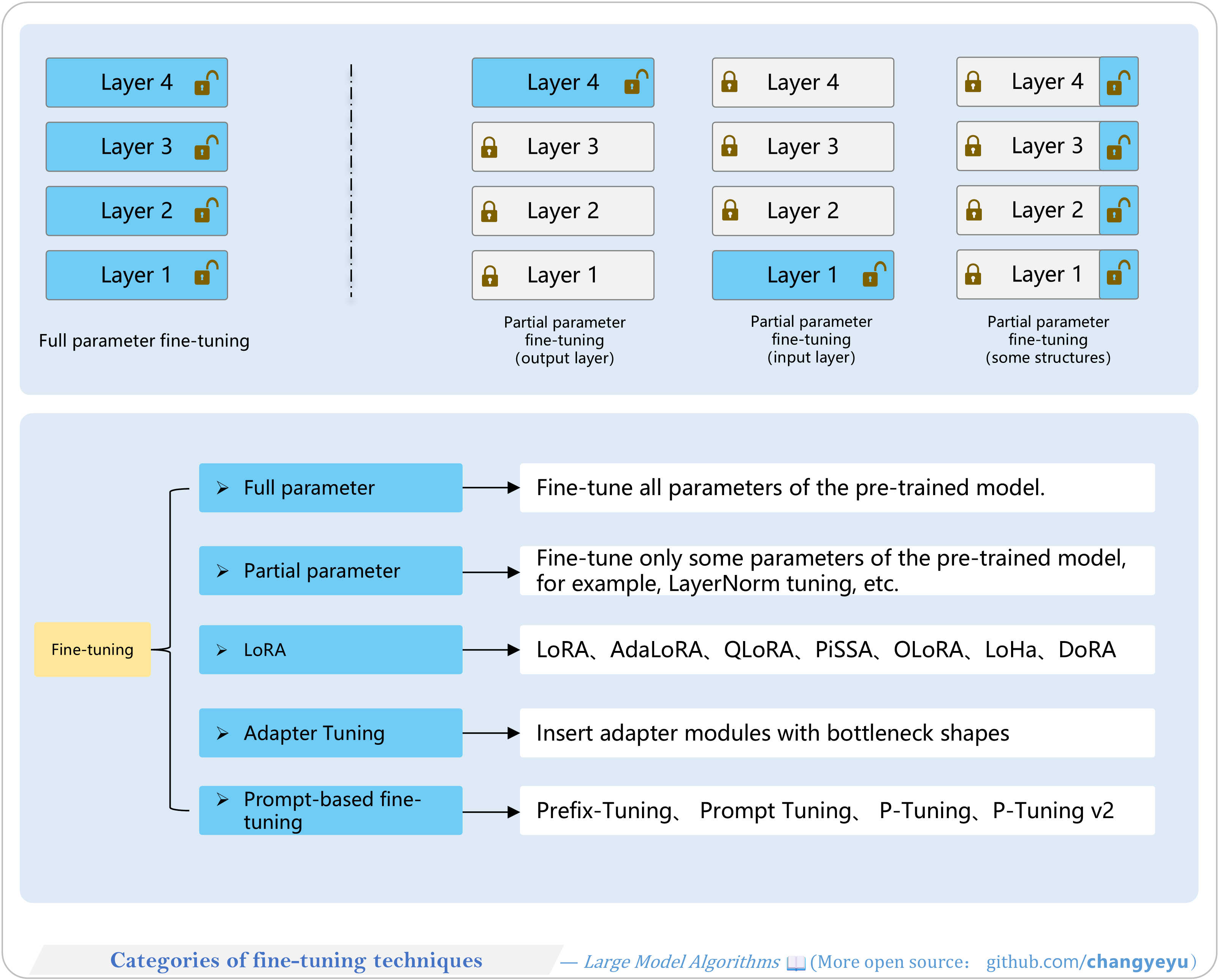
【SFT】Categories of fine-tuning techniques
- There are many fine-tuning techniques for SFT, as shown in the diagram: the first two methods only require fine-tuning the pretrained model body (low development cost), while Parallel Low-Rank Fine-Tuning and Adapter Tuning introduce additional modules and are more complex. All these modify model parameters; prompt-based tuning instead fine-tunes the input.
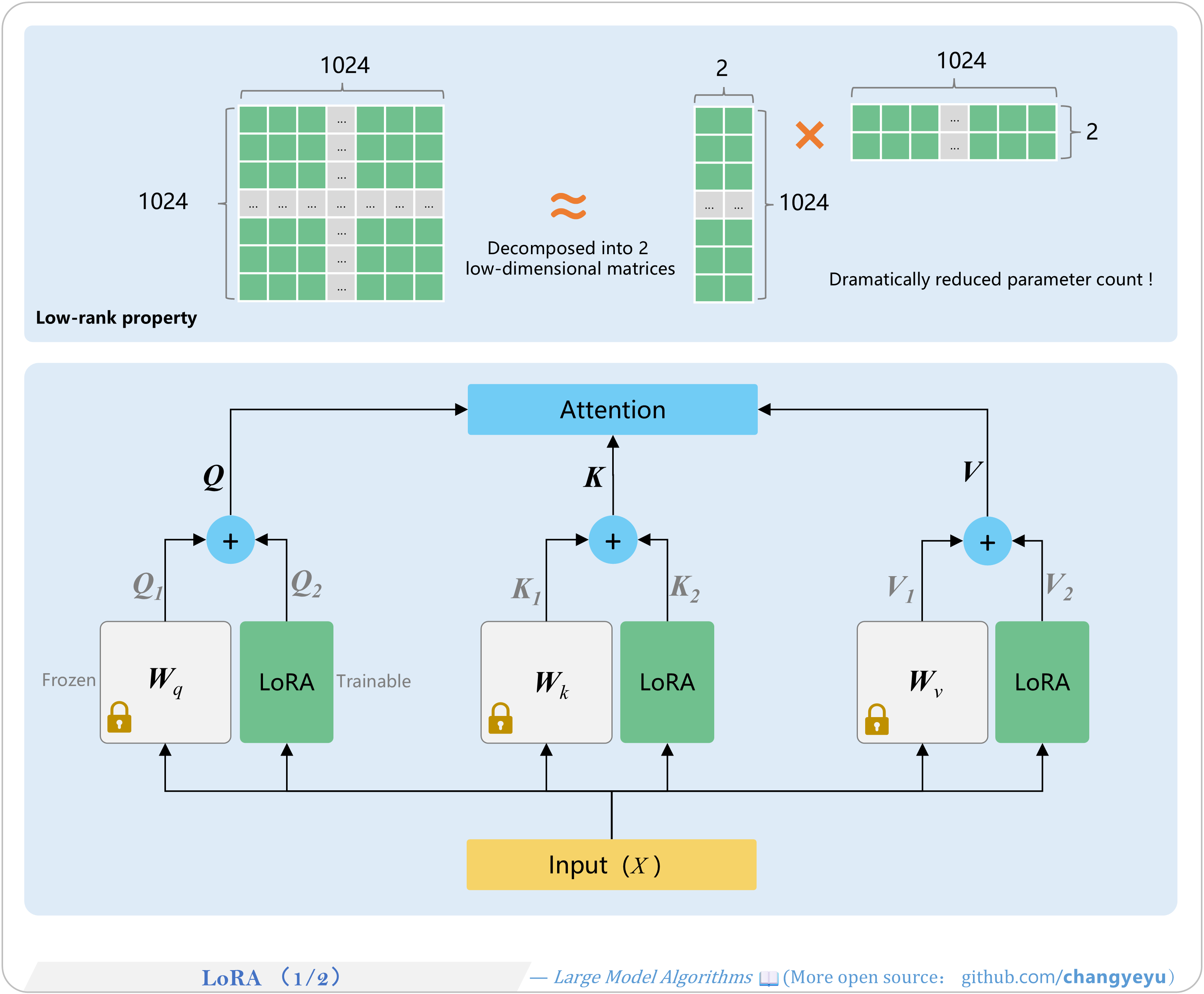
【SFT】LoRA(1 of 2)
- LoRA (Low-Rank Adaptation) was introduced by Microsoft Research in 2021. Its efficient fine-tuning and strong performance have made it widely adopted. The core idea is that the parameter difference ∆W before and after fine-tuning is low-rank.
- A low-rank matrix contains redundancy; decomposing it into smaller matrices preserves most useful information. For example, a 1024×1024 matrix can be approximated by a 1024×2 and a 2×1024 matrix product, reducing parameters to ~0.4%.
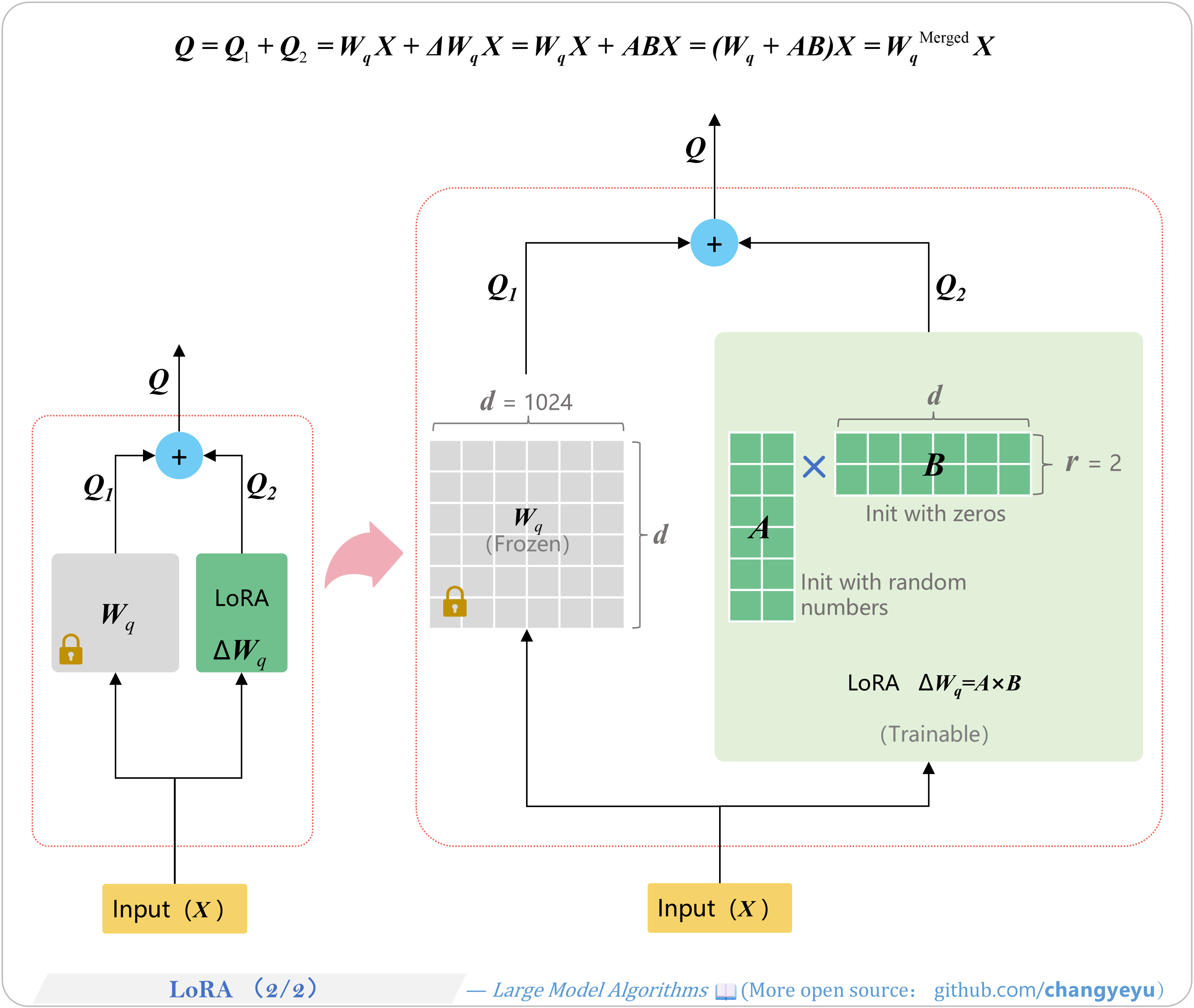
【SFT】LoRA(2 of 2)
- Initialization of A and B:
- A is randomly initialized (e.g., Kaiming initialization);
- B is zero-initialized or uses very small random values.
- The goal is to ensure the inserted LoRA module does not overly perturb model outputs at the start of training.
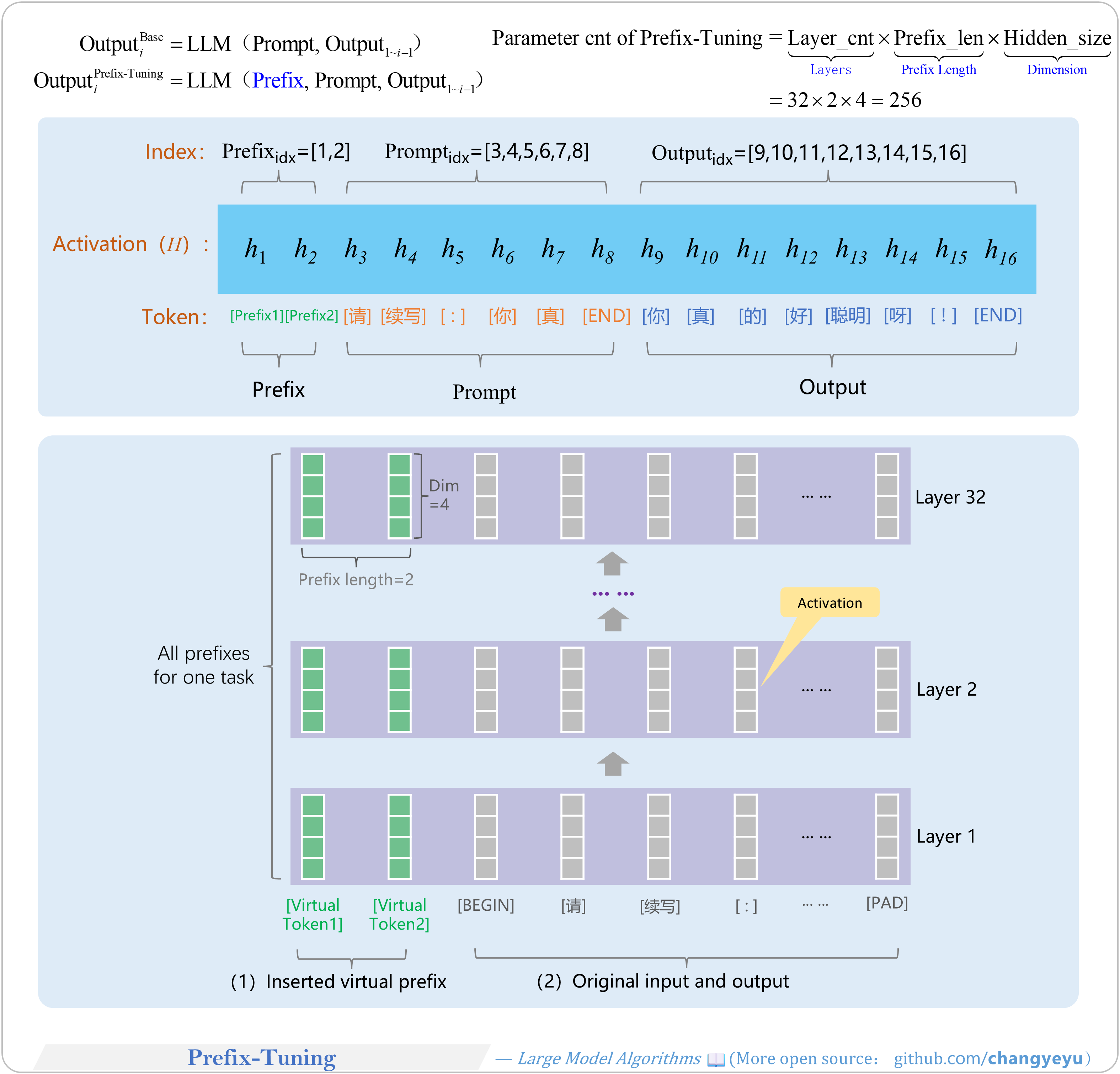
【SFT】Prefix-Tuning
- Prefix-Tuning, proposed by Stanford researchers, offers lightweight fine-tuning by inserting a trainable sequence of vectors (the “prefix”) at the start of input. These vectors act as virtual tokens in subsequent Transformer attention.
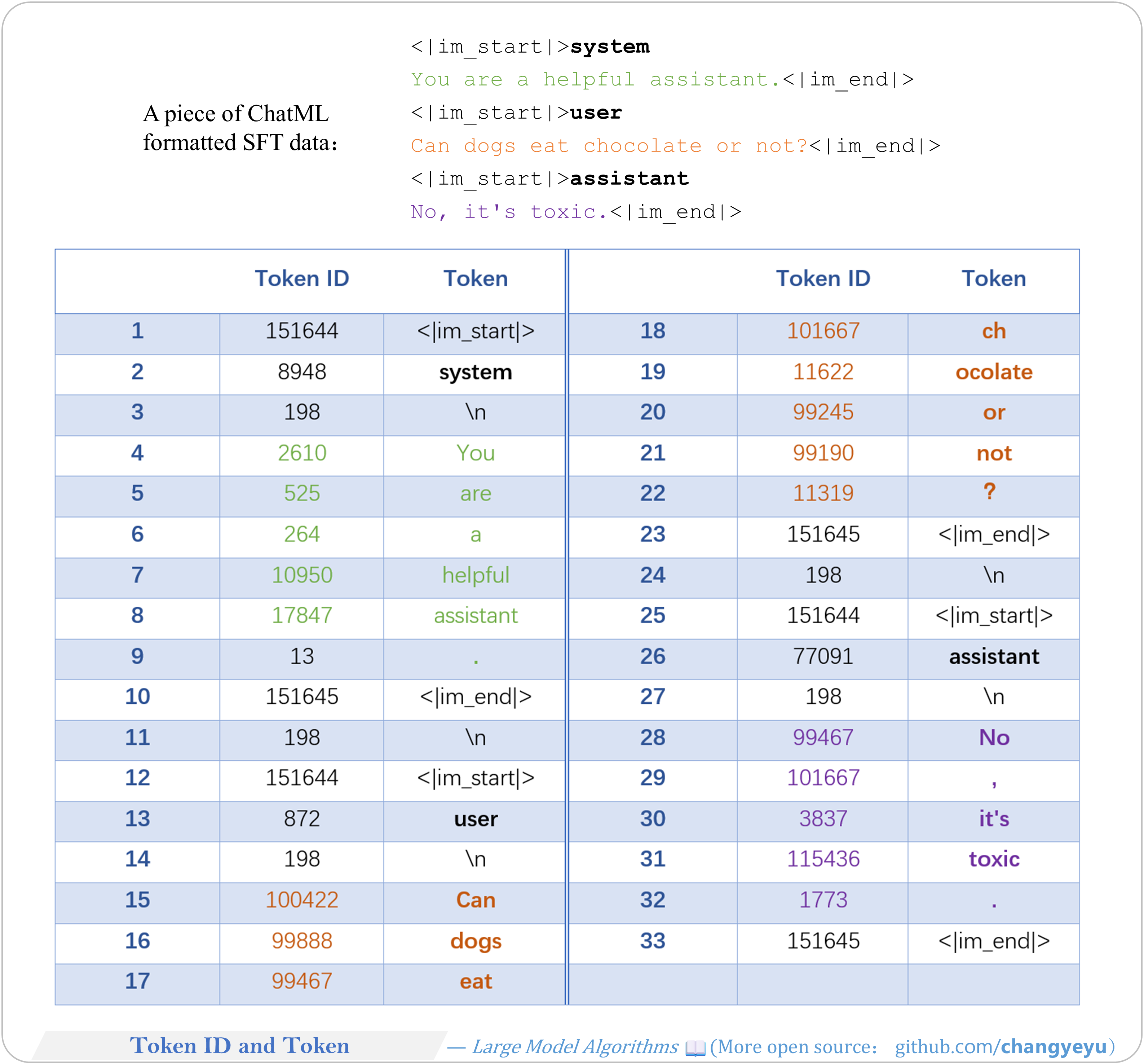
【SFT】Token ID and Token
- For example data (preprocessed in ChatML), tokenization produces 33 tokens at 33 positions.
- Each Token ID maps one-to-one with a token.

【SFT】Loss of SFT(cross-entropy)
- Like pre-training, SFT uses cross-entropy (CE) loss.


【SFT】Packing of multiple pieces of sample
- Training uses fixed-length input. Short sequences are padded, wasting compute.
- Packing concatenates multiple samples into one fixed-length sequence, resetting position IDs and attention masks to keep samples independent.

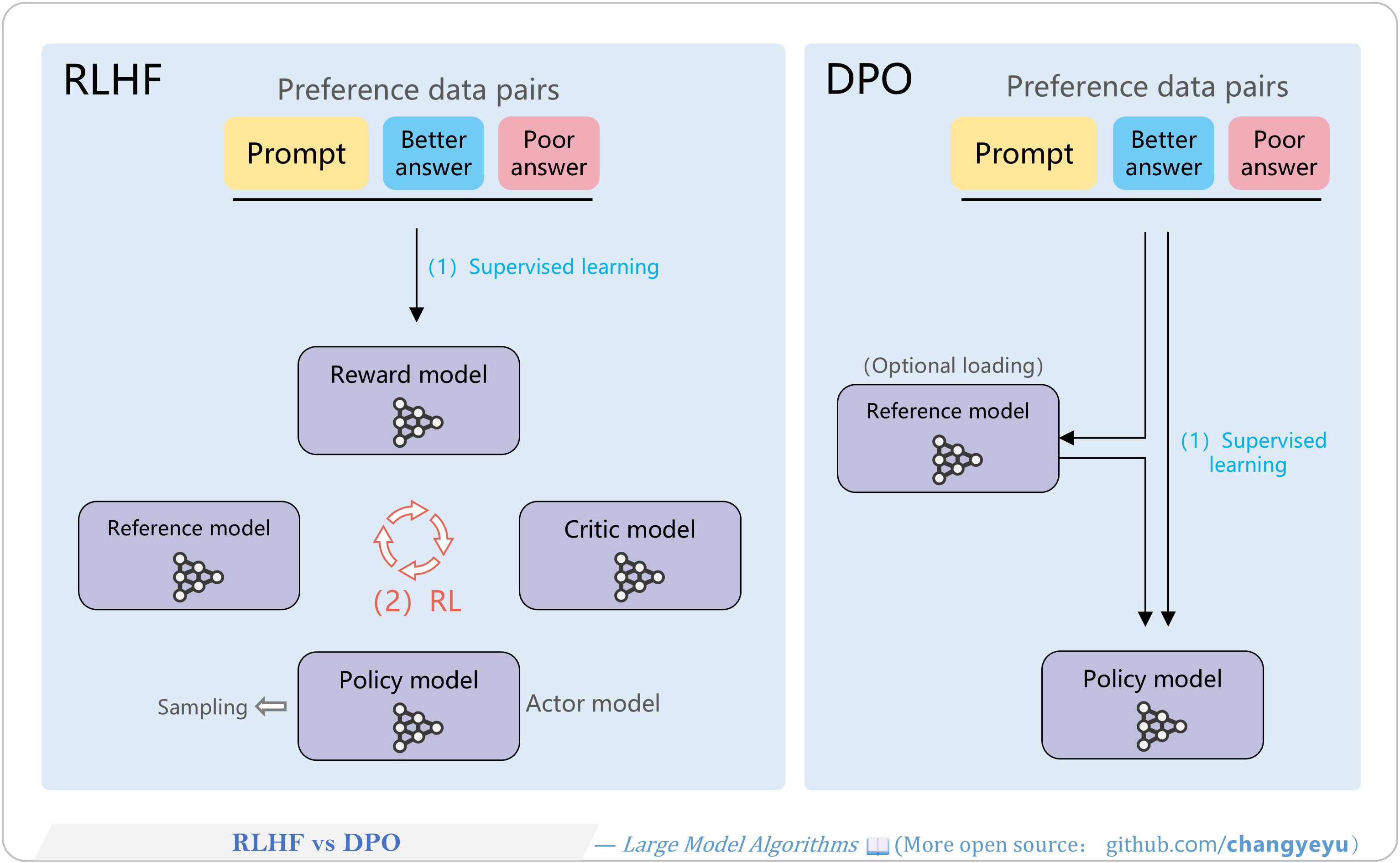
【DPO】RLHF vs DPO
Unlike RLHF, DPO simplifies alignment via supervised learning:
- Streamlined: DPO directly optimizes the policy model, no reward model training needed, and uses only provided preference data—no sampling required.
- Stability: As a supervised method, DPO avoids RL’s instability.
- Low overhead: Only one model is loaded (policy model); reference model outputs can be precomputed.
【DPO】DPO(Direct Preference Optimization)
- DPO, introduced by Stanford et al. in 2023, is a preference-optimization algorithm for LLM/VLM alignment.
- It greatly simplifies PPO-based RLHF by skipping reward model training and directly optimizing the policy model—hence “Direct”.
- Two models are used:
- Policy model: initialized from the SFT model copy.
- Reference model: also copied from SFT (or a stronger model), with attention to KL-distance and data distribution.
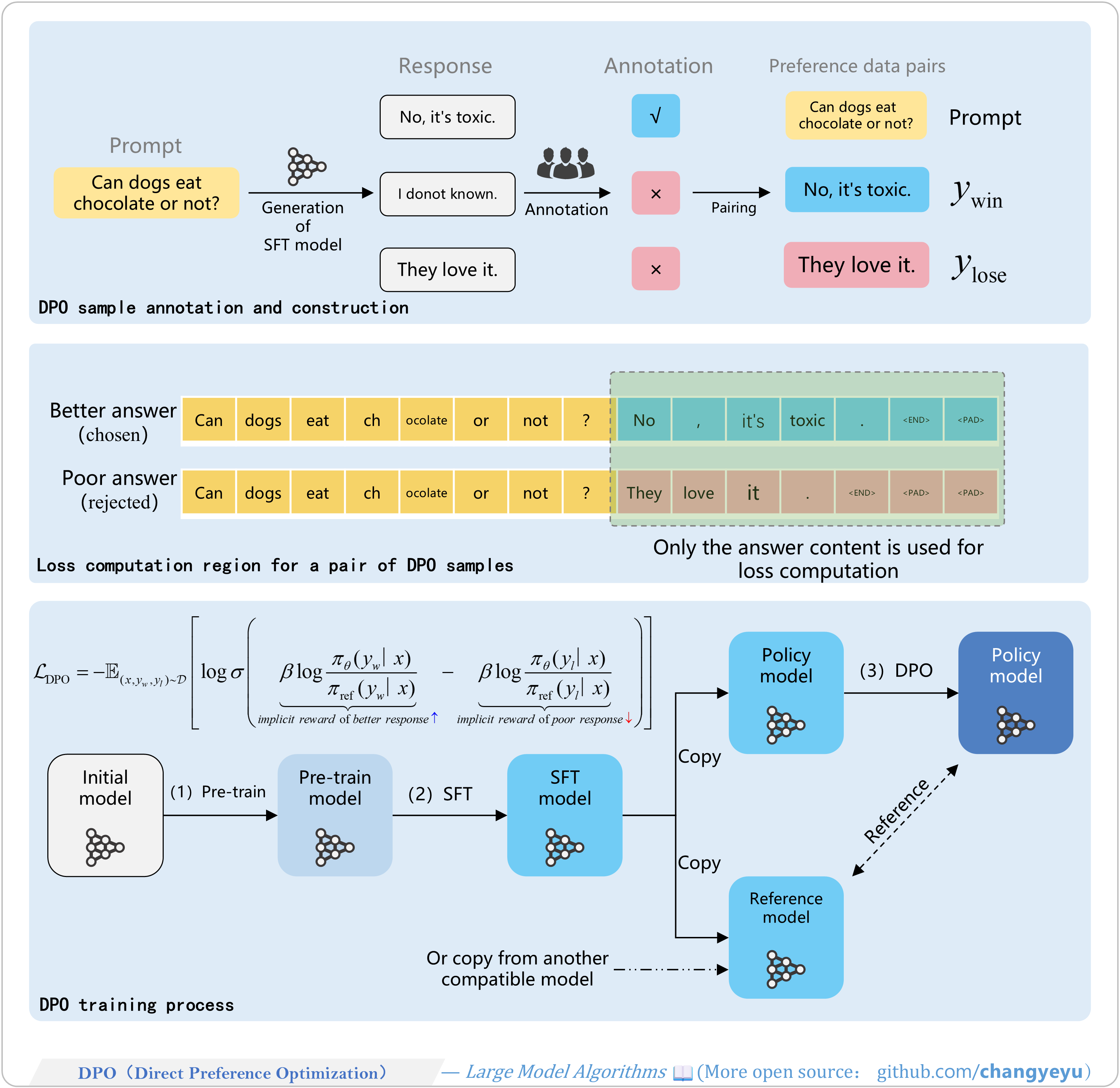
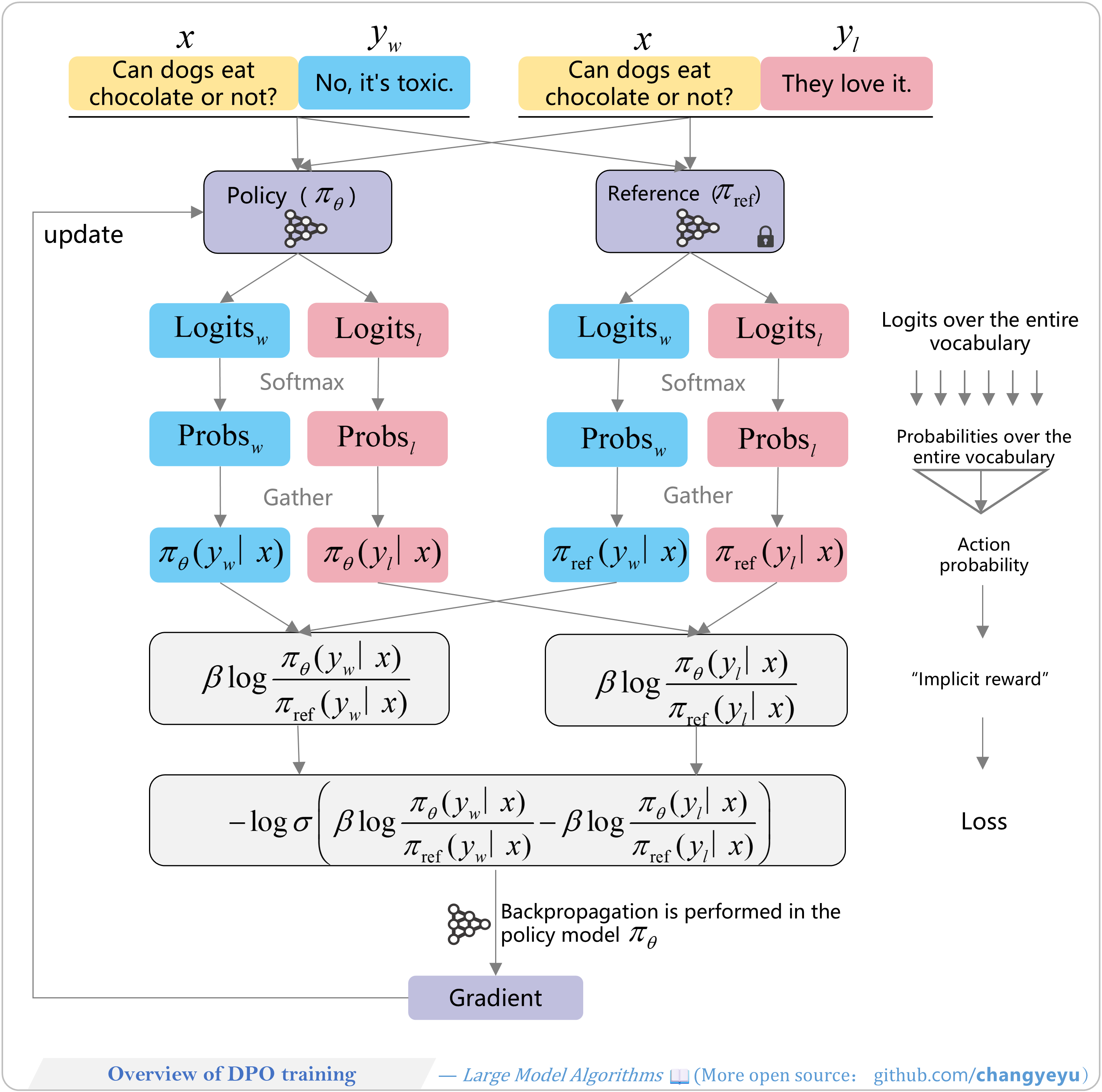
【DPO】Overview of DPO training
- You may load two models (policy and reference) or just one (policy). This overview illustrates loading both. Blue blocks denote the “good response” and its intermediate results; pink blocks, the “bad response” and results.
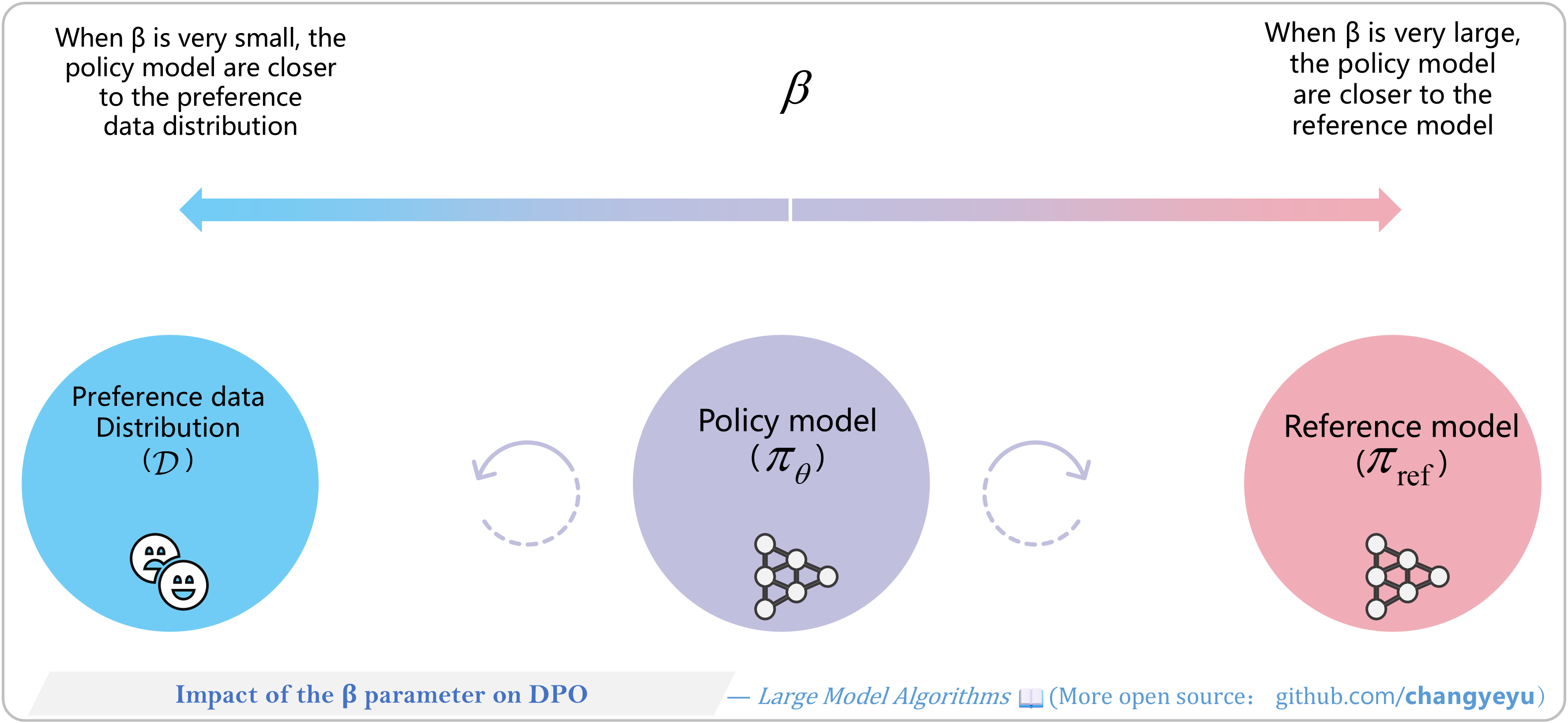
【DPO】Impact of the β parameter on DPO
- In DPO, β plays a role similar to its use in RLHF.
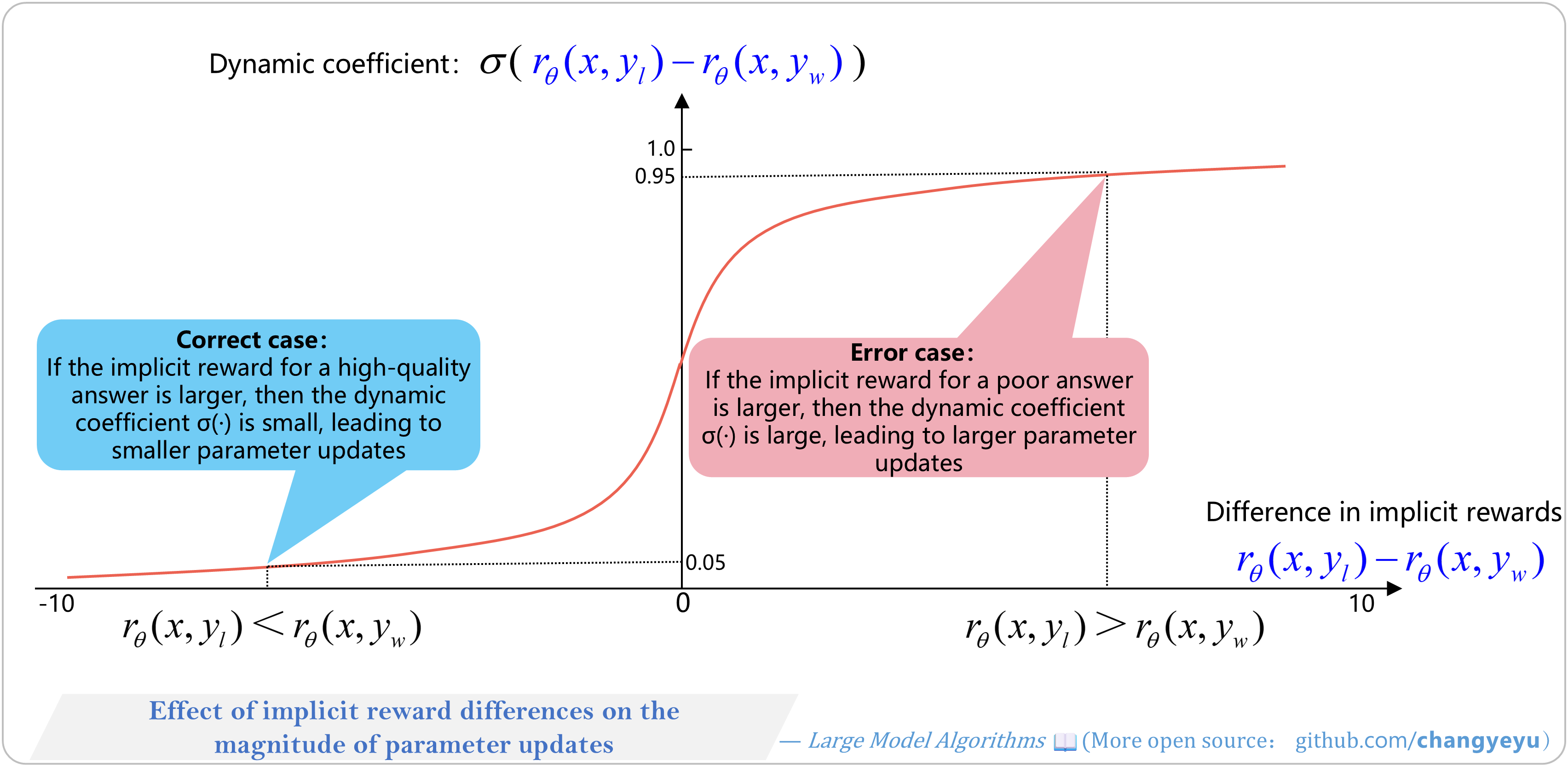
【DPO】Effect of implicit reward differences on the magnitude of parameter updates
- DPO’s gradient update increases the probability of good responses and reduces that of bad ones. The gradient includes a dynamic coefficient reflecting the implicit reward difference—i.e., how much the implicit “reward model” deviates in judging preferences.
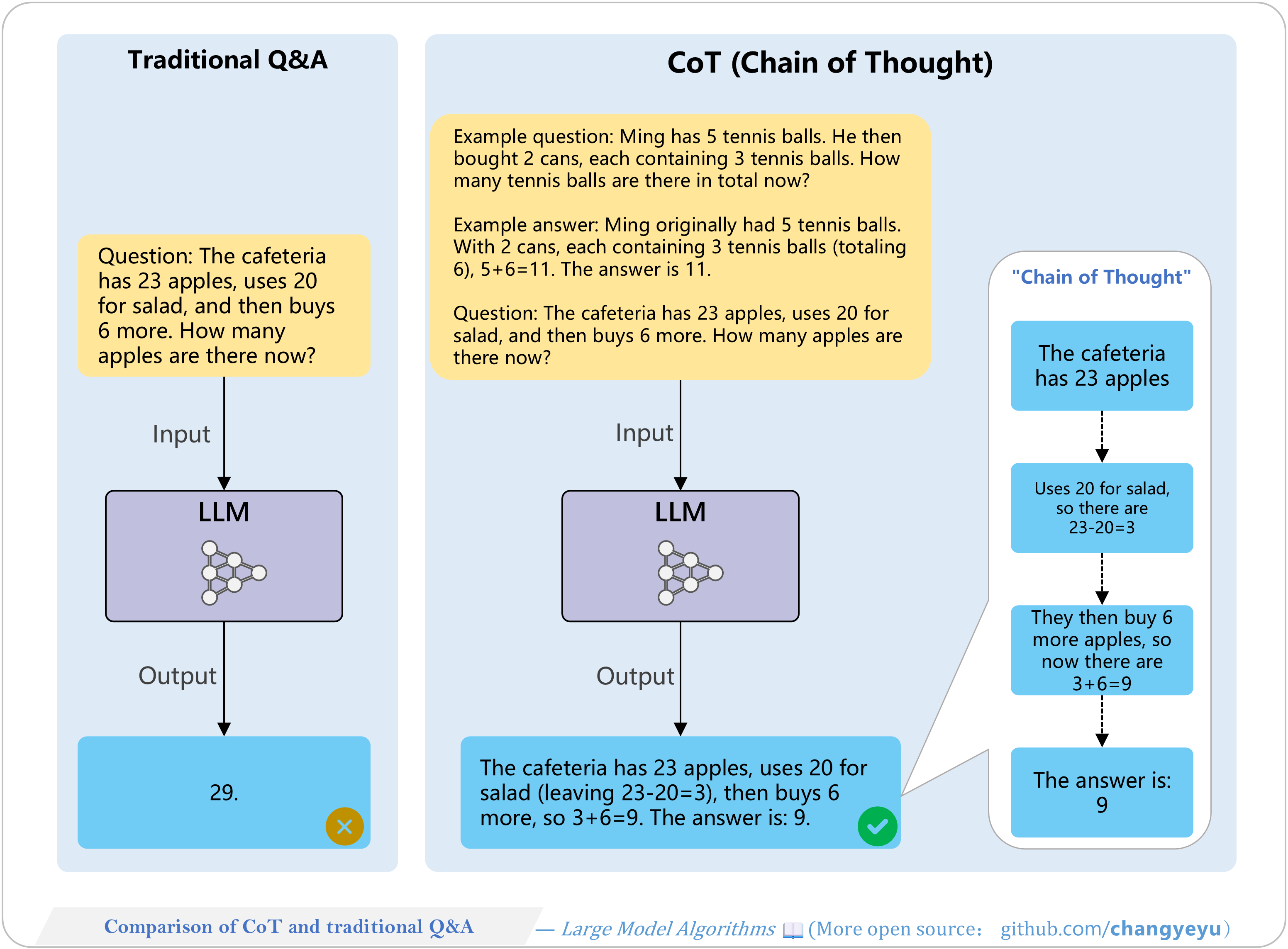
【Optimization without training】Comparison of CoT and traditional Q&A
- CoT (Chain of Thought), introduced by Jason Wei et al. at Google in 2022, is a major innovation that explicitly breaks down reasoning steps to improve performance on complex tasks.
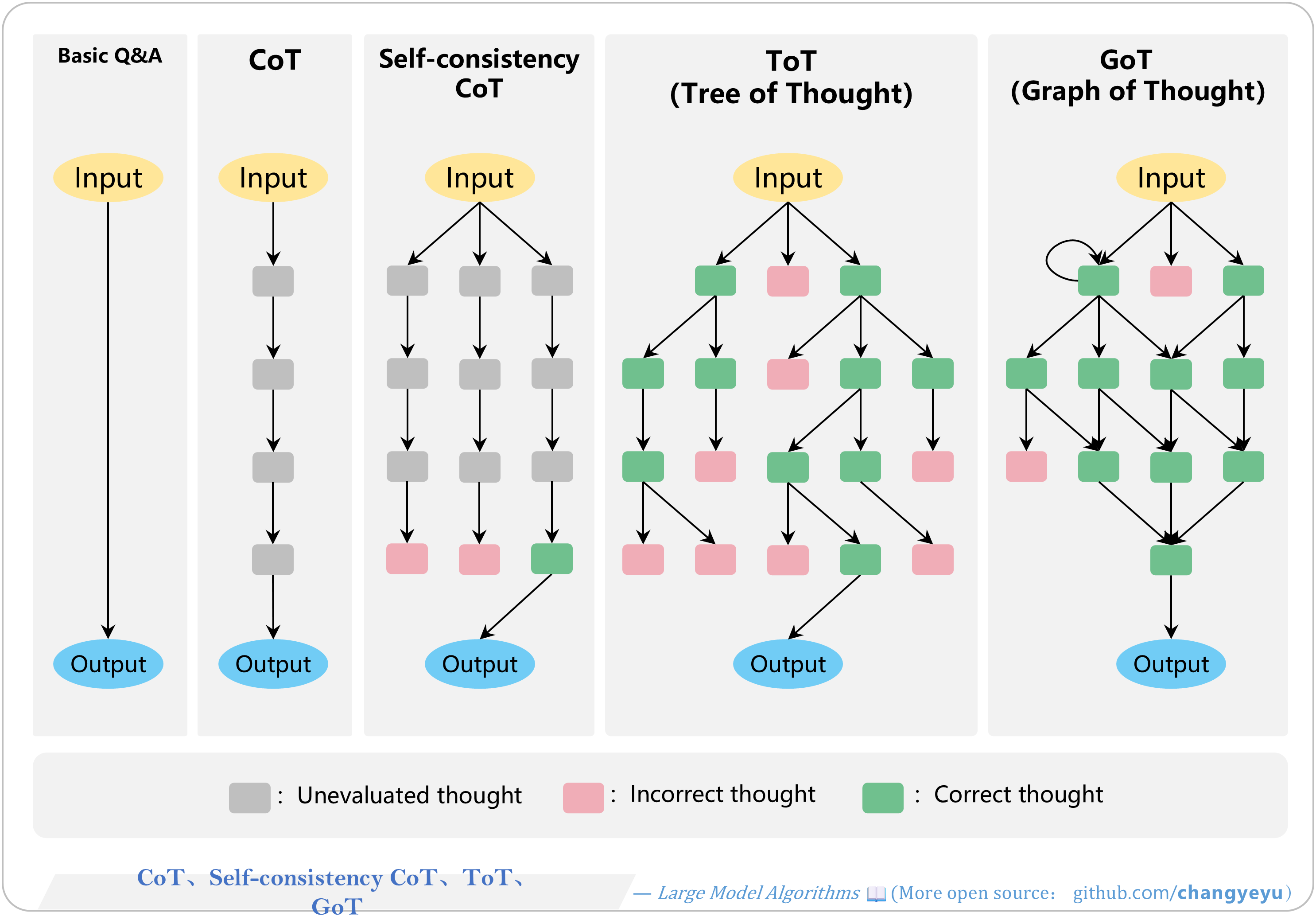
【Optimization without training】CoT、Self-consistency CoT、ToT、GoT [87]
- After CoT’s success, many variants emerged: ToT, GoT, Self-consistency CoT, Zero-shot-CoT, Auto-CoT, MoT, XoT, etc.
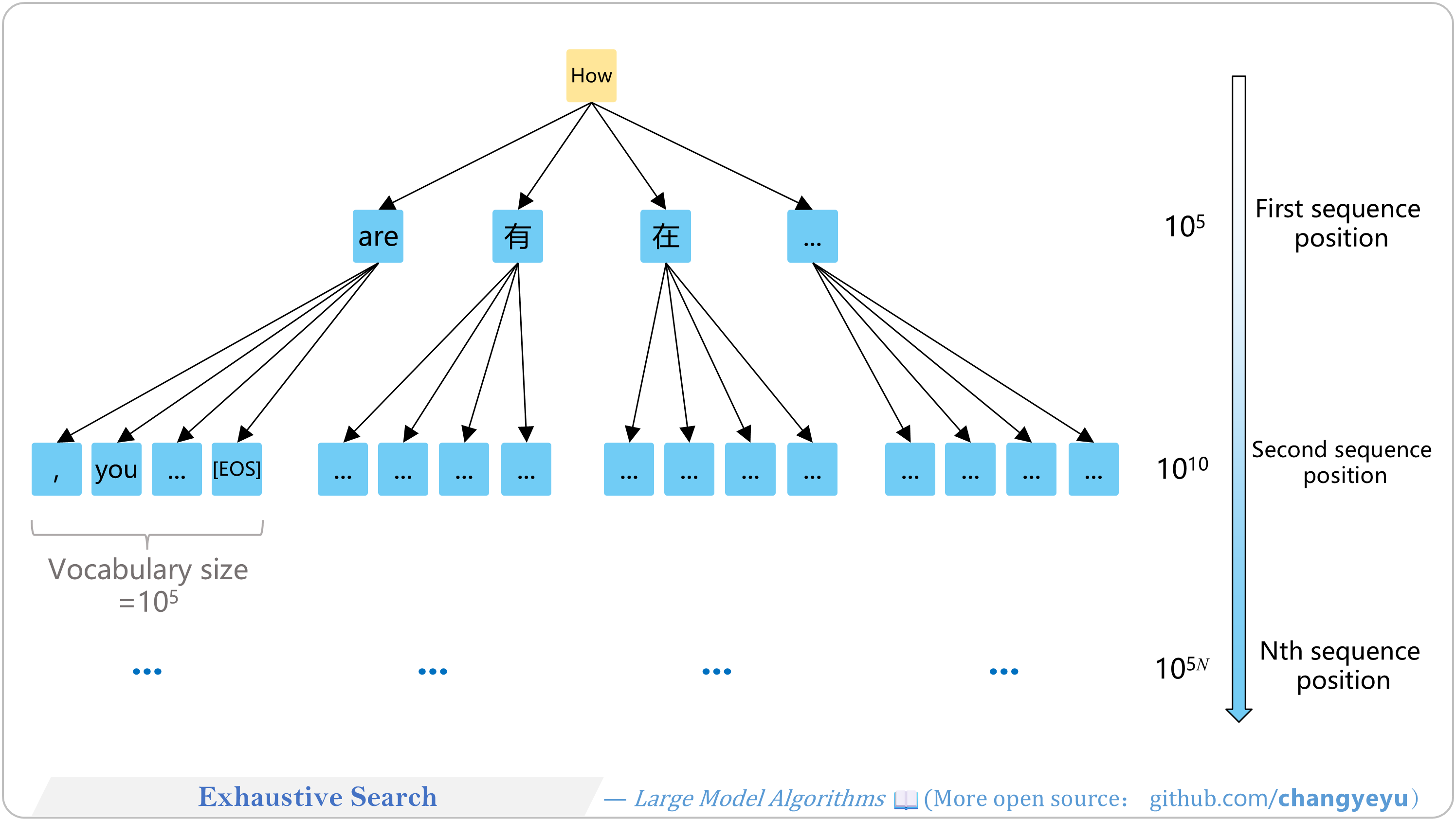
【Optimization without training】Exhaustive Search
- Token generation can be viewed as a V=10⁵-ary tree. Exhaustive Search finds the global optimum but is computationally prohibitive.

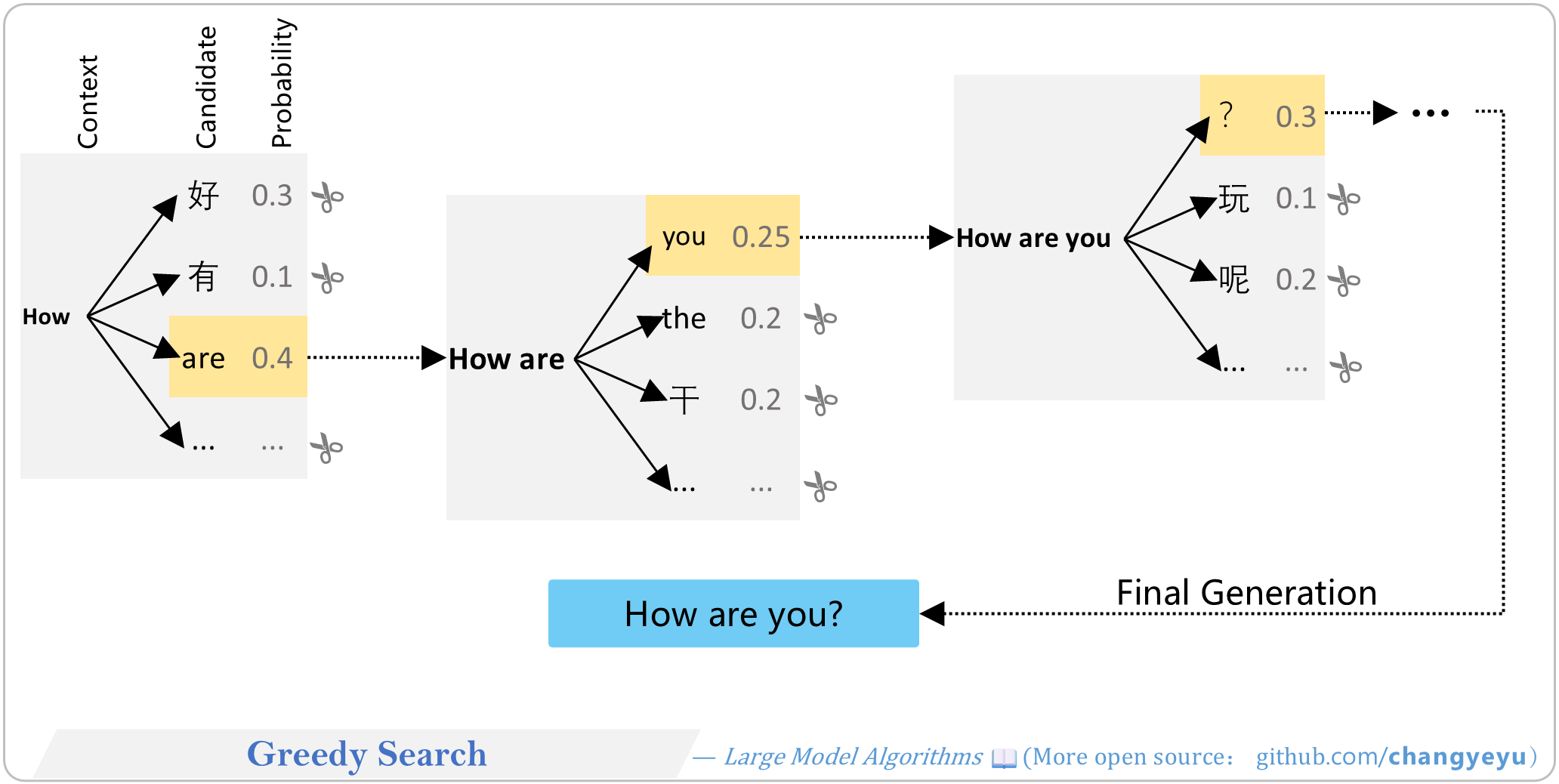
【Optimization without training】Greedy Search
- Greedy Search selects the current highest-probability token at each step, ignoring global optimality and diversity, leading to possible local optima and lack of diversity.
【Optimization without training】Beam Search
- Beam Search keeps multiple candidate sequences (“beams”) each step, pruning others. The final output is the highest-scoring beam. Larger beam count → closer to global optimum but higher cost.
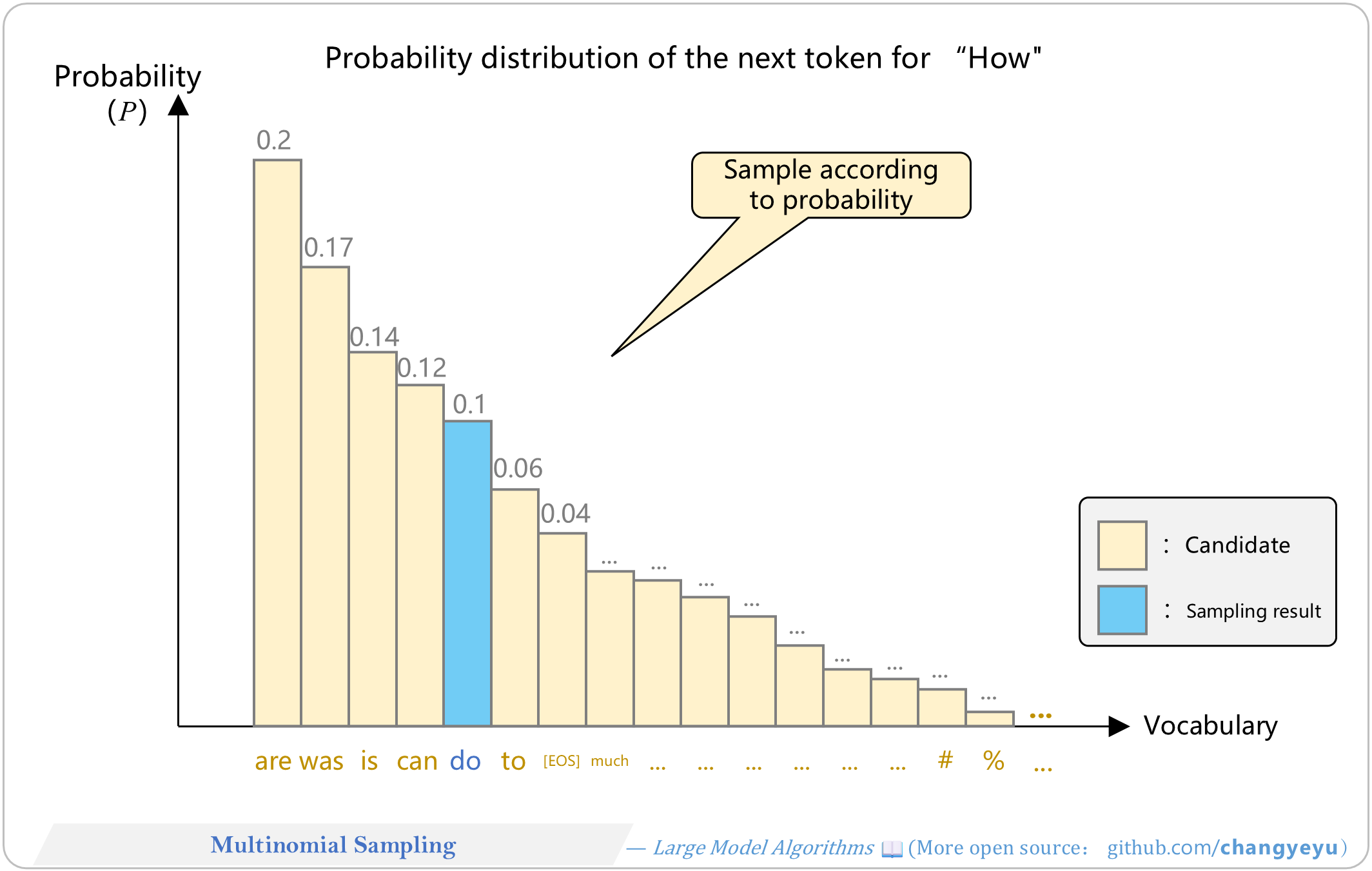
【Optimization without training】Multinomial Sampling
- Multinomial Sampling randomly draws tokens according to the model’s predicted distribution rather than uniform sampling. Includes Top-K, Top-P, etc.
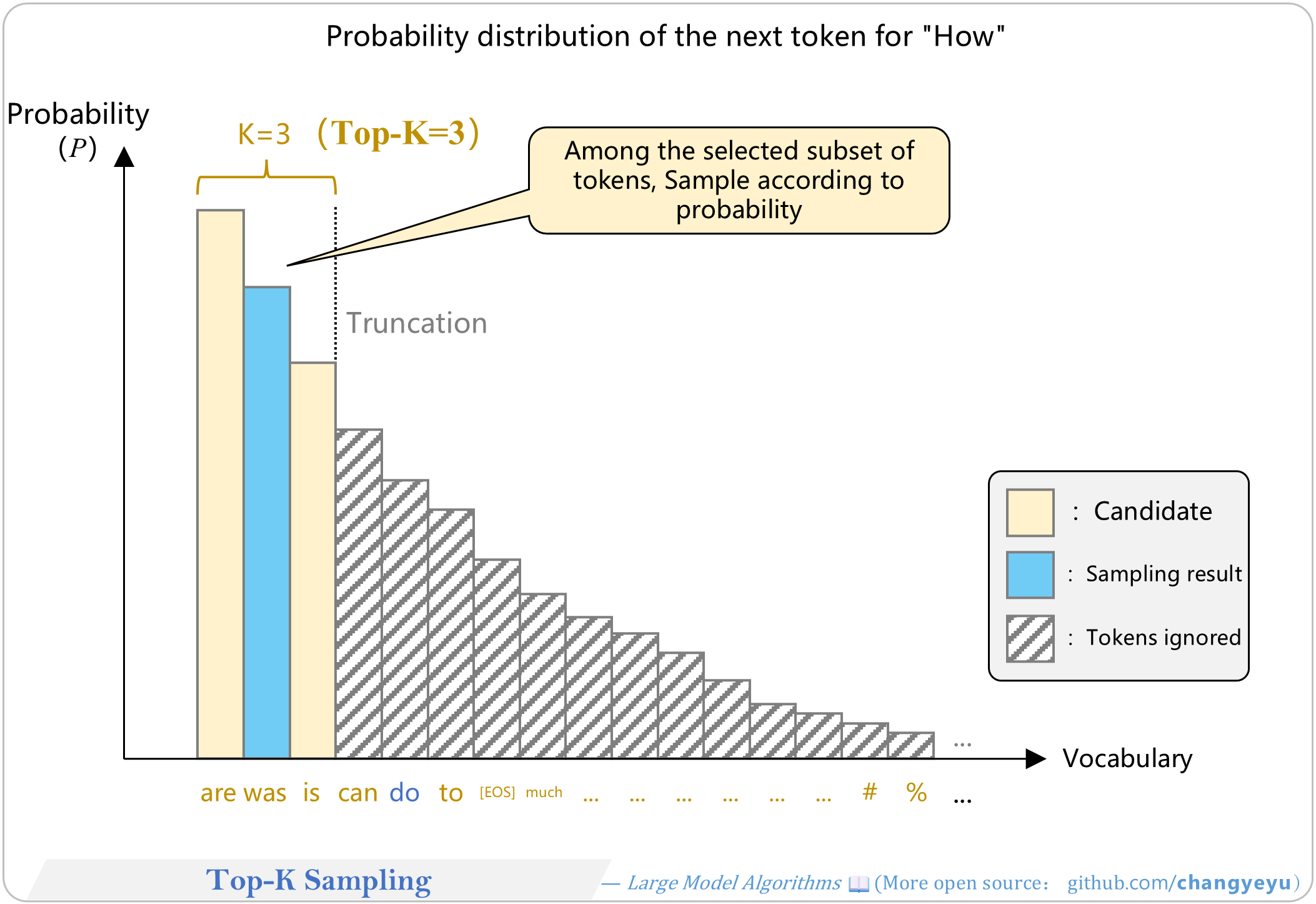
【Optimization without training】Top-K Sampling
- Top-K Sampling limits the candidate pool to the top K tokens by probability, then samples from them.

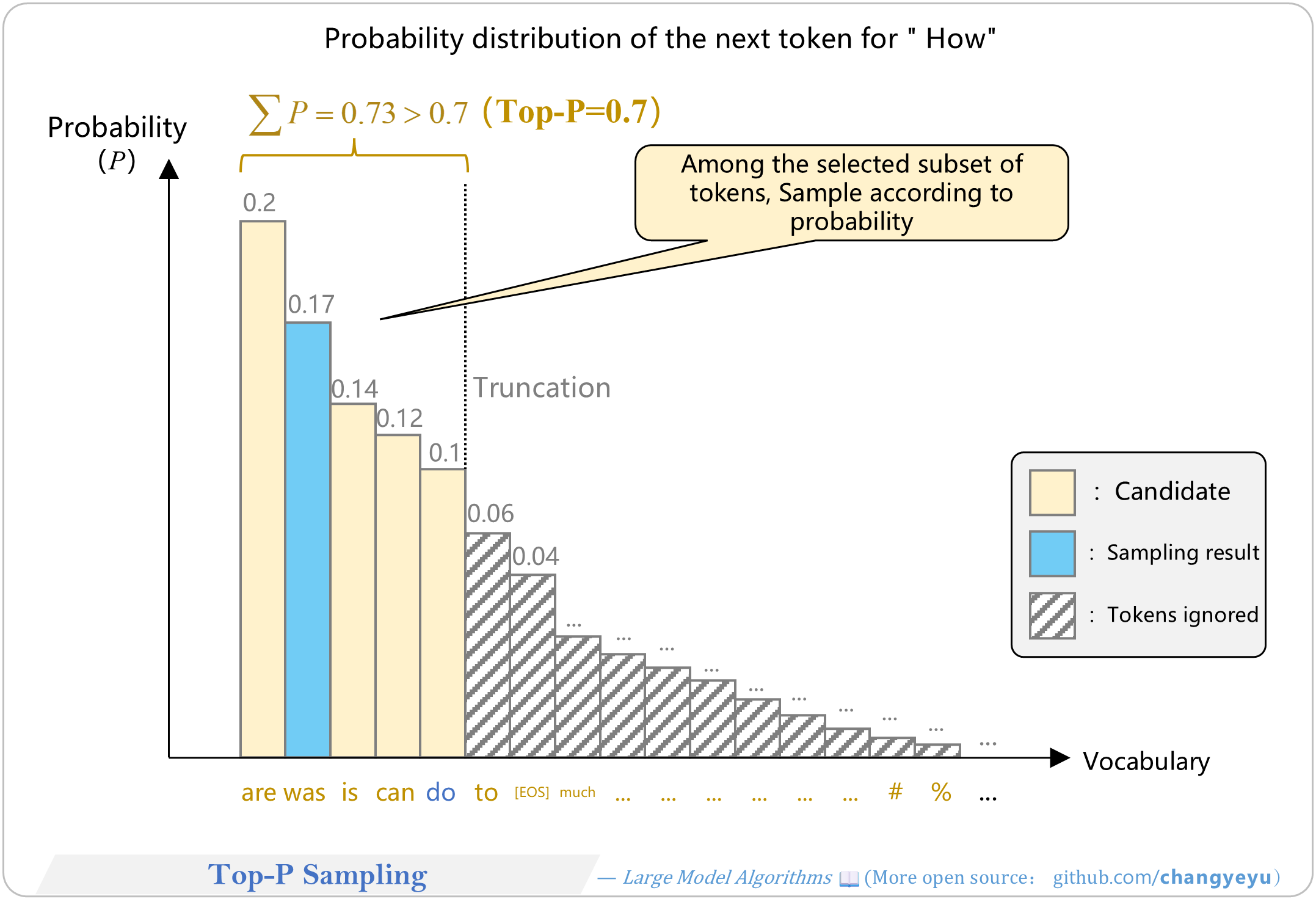
【Optimization without training】Top-P Sampling
- Top-P Sampling (Nucleus Sampling) dynamically selects the smallest set of tokens whose cumulative probability ≥ P, then samples from that set.

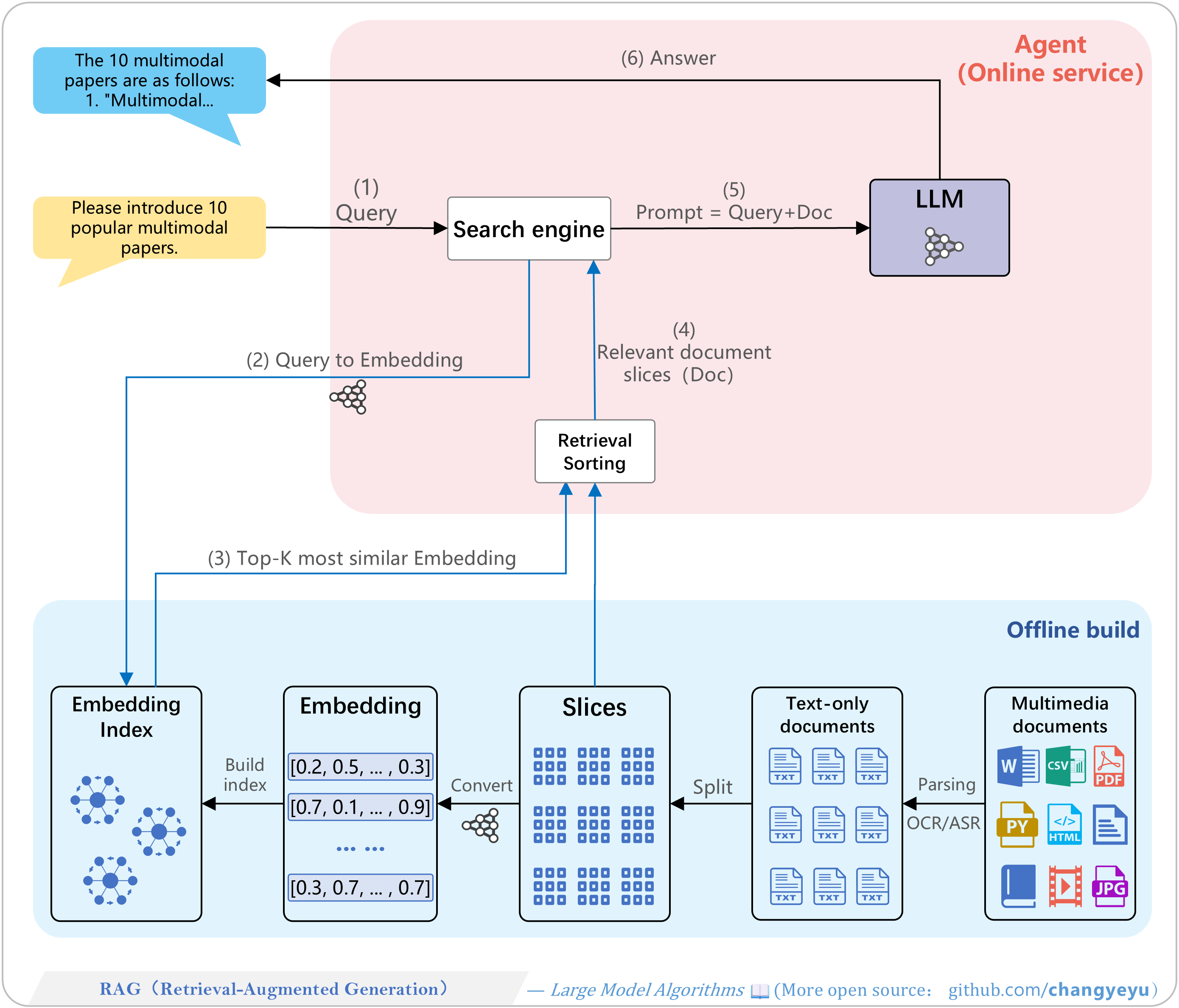
【Optimization without training】RAG(Retrieval-Augmented Generation)
- RAG integrates external knowledge via retrieval to enhance generative models. Proposed by Meta AI in 2020, it boosts performance on knowledge-intensive tasks. The workflow has offline index building and online serving components.
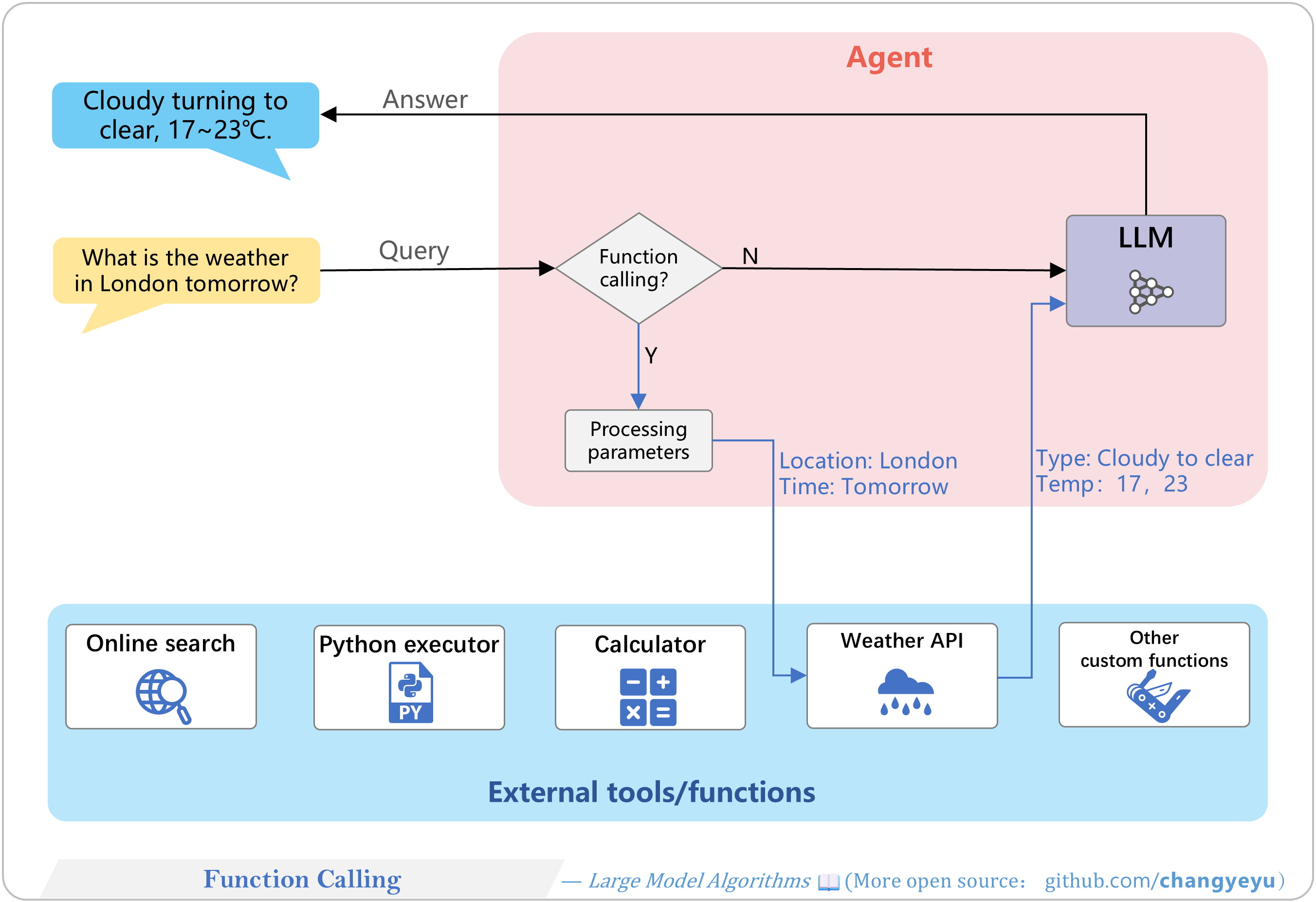
【Optimization without training】Function Calling
- Function Calling (Tool Use) lets an LLM agent invoke external APIs, database queries, local functions, or plugins. The agent parses user requests, handles parameters, calls tools, then feeds results back into the model.
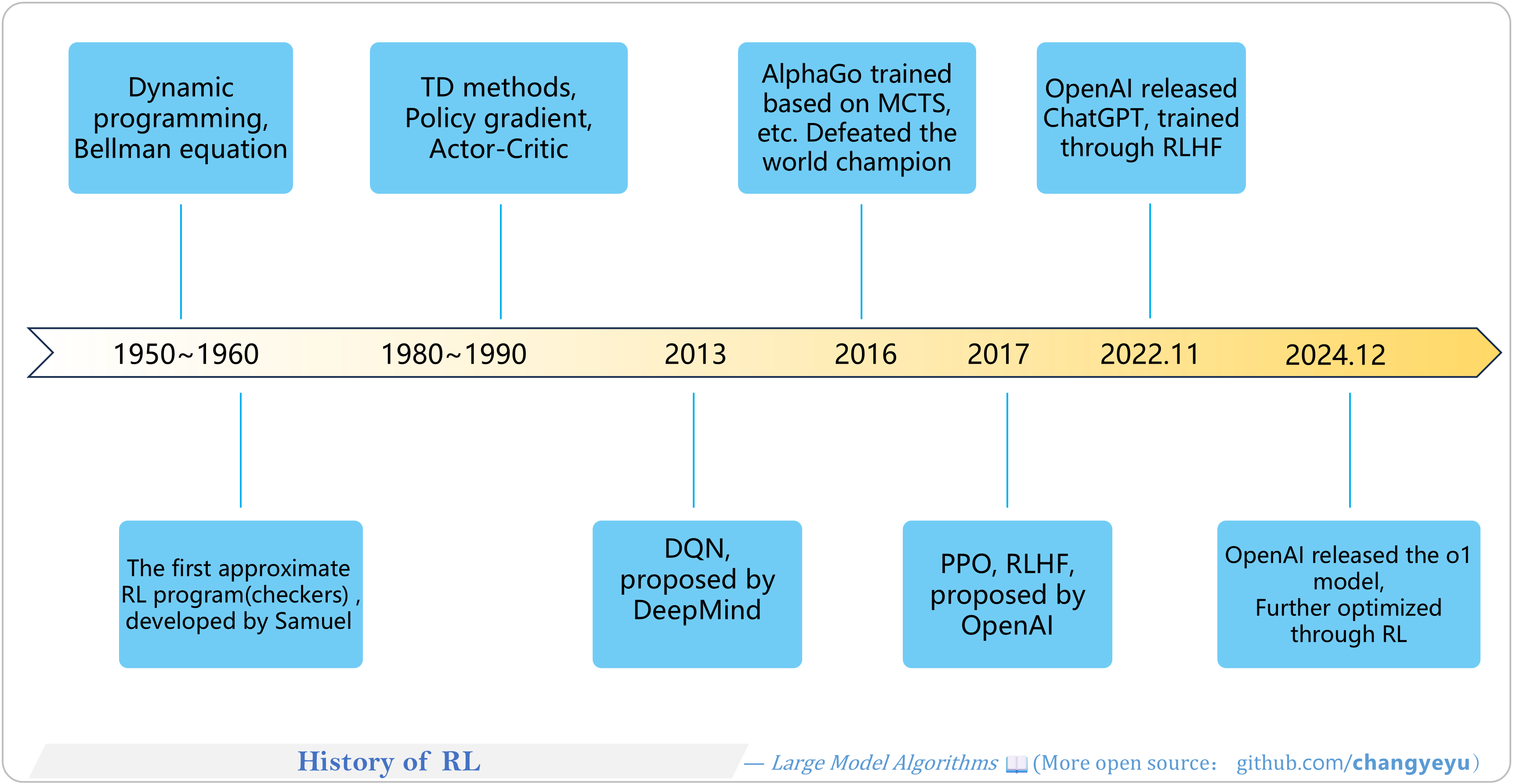
【RL basics】History of RL
- RL dates back to the 1950s, with key contributions by Richard S. Sutton and others.
- Since 2012, deep learning has spurred high-profile RL applications.
- In November 2022, ChatGPT (trained with RLHF) launched.
- In December 2024, OpenAI released the more deeply RL-optimized o1 model, driving industry interest in RL for large models.
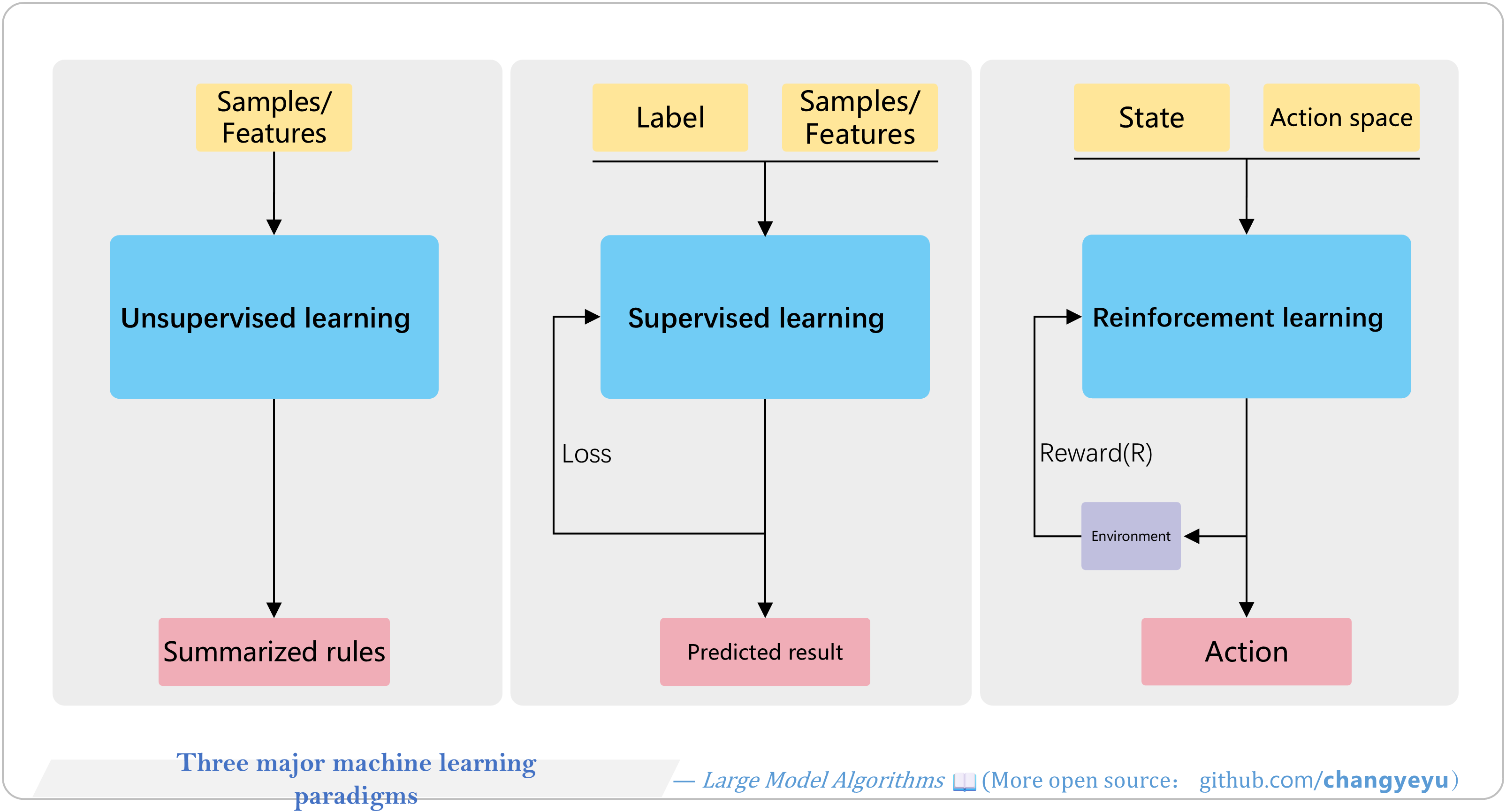
【RL basics】Three major machine learning paradigms
- The three paradigms are : Unsupervised Learning, Supervised Learning, and Reinforcement Learning.
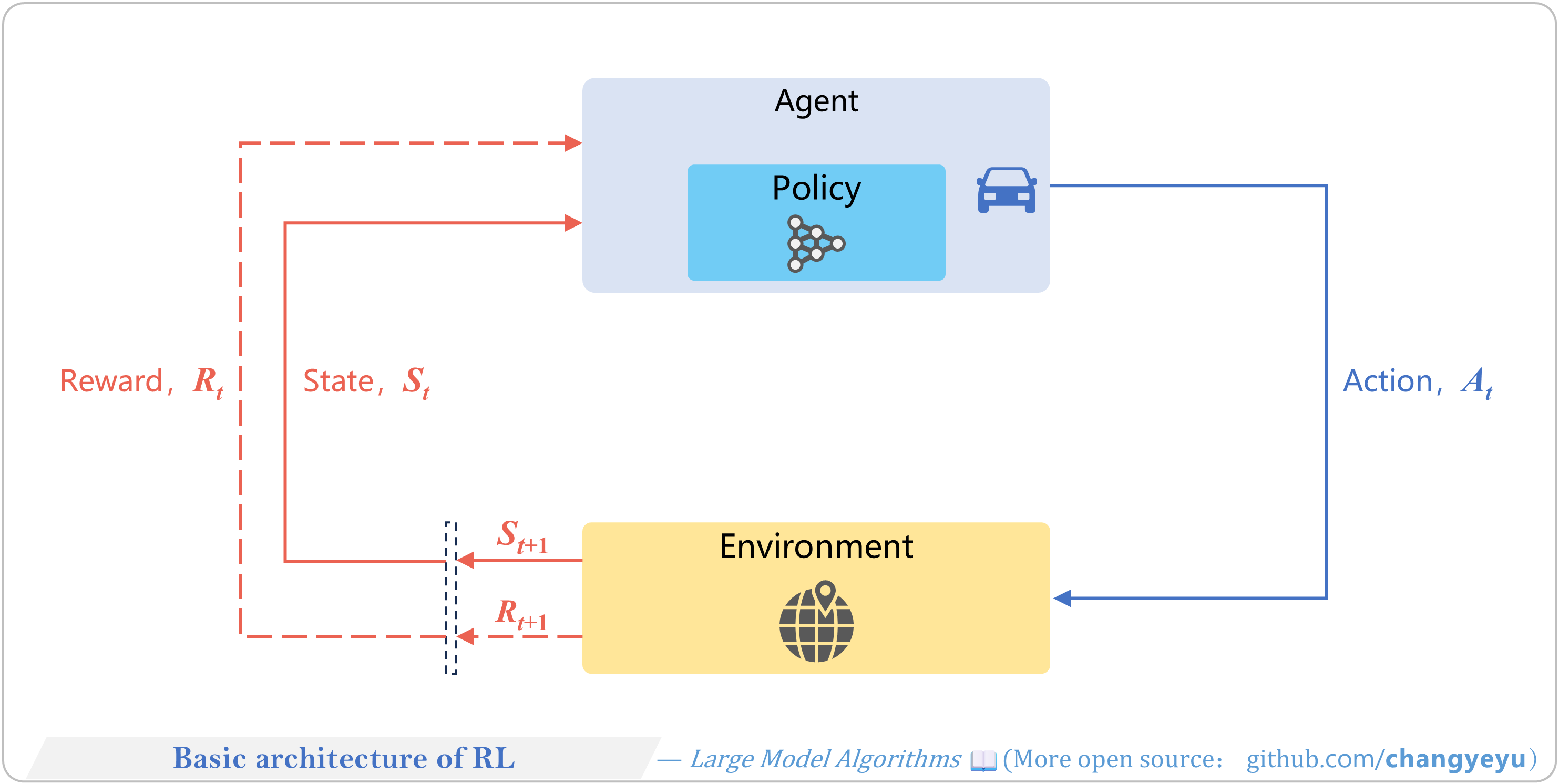
【RL basics】Basic architecture of RL
- RL involves two core roles: the Agent and the Environment.
- The Agent perceives state, selects actions via its policy.
- The Environment updates state and returns rewards.

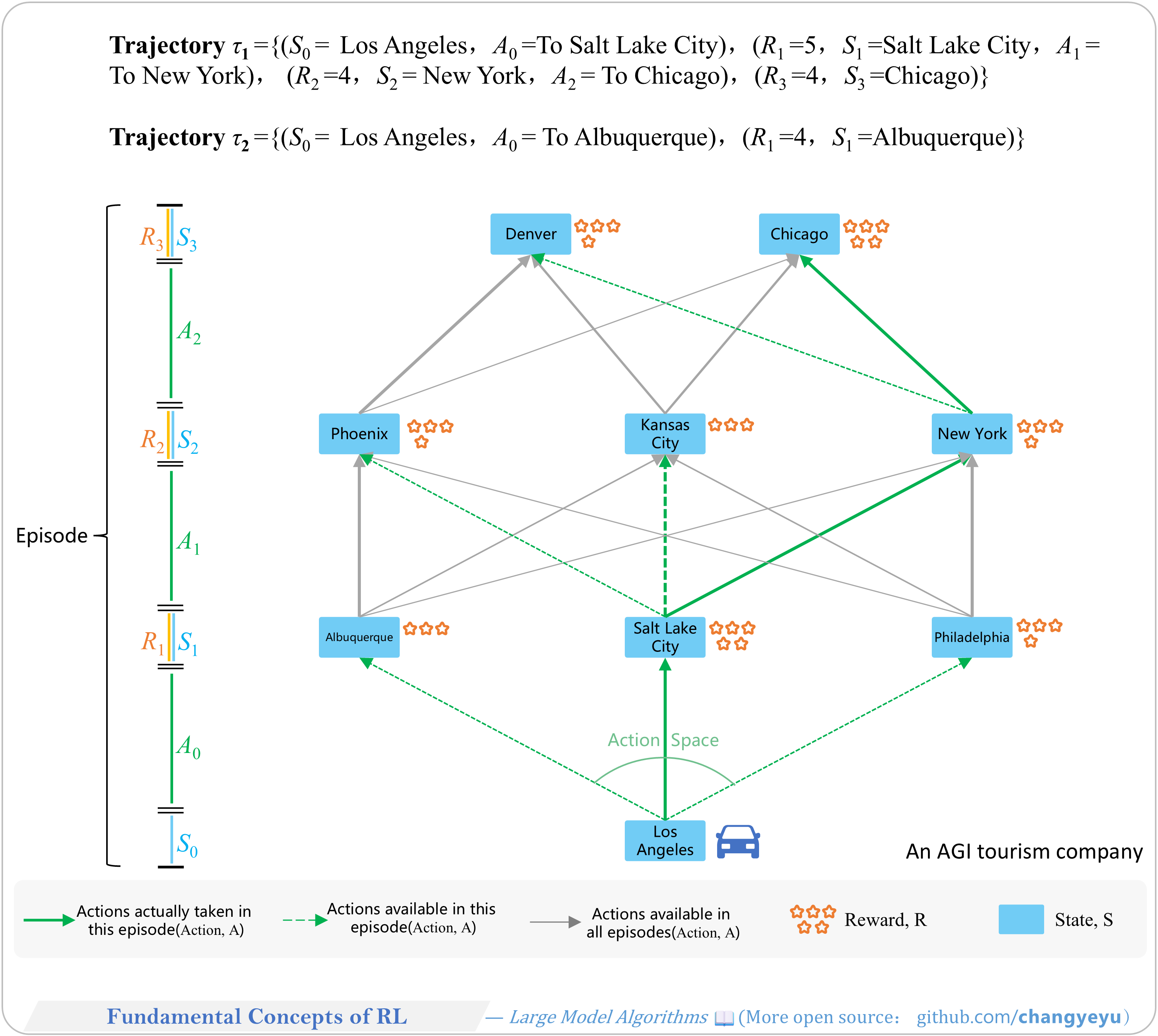
【RL basics】Fundamental Concepts of RL
- Example: an AGI travel company uses self-driving cars. The Agent learns optimal routes via iterative trips and accumulated passenger ratings (rewards), optimizing the travel experience.
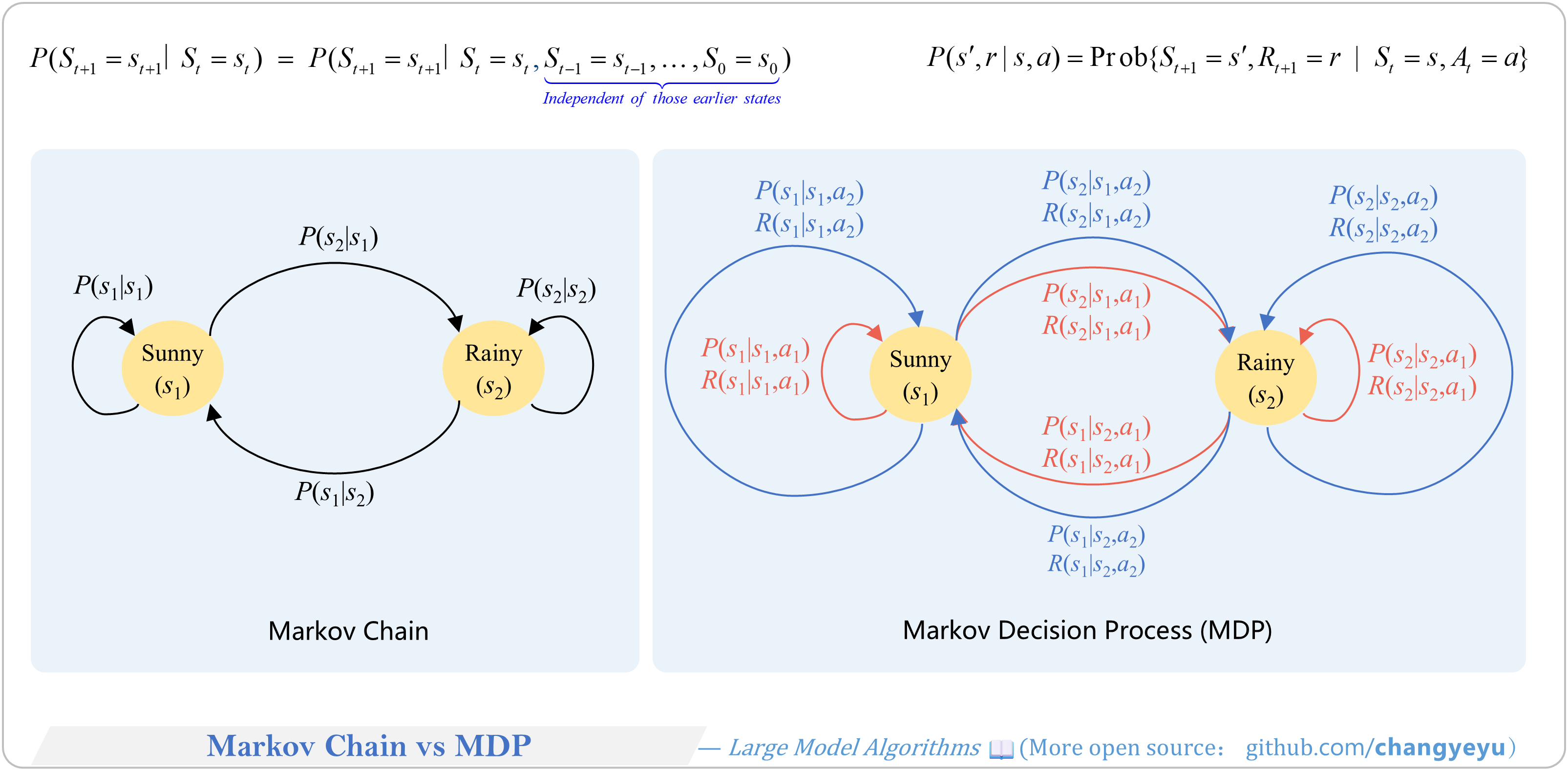
【RL basics】Markov Chain vs MDP
- Markov Chains are extended to Markov Decision Processes by adding Actions (A) and Rewards (R).
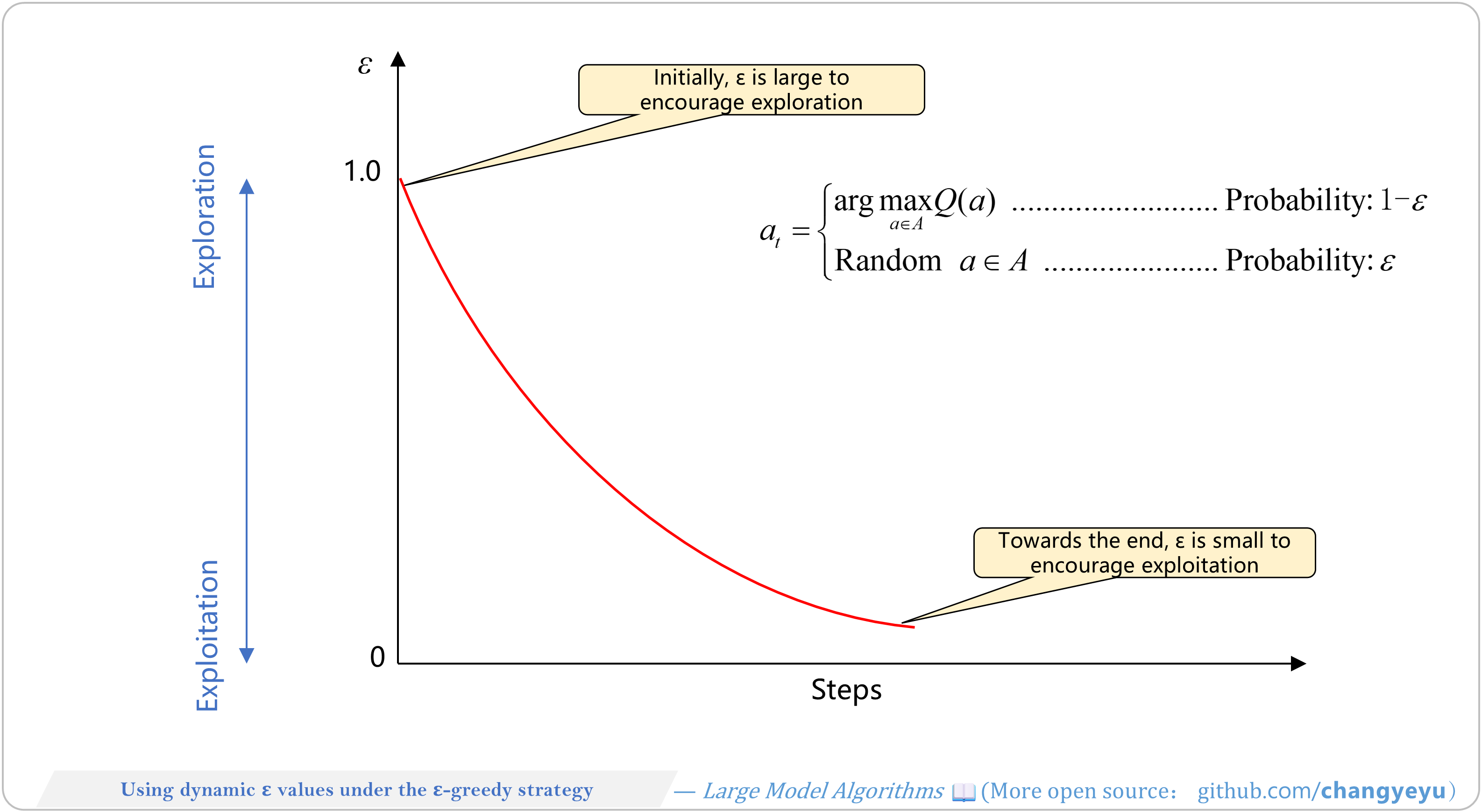
【RL basics】Using dynamic ε values under the ε-greedy strategy
- Epsilon-Greedy uses ε to balance exploration/exploitation. Start with high ε to explore, then decay ε to exploit learned knowledge, improving training efficiency and final policy.
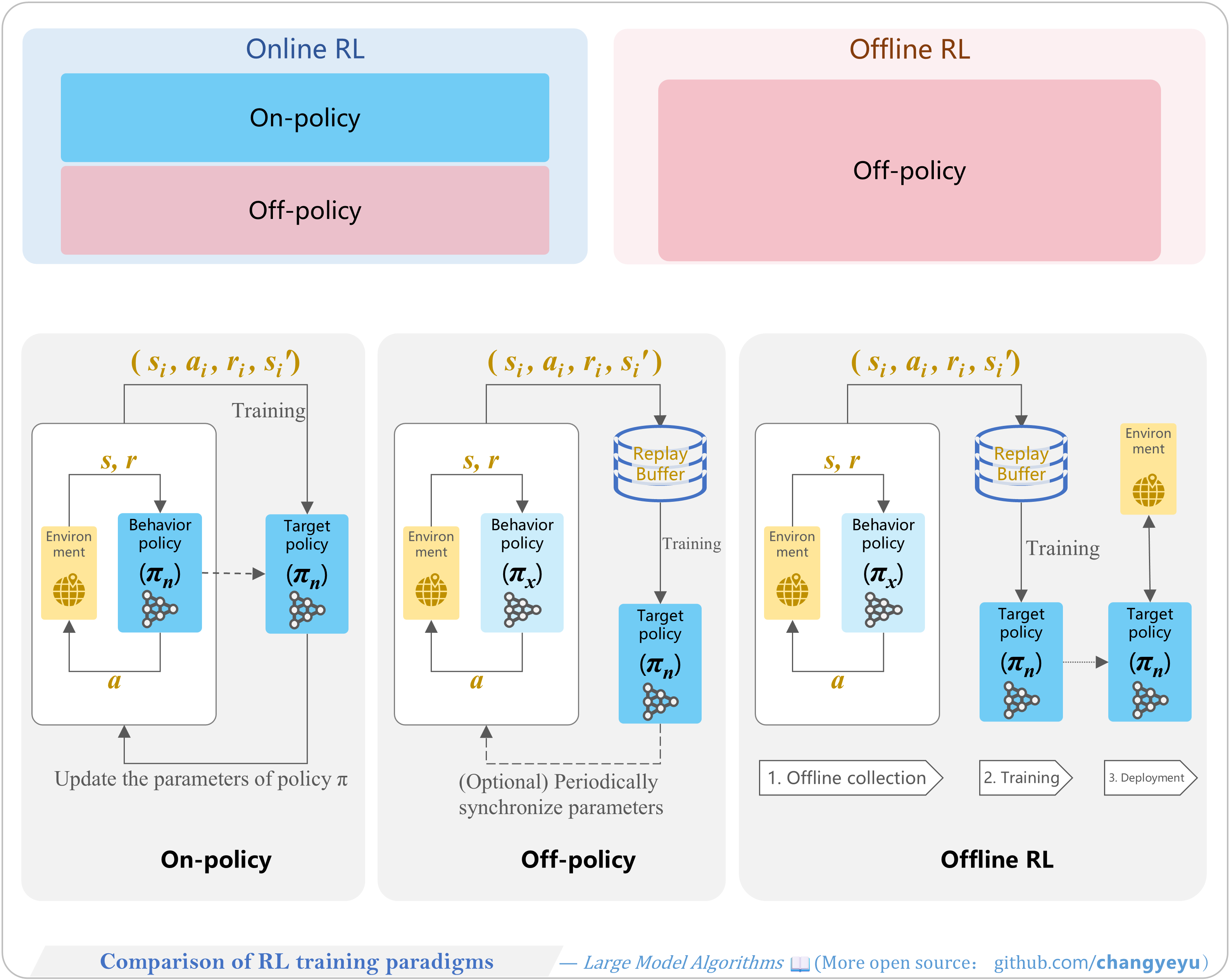
【RL basics】Comparison of RL training paradigms
- On-policy vs. Off-policy vs. Online RL vs. Offline RL.
- On-policy: behavior and target policies are the same (e.g., SARSA).
- Off-policy: behavior and target differ (e.g., Q-learning, DQN).
- Online RL: continuous environment interaction and data collection.
- Offline RL: training solely on a fixed dataset without environment interaction.

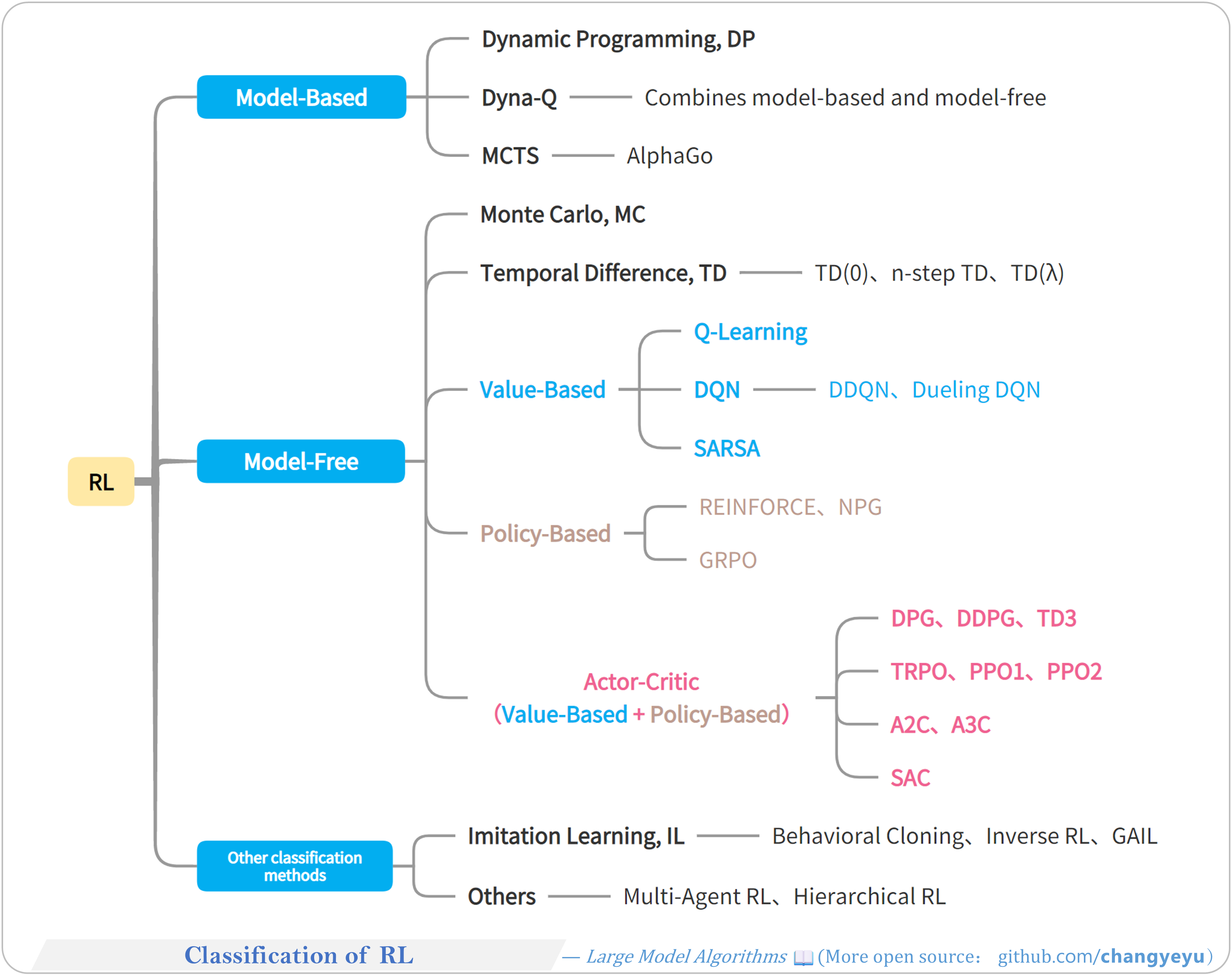
【RL basics】Classification of RL
- RL algorithms are categorized by various dimensions and often combined with SL, CL, IL, GANs, etc., spawning many hybrid methods.

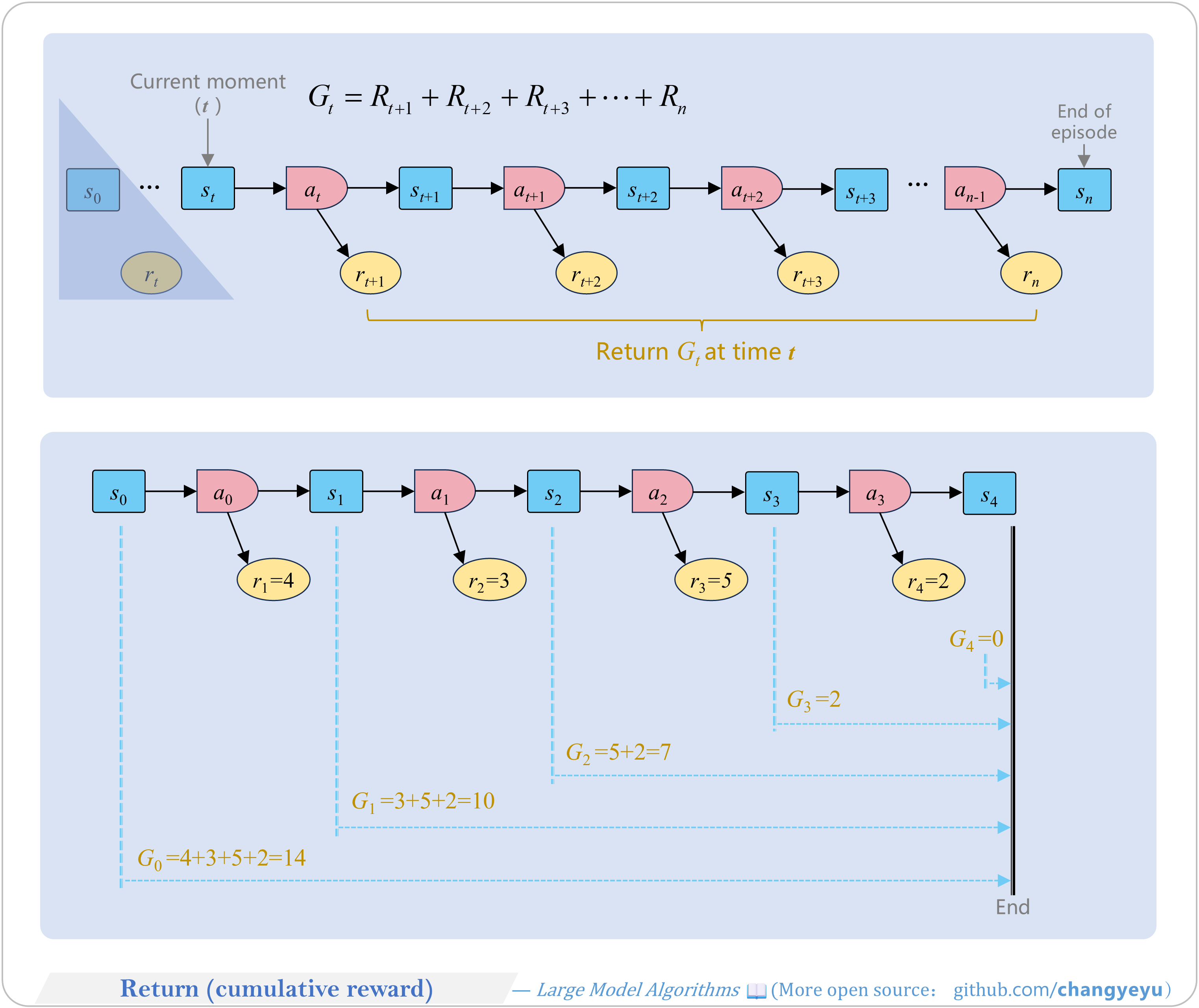
【RL basics】Return(cumulative reward)
- Return (G) is the sum of future rewards from a time step, measuring the total expected reward under a policy.
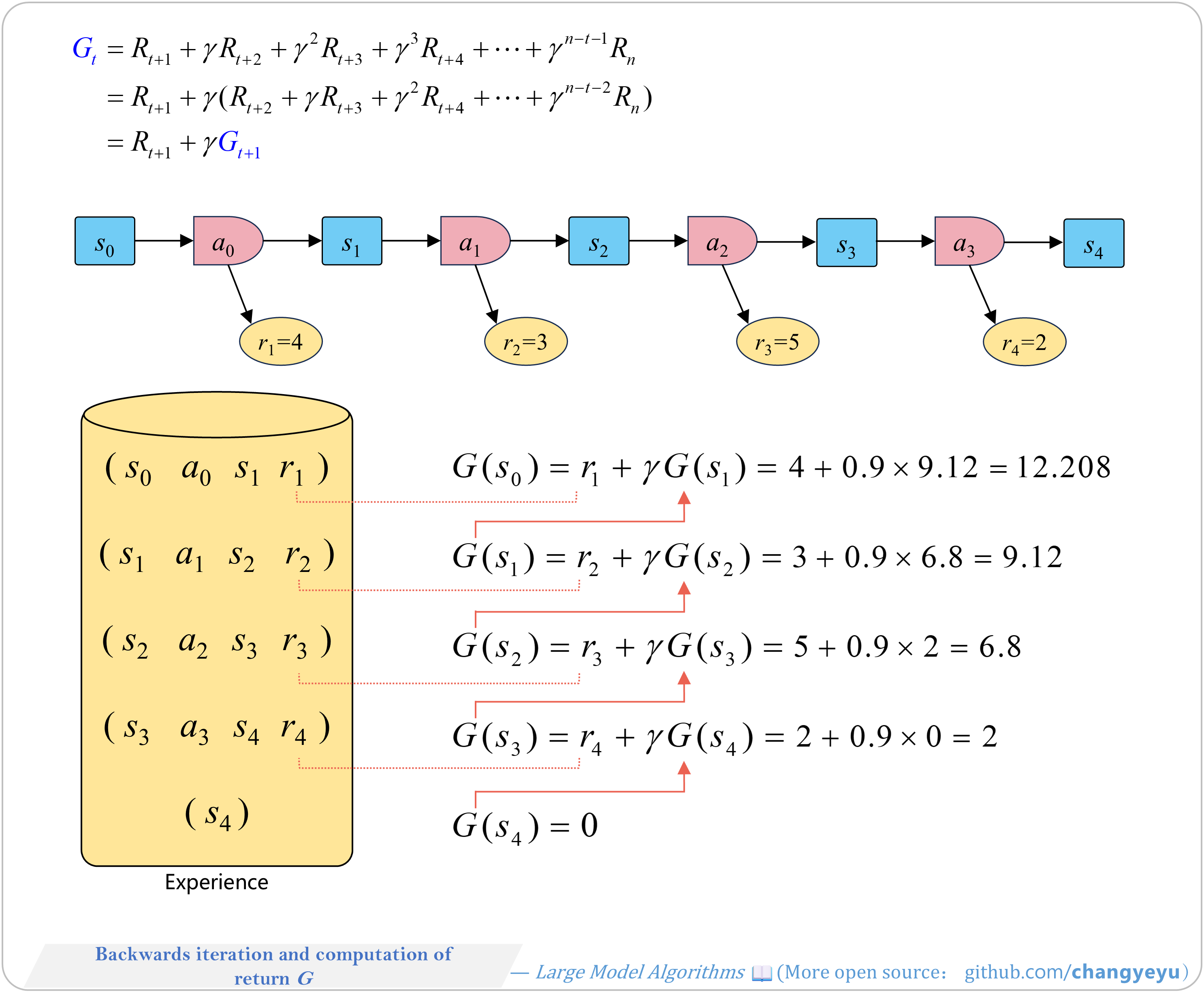
【RL basics】Backwards iteration and computation of return G
- Using discount factor γ, compute returns backwards from the end of an episode.
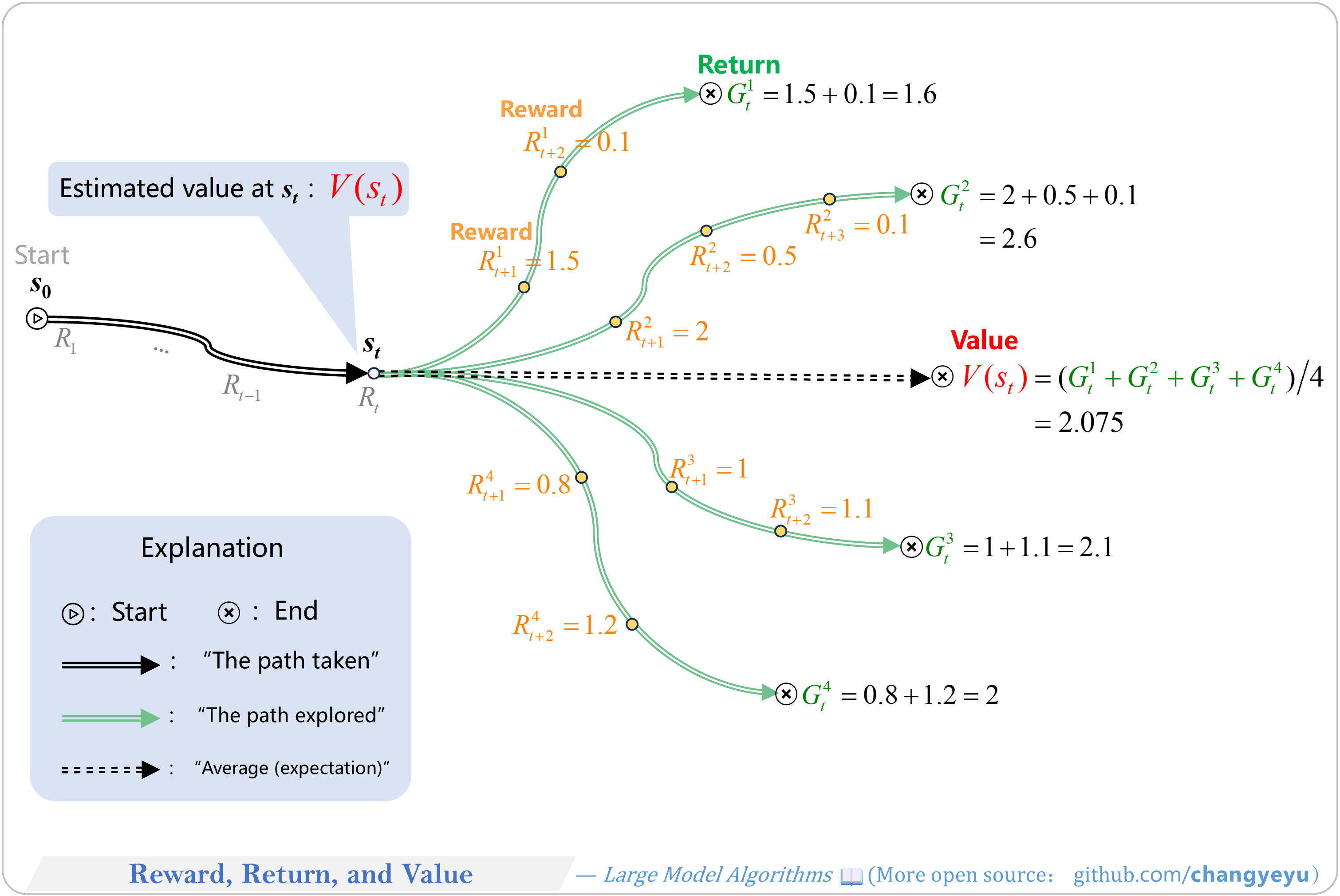
【RL basics】Reward, Return, and Value
- Reward: immediate, local gain.
- Return: total future gain.
- Value: expected return over all trajectories, weighted by their probability (assuming γ=1 in this illustration).

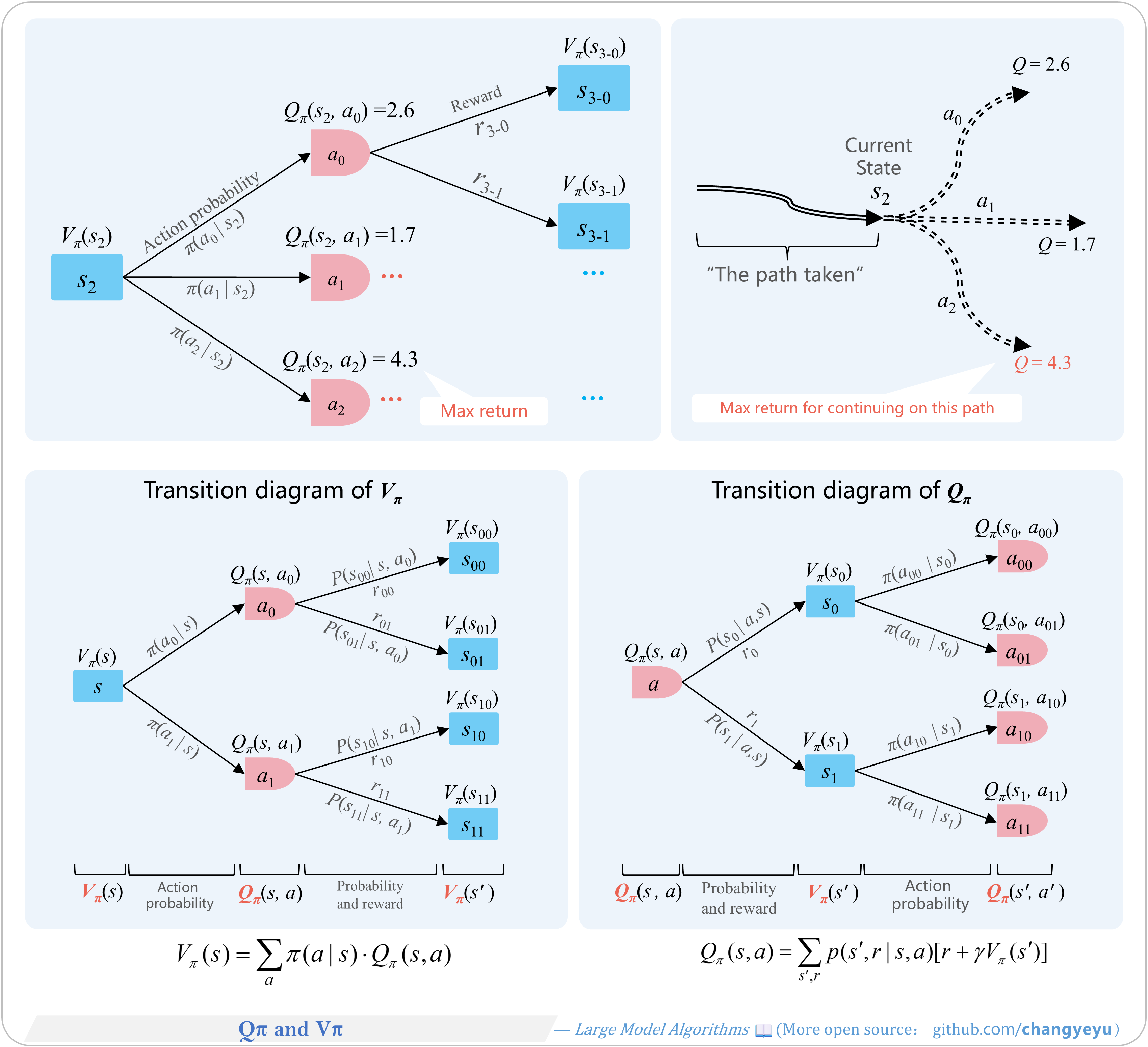
【RL basics】Qπ and Vπ
- Action-Value Function Qπ(s,a): expected return after taking action a in state s under policy π.
- State-Value Function Vπ(s): expected return from state s under π.

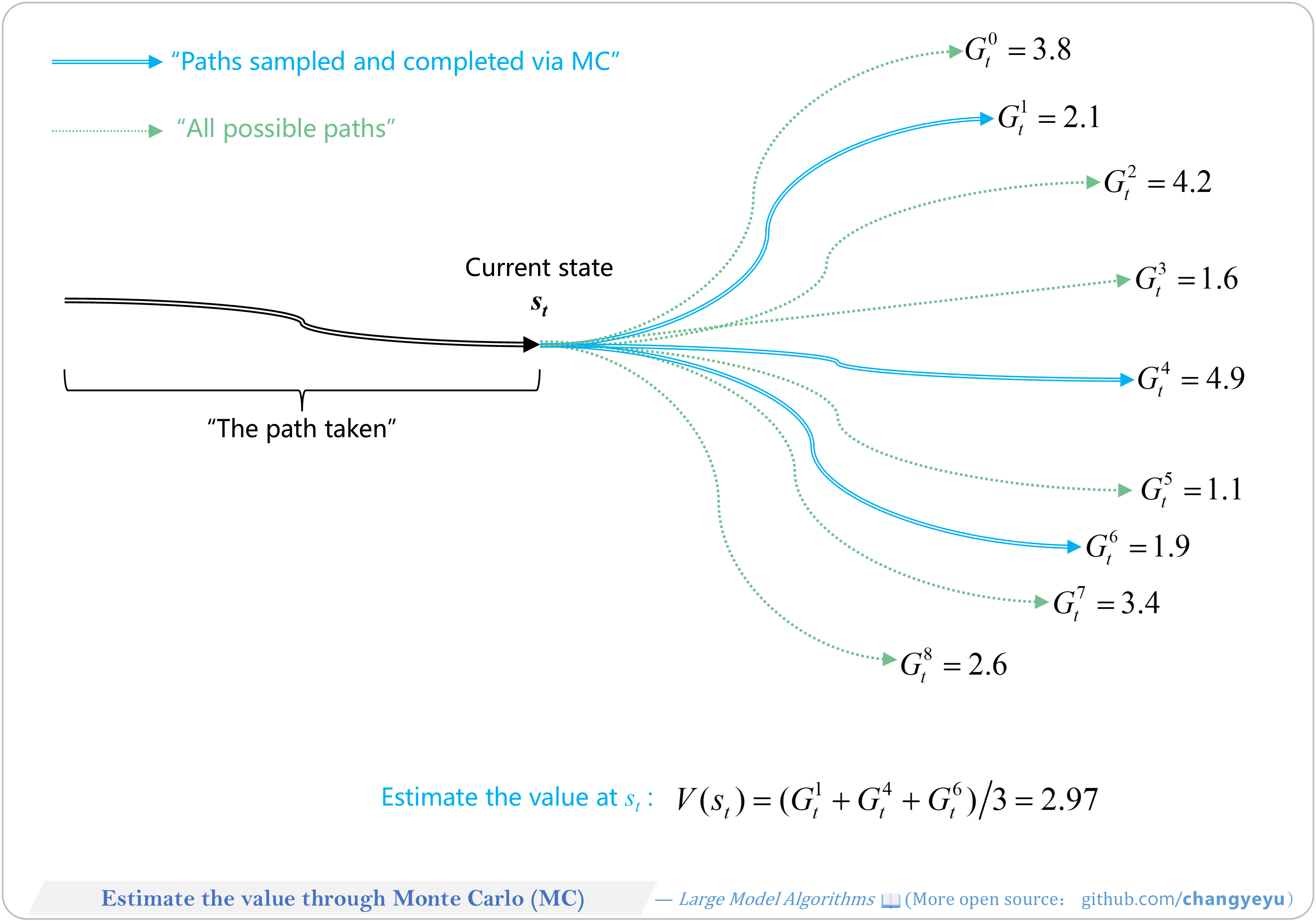
【RL basics】Estimate the value through Monte Carlo(MC)
- Monte Carlo methods estimate value functions by sampling complete episodes, suitable when the environment model is unknown.
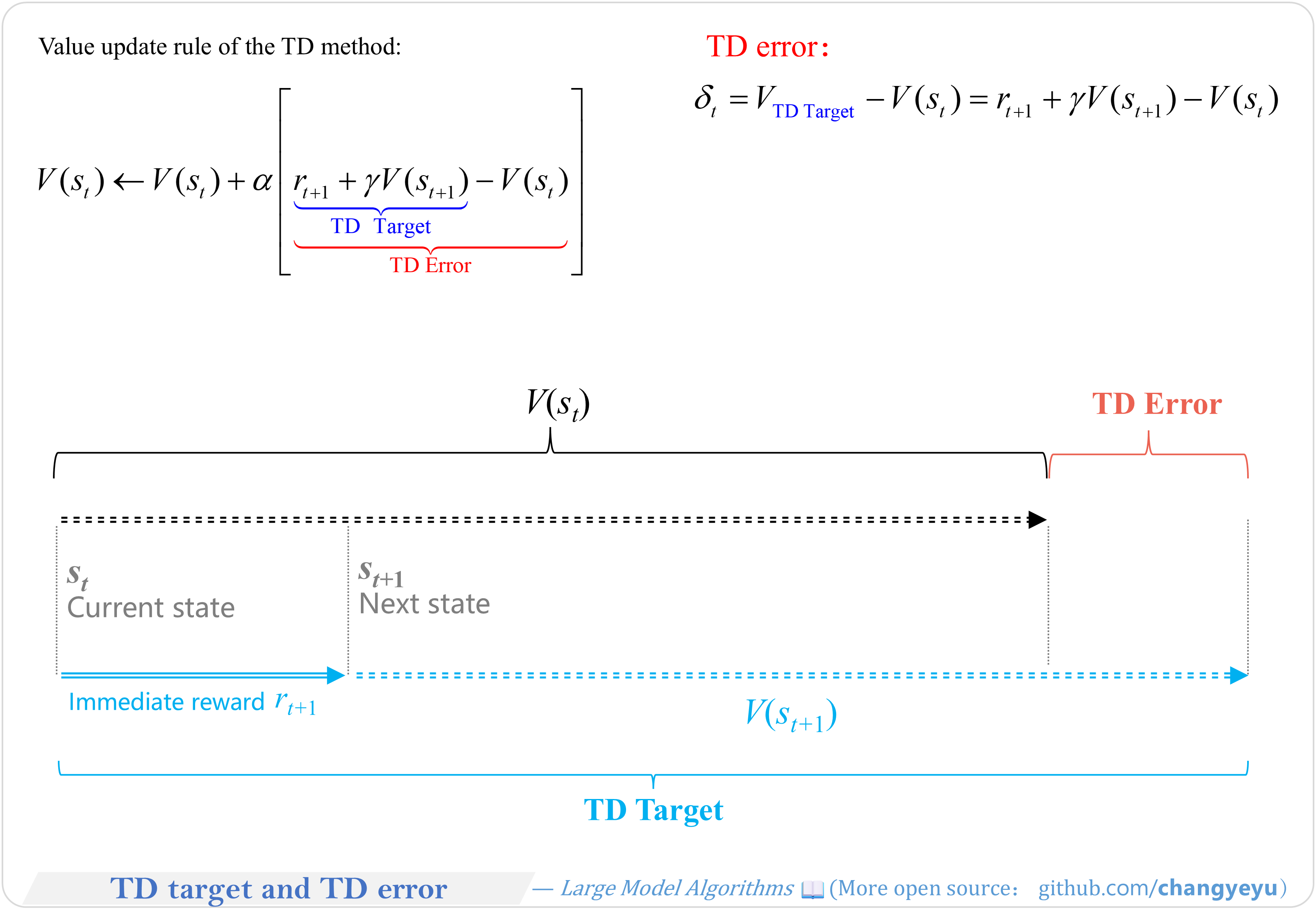
【RL basics】TD target and TD error
- TD Target uses the next reward and next state value; TD Error measures the difference between current value estimate and TD target, guiding updates.
【RL basics】TD(0), n-step TD, and MC
- When n=1, multi-step TD reduces to TD(0); as n→∞, it approaches Monte Carlo.

【RL basics】Characteristics of MC and TD methods
- MC: low bias, high variance; TD: high bias, low variance.

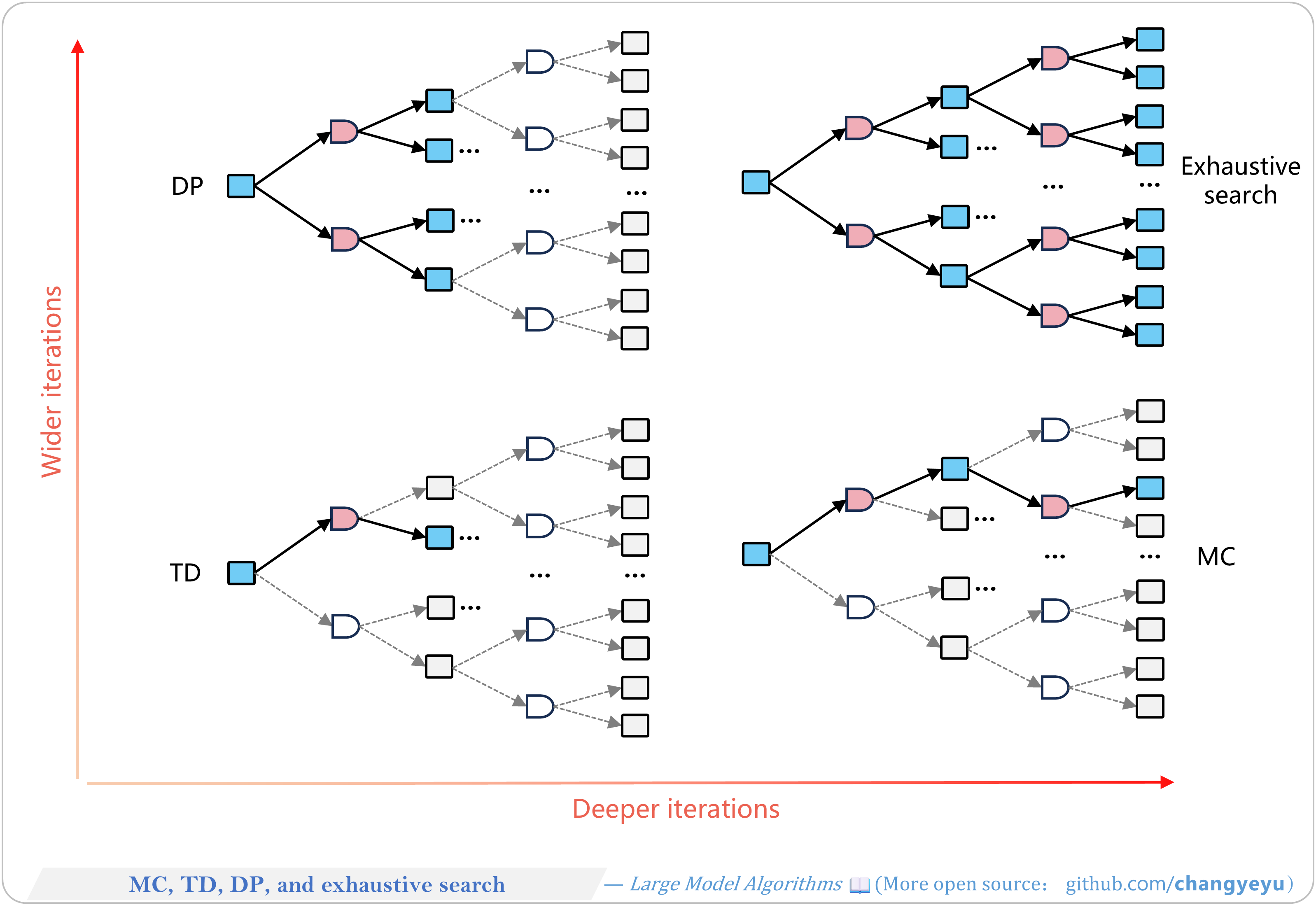
【RL basics】MC, TD, DP, and exhaustive search [32]
- Four approaches to value estimation and policy optimization: Monte Carlo, Temporal Difference, Dynamic Programming, and Brute-Force Search.
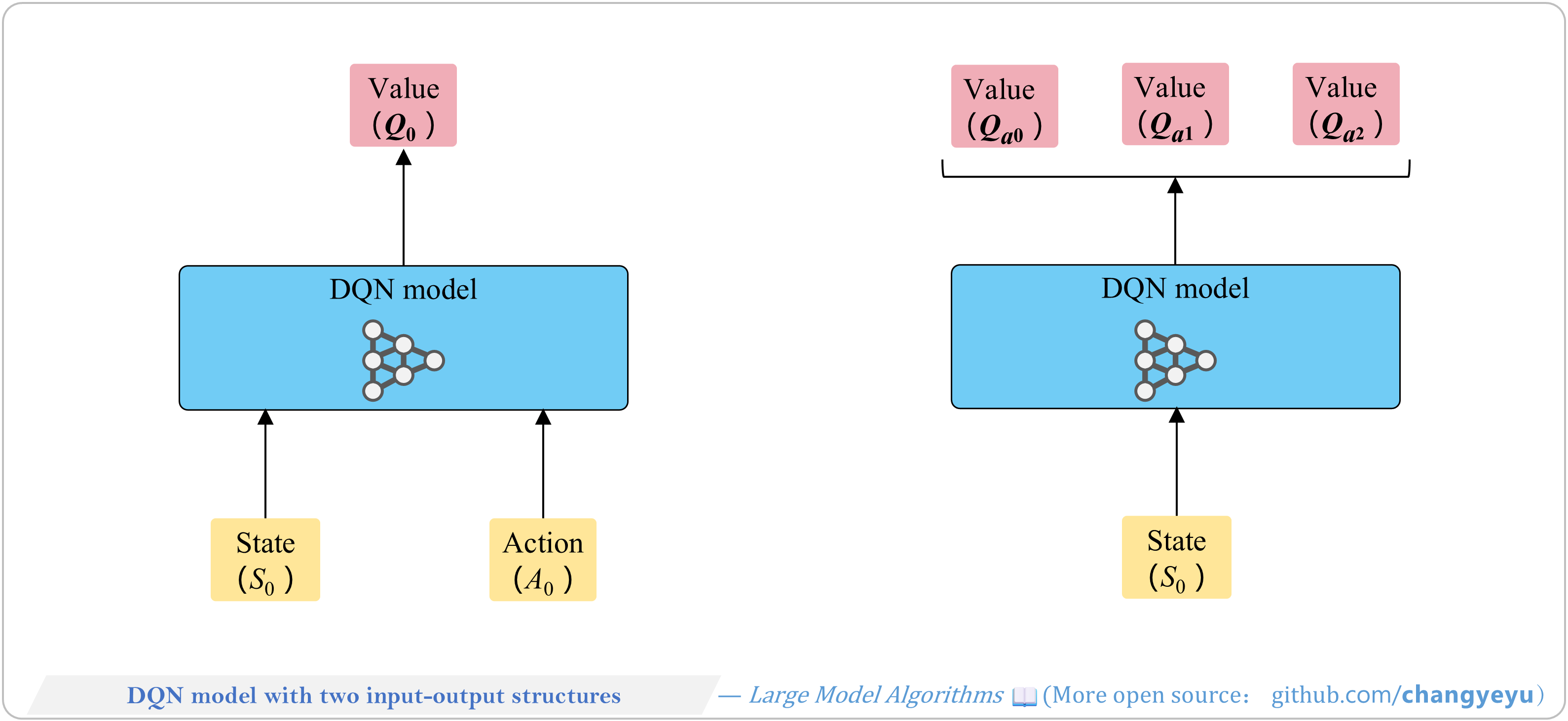
【RL basics】DQN model with two input-output structures
DQN has two IO variants:
- Input: state and a candidate action → output: its Q-value (batch compute for multiple actions possible).
- Input: state → output: Q-values for all actions; choose the max.
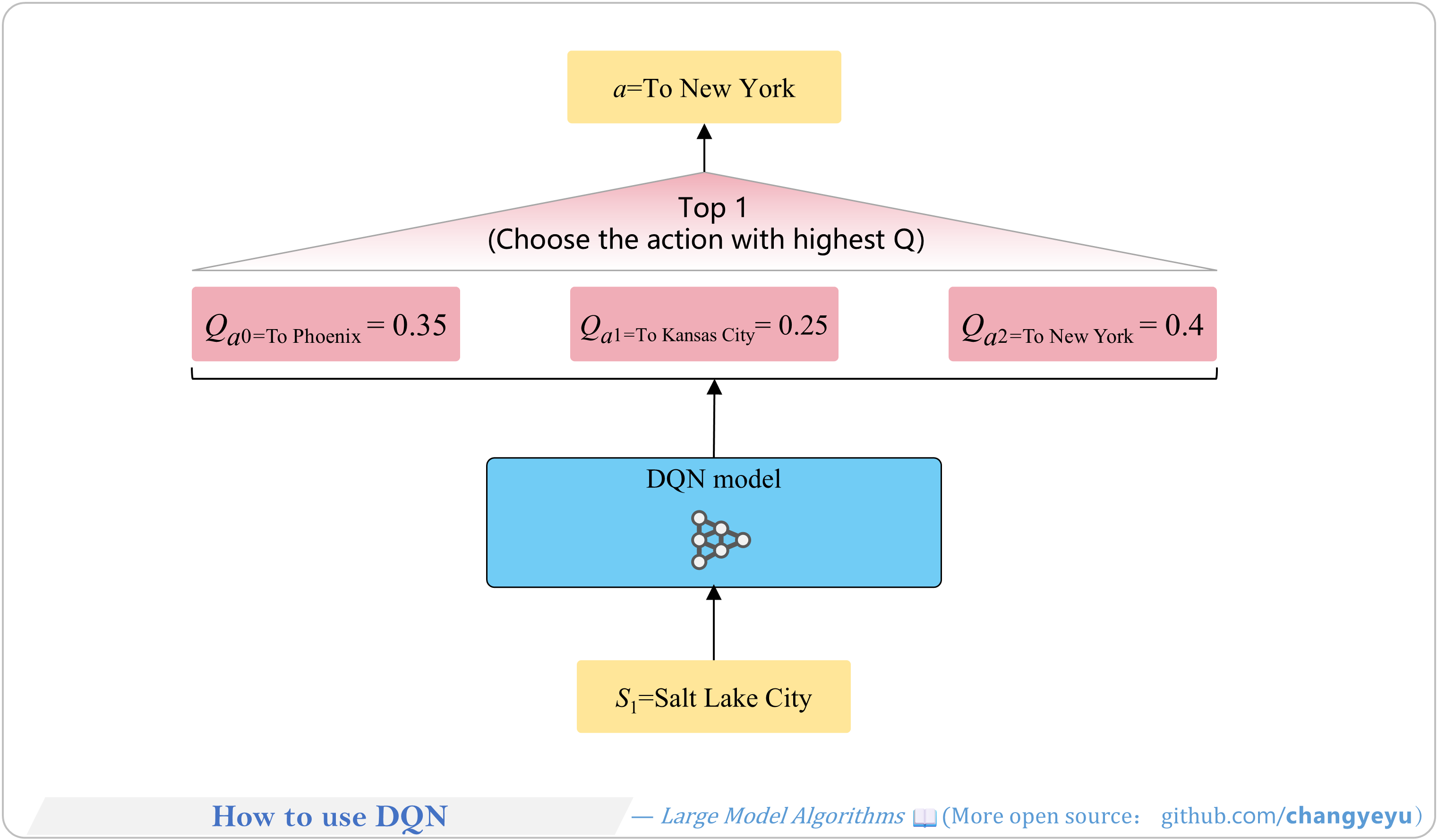
【RL basics】How to use DQN
- After training, deploy DQN online to aid decisions. At inference, pick the action with the highest Q-value as determined by the model.
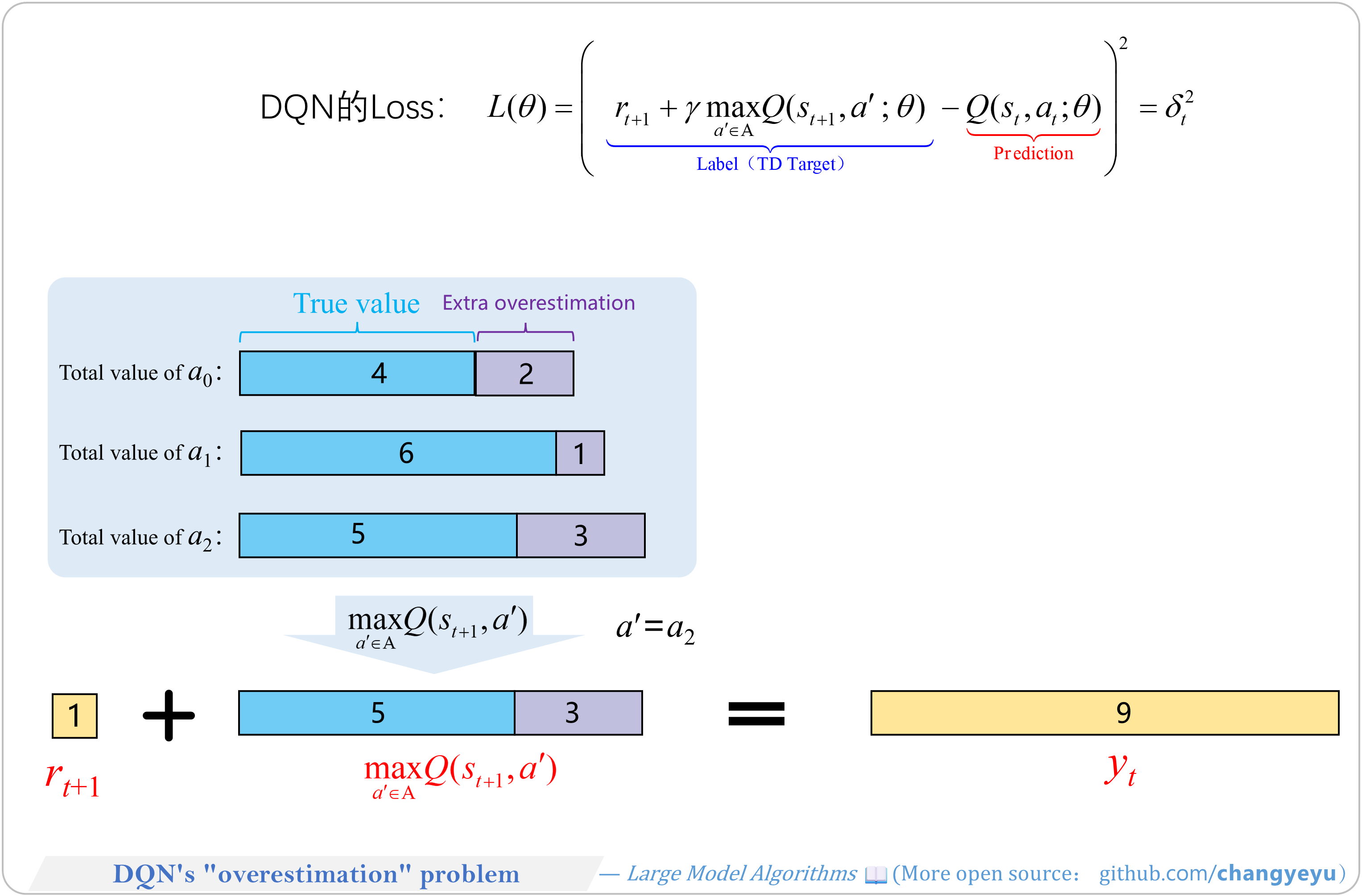
【RL basics】DQN's overestimation problem
- Two core issues of DQN:
- (1) Overestimation of Q-values due to max operations accumulating error unevenly across actions.
- (2) Bootstrapping (“dog chases its tail”) where the target depends on the same network weights, causing training instability and convergence difficulties.
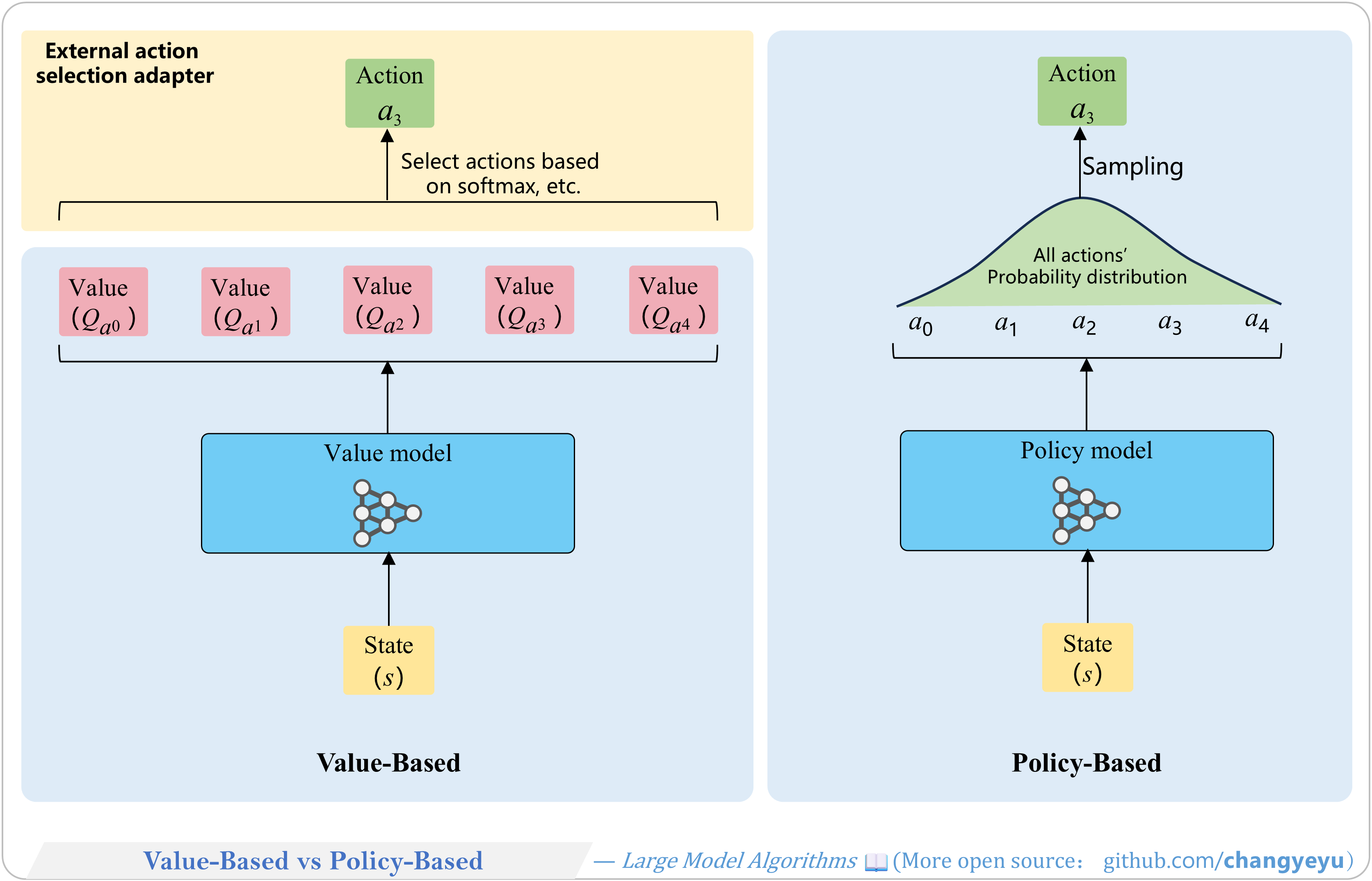
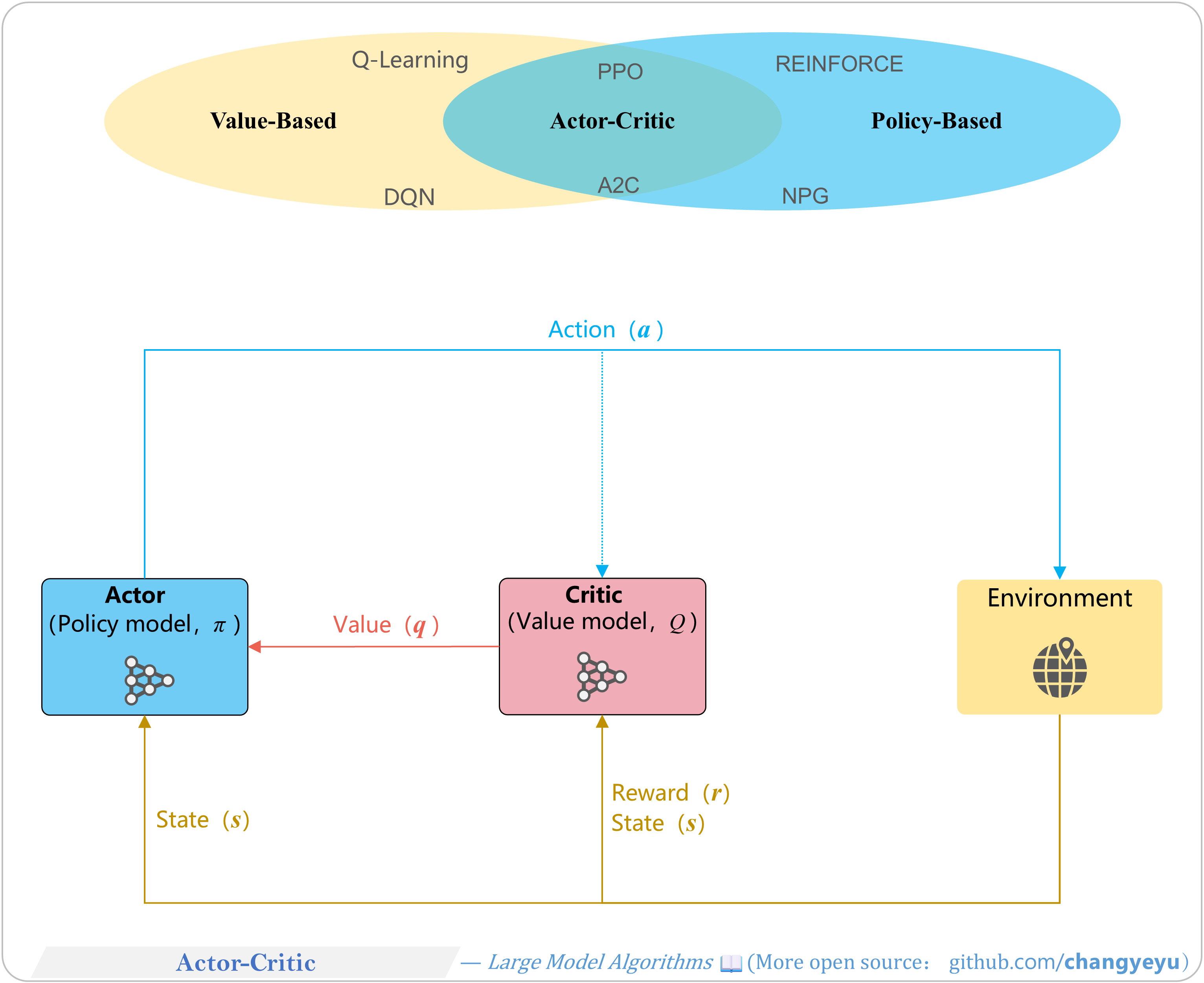
【RL basics】Value-Based vs Policy-Based
- Value-Based: estimate value functions (V or Q) → derive policy.
- Policy-Based: directly parameterize and optimize policy π.
- Actor-Critic: combines both approaches, learning policy (Actor) and value (Critic) together.

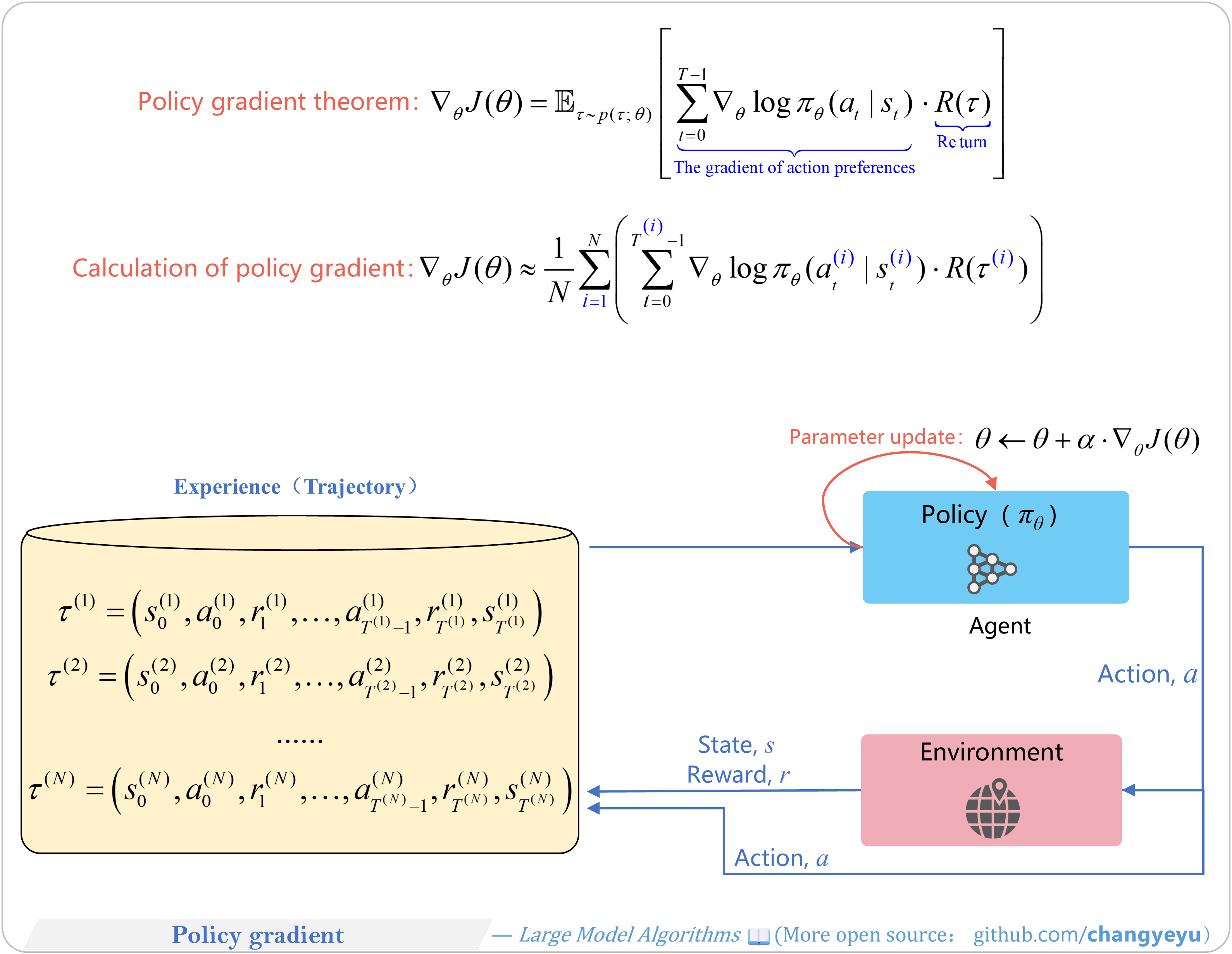
【RL basics】Policy gradient
- Policy Gradients underpin many RL algorithms (PPO, GRPO, DPG, Actor-Critic variants). Sutton et al. formalized the Policy Gradient Theorem. Unlike value-based methods, policy-based methods optimize π directly via gradient ascent.
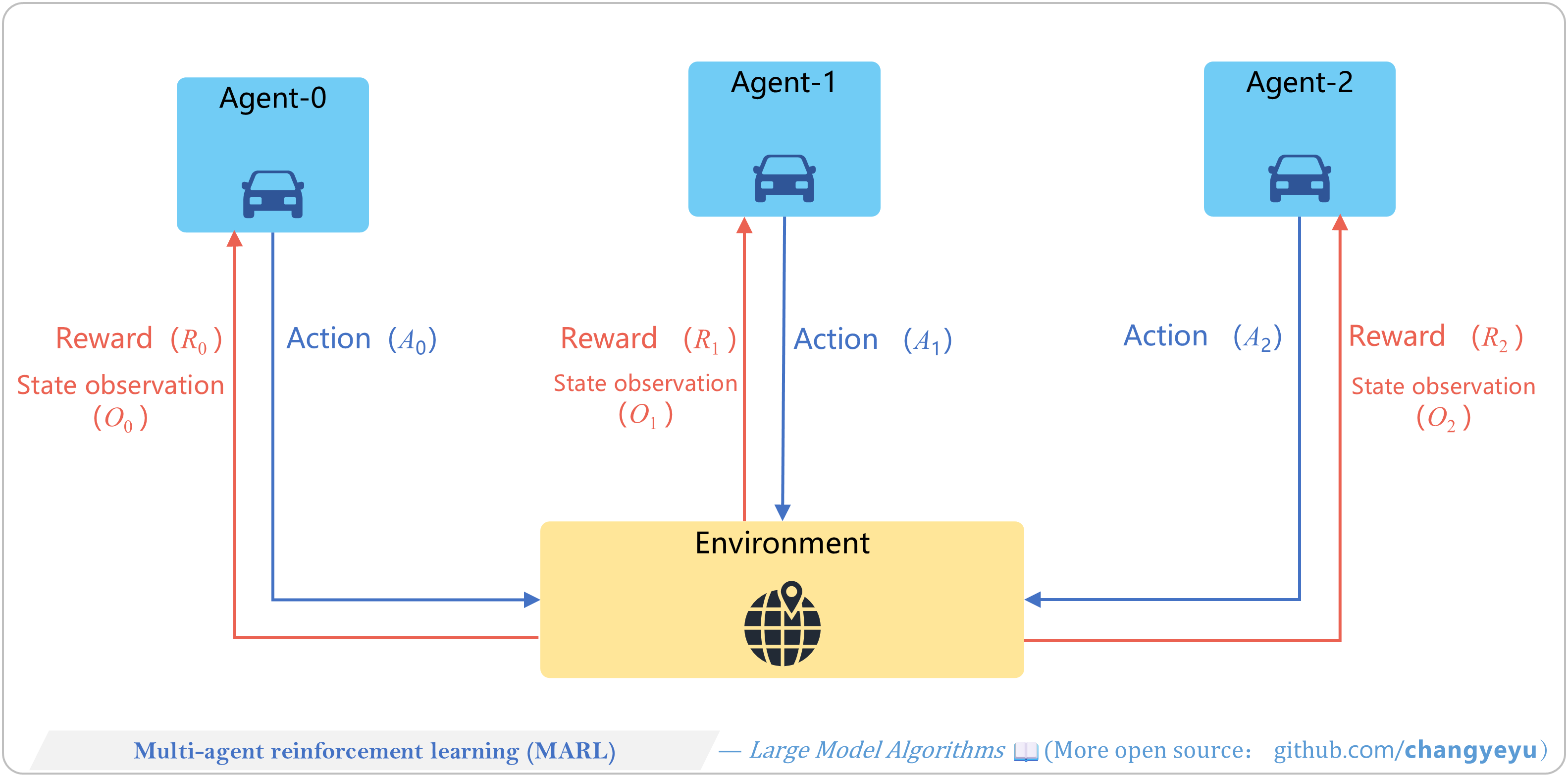
【RL basics】Multi-agent reinforcement learning(MARL)
- MARL studies multiple agents learning to cooperate or compete in a shared environment (e.g., AlphaGo, AlphaStar, OpenAI Five).
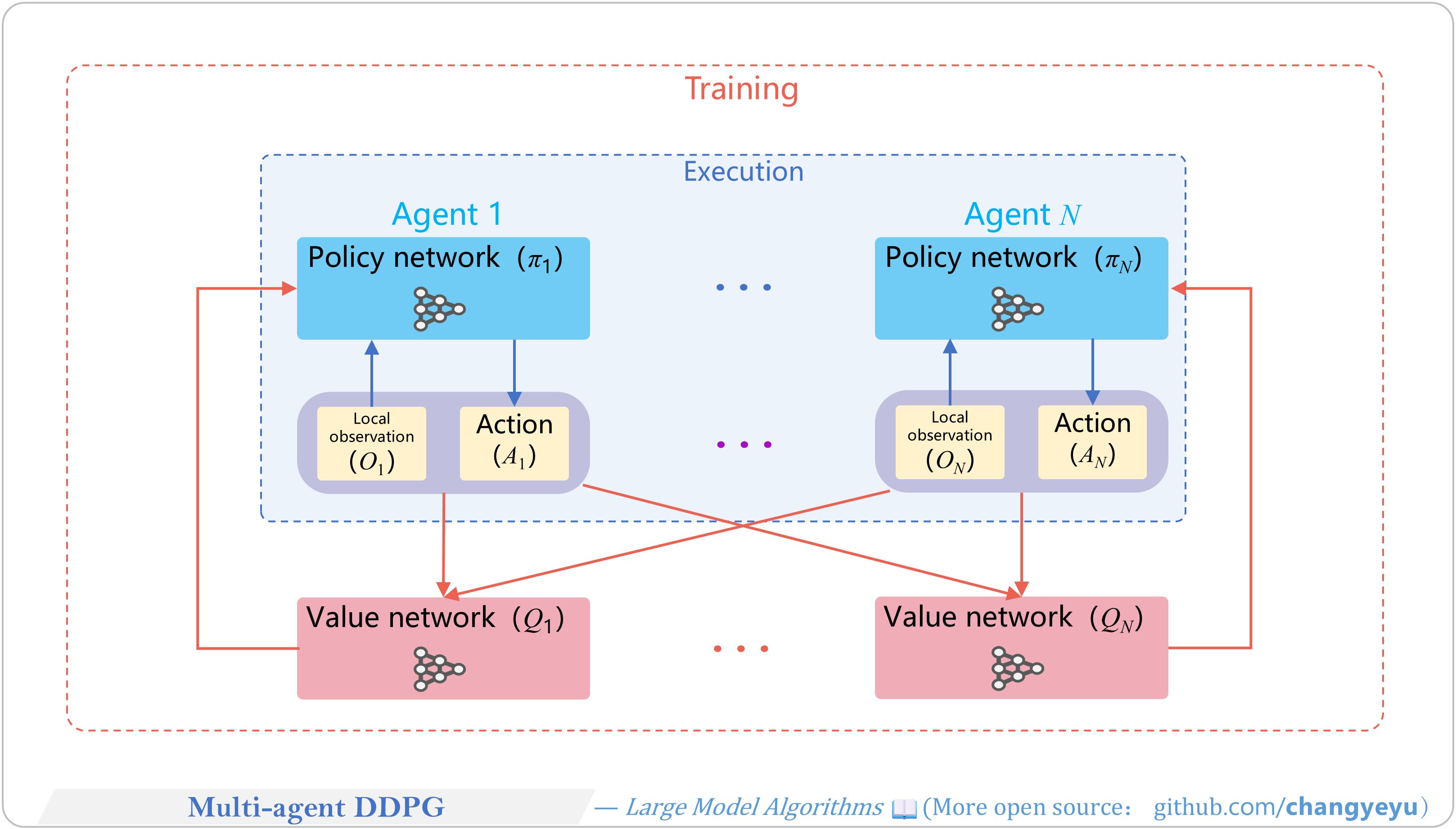
【RL basics】Multi-agent DDPG [41]
- MADDPG (Multi-Agent DDPG), introduced by OpenAI in 2017, uses N actor networks (π₁…πₙ) and N critic networks (Q₁…Qₙ). Each critic takes all agents’ actions and observations to output Q-value for its agent.
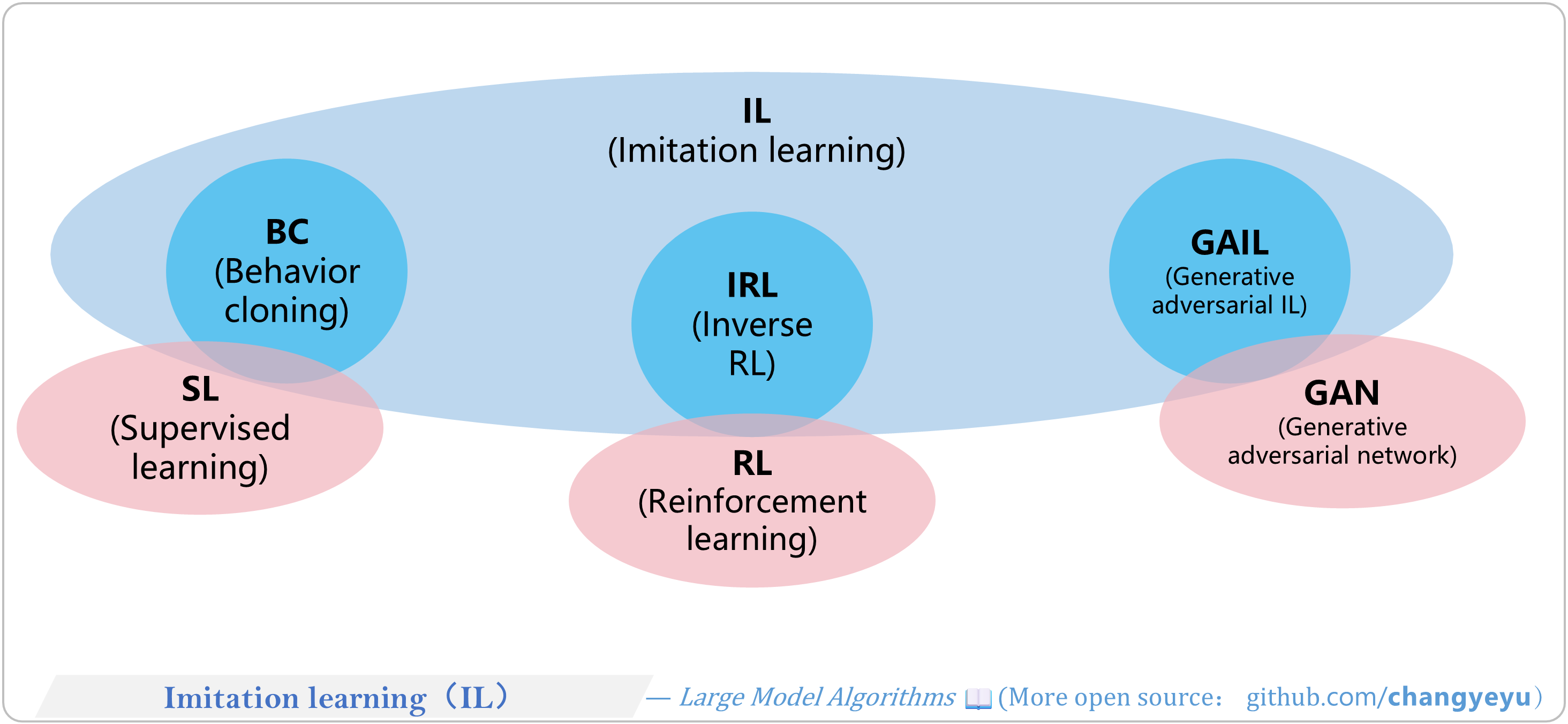
【RL basics】Imitation learning(IL)
- Imitation Learning learns policies by observing and mimicking experts, without explicit reward functions. Main approaches:
- Behavioral Cloning (BC): supervised learning on state-action pairs.
- Inverse Reinforcement Learning (IRL): infer reward function from expert behavior, then learn policy.
- Generative Adversarial Imitation Learning (GAIL): adversarially train policy against expert.
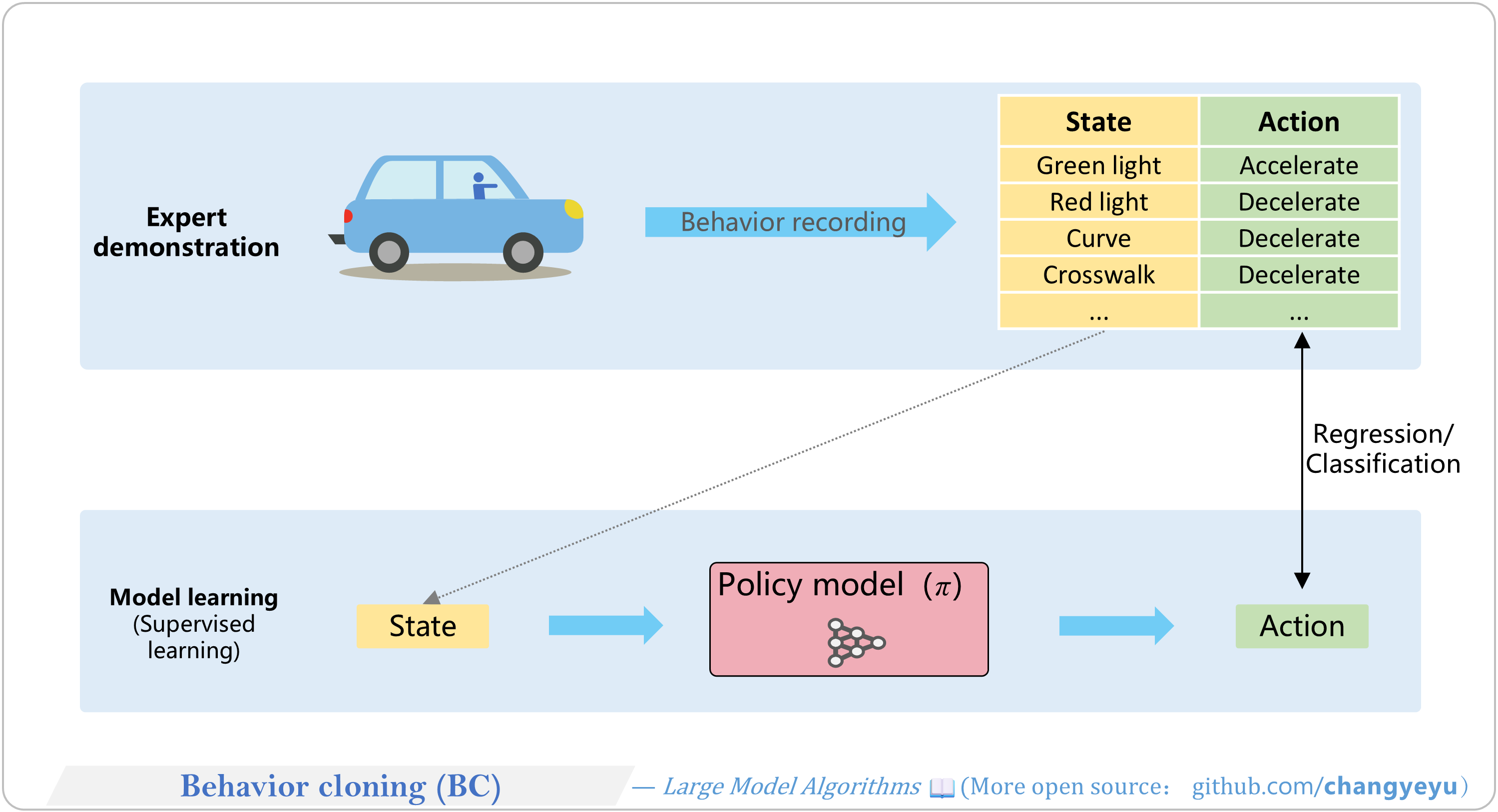
【RL basics】Behavior cloning(BC)
- Behavioral Cloning treats imitation as regression/classification: input state → predict expert action. Minimizes difference between predicted and expert actions.
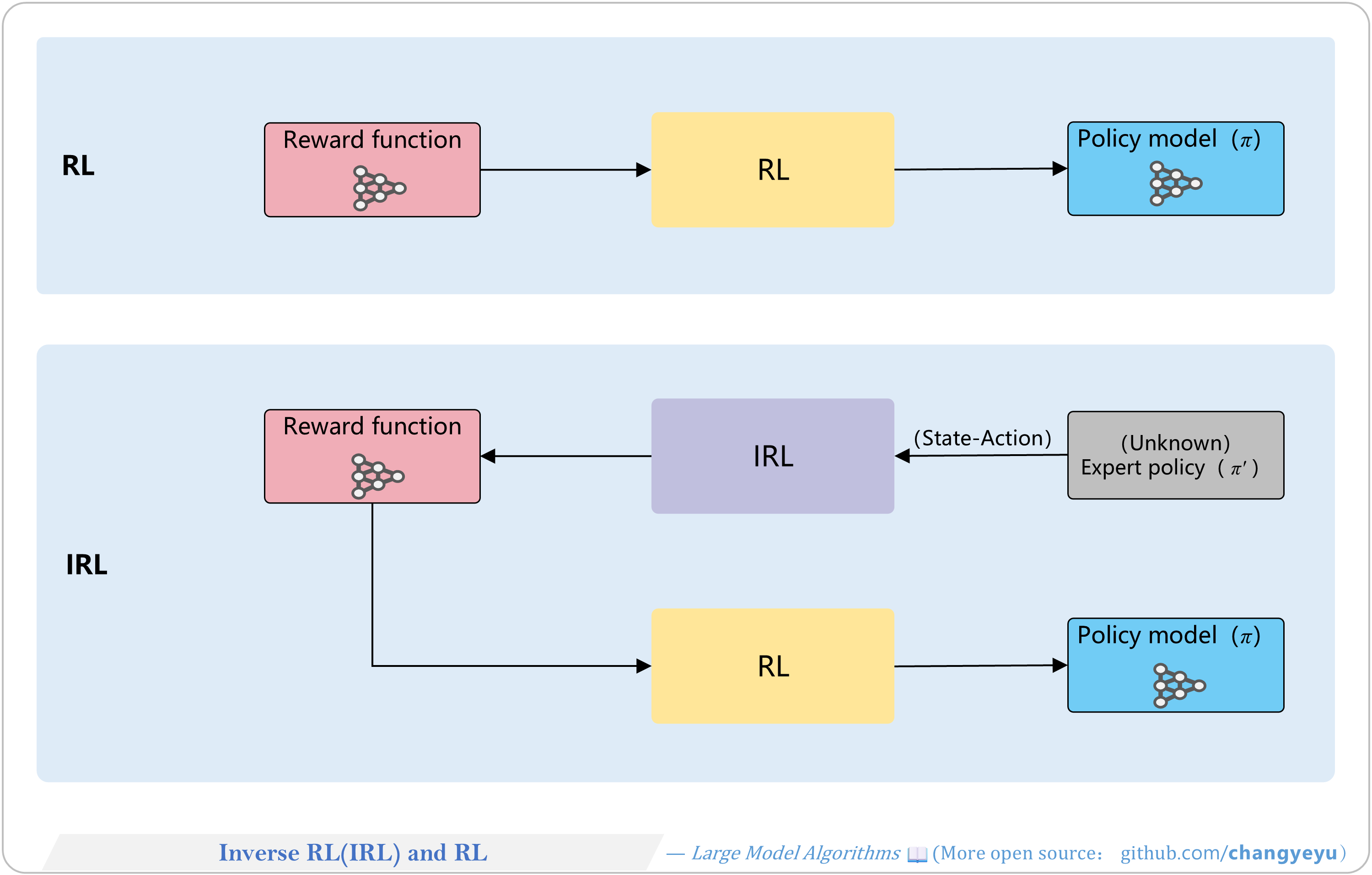
【RL basics】Inverse RL(IRL) and RL
- IRL infers the underlying reward function from expert behavior, then learns the optimal policy.
- Andrew Y. Ng and Stuart Russell formalized IRL in their 2000 paper Algorithms for Inverse Reinforcement Learning.

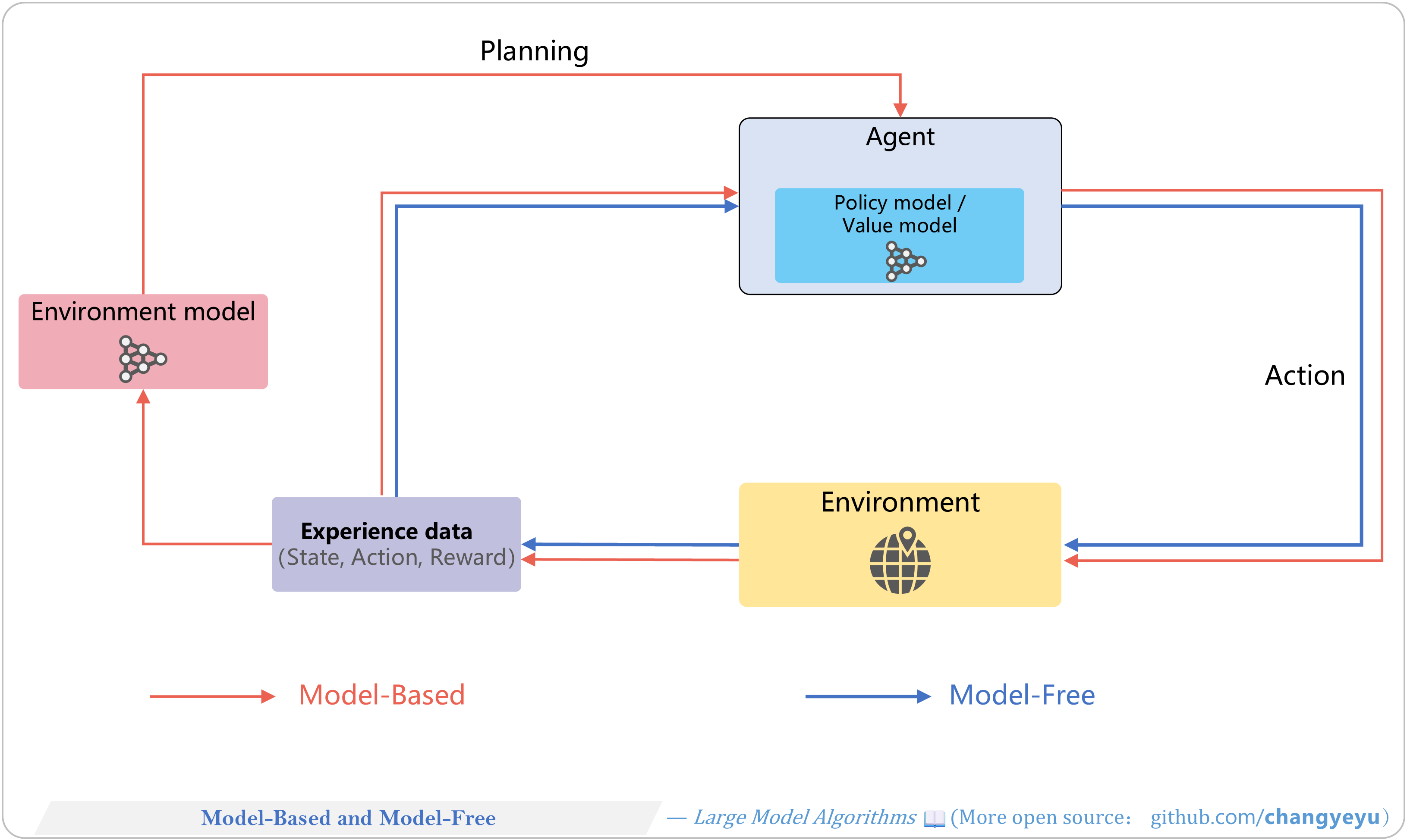
【RL basics】Model-Based and Model-Free
- Model-Based: uses environment model for planning
- Model-Free: learns value or policy directly from interaction.
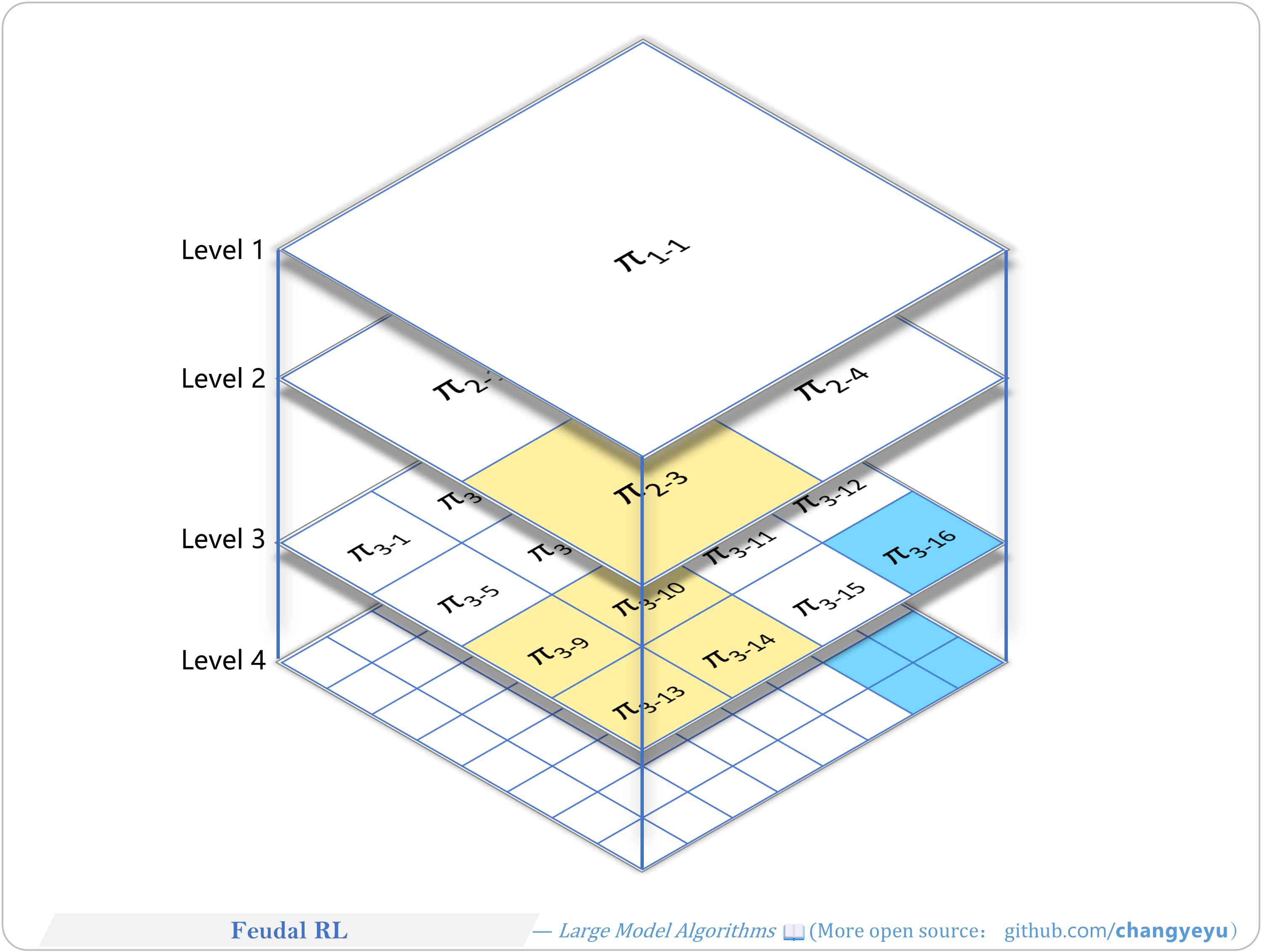
【RL basics】Feudal RL
- Hierarchical RL decomposes tasks into sub-tasks or sub-policies. Feudal RL and MAXQ are classic examples. Geoffrey E. Hinton proposed Feudal RL; Hinton won the 2024 Nobel Prize in Physics.
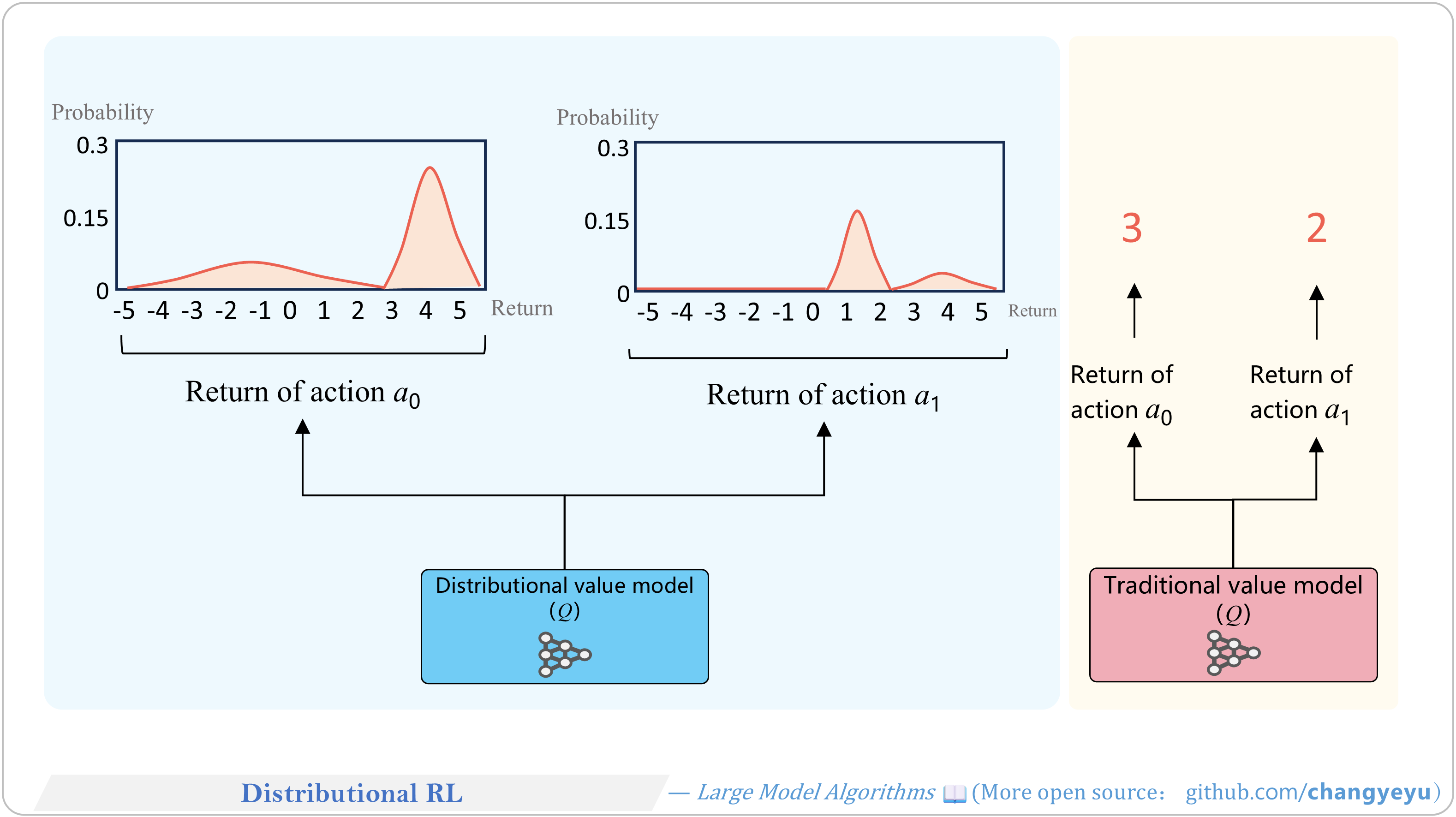
【RL basics】Distributional RL
- Distributional RL models the distribution of returns rather than just the expectation, capturing richer uncertainty information for policy optimization.
【Policy Optimization & Variants】Actor-Critic
- The Actor-Critic architecture combines a policy model (Actor) and a value model (Critic). Algorithms like PPO, DPG, DDPG, TD3 are based on this.
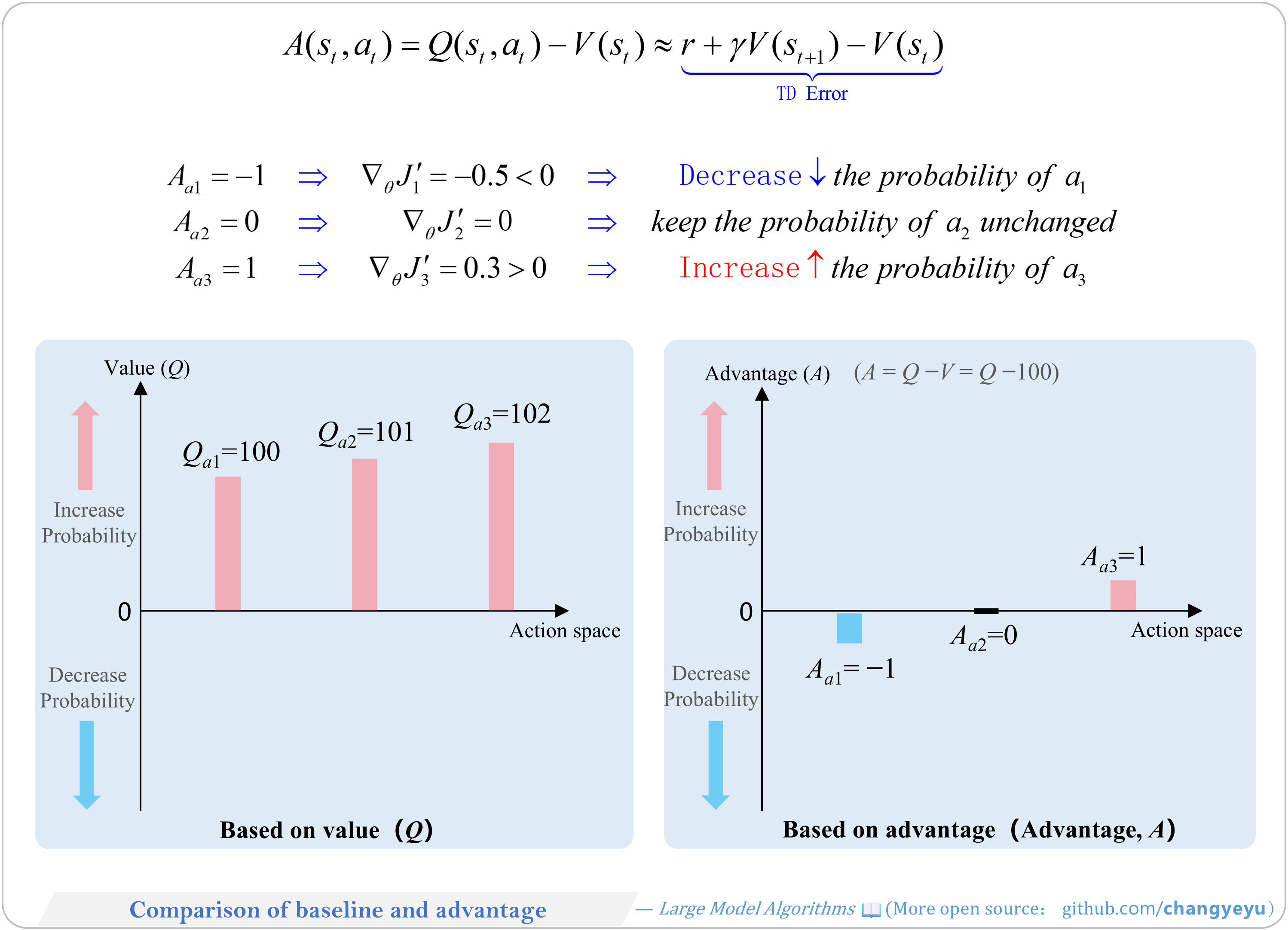
【Policy Optimization & Variants】Comparison of baseline and advantage
- A2C introduces a baseline (state value V(s)) and constructs the Advantage Function A(s,a) = Q(s,a) – V(s), reducing variance.
【Policy Optimization & Variants】GAE(Generalized Advantage Estimation)
- GAE (Generalized Advantage Estimation) was proposed by John Schulman et al. and is a key component of algorithms like PPO.
- It leverages the TD(λ) idea to balance bias and variance by tuning the λ parameter.
- Computation is typically performed recursively over time steps.
- The core implementation pseudocode is shown below:
import numpy as np
def compute_gae(rewards, values, gamma=0.99, lambda_=0.95):
"""
Parameters:
rewards (list or np.ndarray): The rewards collected at each time step, shape (T,)
values (list or np.ndarray): The value estimates for each state V, shape (T+1,)
gamma (float): Discount factor γ
lambda_ (float): Decay parameter λ for GAE
Returns:
np.ndarray: Advantage estimates A, shape (T,). For example, for T=5, A = [A0, A1, A2, A3, A4]
"""
T = len(rewards) # Eg. End: t=T-1, T = 5
advantages = np.zeros(T) # Eg. A=[A0, A1, A2, A3, A4]
gae = 0
# From t=T-1, to t=0
for t in reversed(range(T)):
# δ_t = r_t + γ * V(s_{t+1}) - V(s_t)
delta = rewards[t] + gamma * values[t+1] - values[t]
# A_t = δ_t + γ * λ * A_{t+1}
gae = delta + gamma * lambda_ * gae
advantages[t] = gae
return advantages

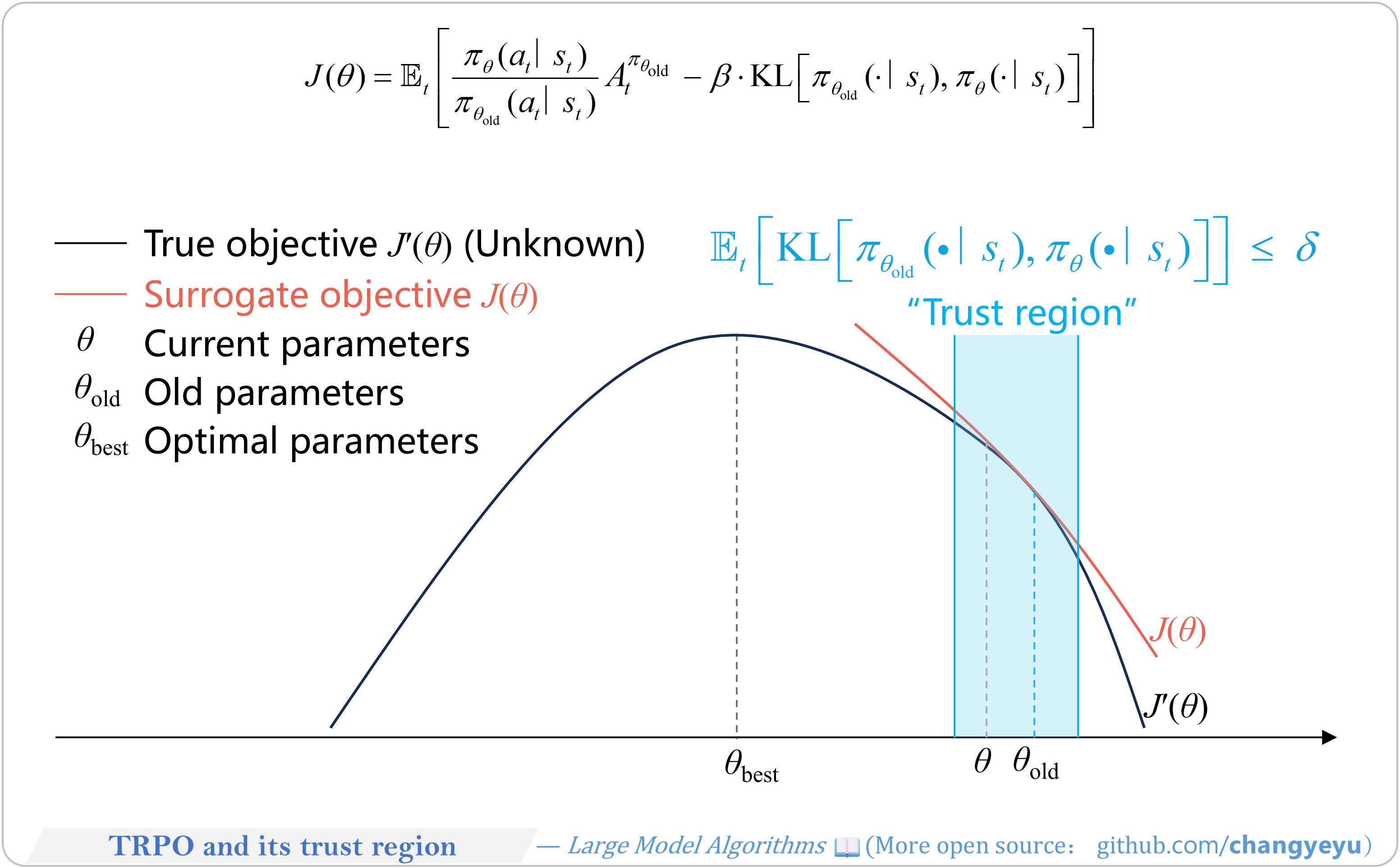
【Policy Optimization & Variants】TRPO and its trust region
- TRPO (Trust Region Policy Optimization) is the predecessor to PPO.
- It improves policy gradient methods by introducing a trust region constraint and importance sampling.
- The core idea is to maximize the objective J(θ) while limiting the divergence between the new and old policies.

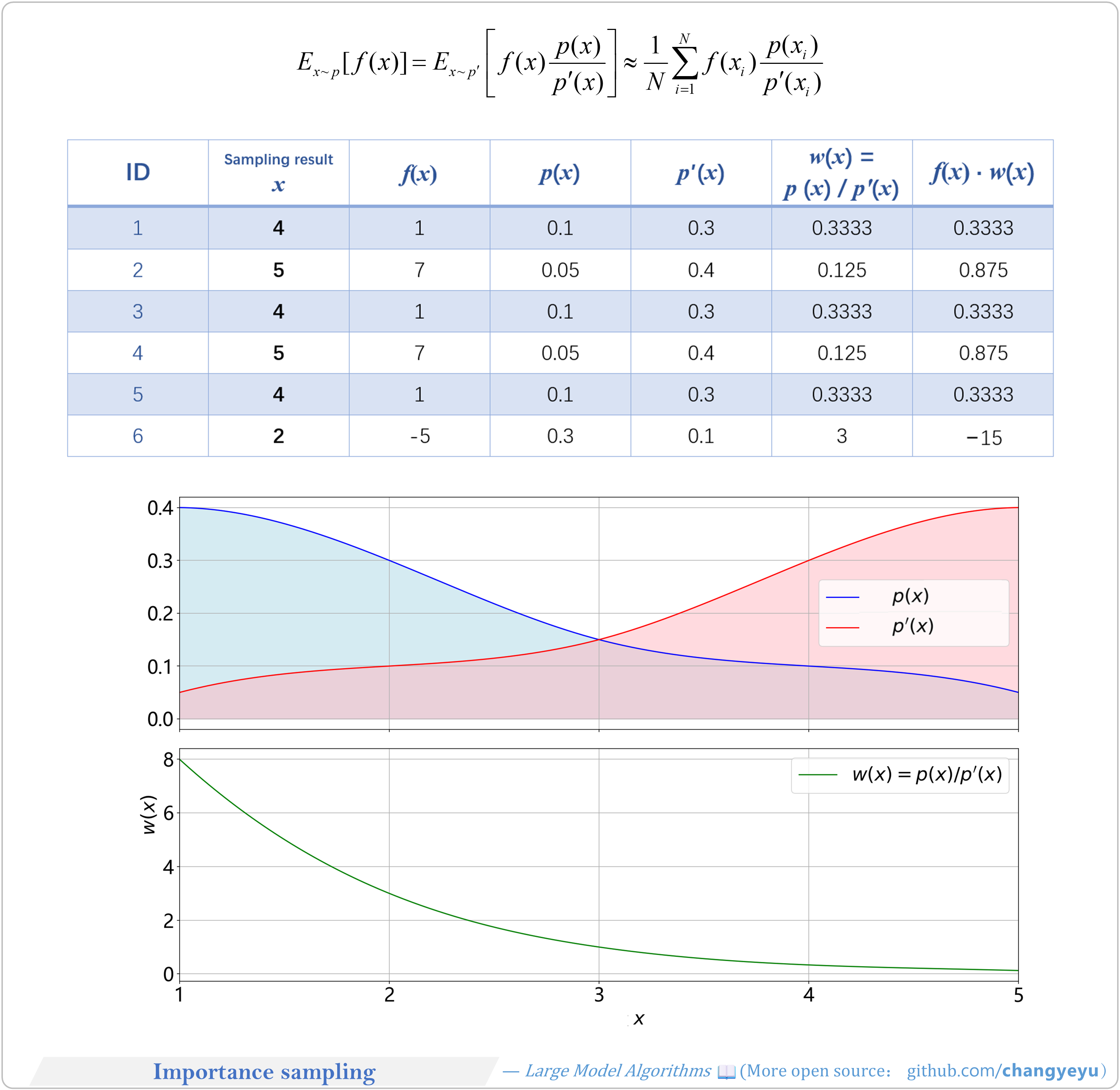
【Policy Optimization & Variants】Importance sampling
- Importance Sampling corrects distribution mismatch between old and new policies, enabling reuse of old data to optimize the new policy.
- It samples from an auxiliary distribution and applies importance weights to improve estimation efficiency.
- It requires that if p(x)>0 then p′(x)>0, ensuring no probability mass is lost during reweighting.
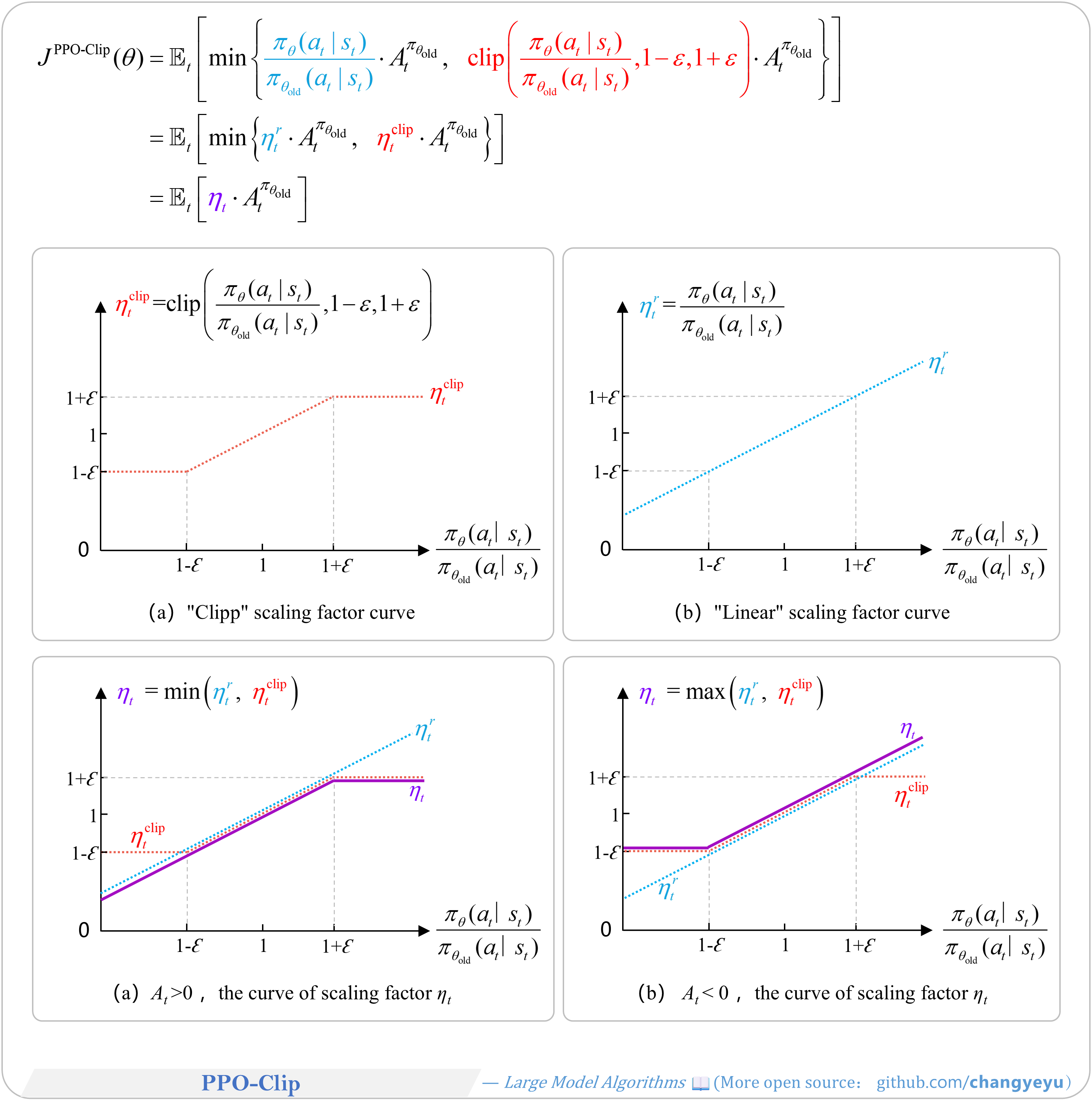
【Policy Optimization & Variants】PPO-Clip
- PPO-Clip refers to PPO with a clipped surrogate objective.
- The goal is to maximize expected future return by optimizing J(θ) with a clipping mechanism.
- The clipping limits the probability ratio r(θ) to [1−ε,1+ε], preventing overly large policy updates.
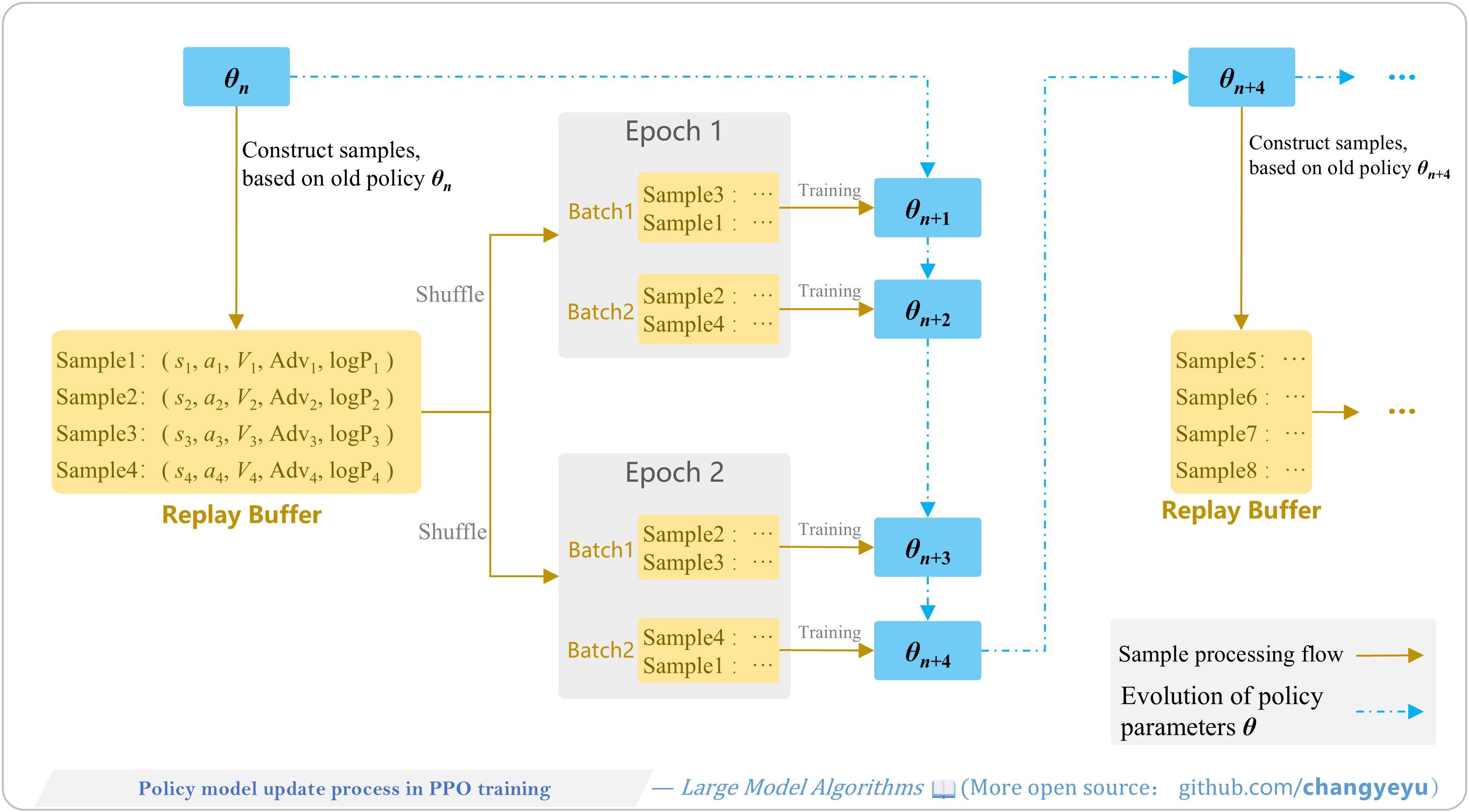
【Policy Optimization & Variants】Policy model update process in PPO training
- PPO training alternates between two phases:
- Sample Collection: generate trajectories with the old policy and store them in a replay buffer.
- Multiple PPO Training Rounds: shuffle and split the buffer into mini-batches, then run multiple PPO epochs per mini-batch (computing clipped policy loss, value loss, and entropy bonus) to update parameters.
- These phases repeat iteratively until training completes.
【Policy Optimization & Variants】PPO Pseudocode
# Abbreviations: R = rewards, V = values, Adv = advantages, J = objective, P = probability
for iteration in range(num_iterations): # Perform num_iterations training iterations
# [1/2] Collect samples (prompt, response_old, logP_old, Adv, V_target)
prompt_batch, response_old_batch = [], []
logP_old_batch, Adv_batch, V_target_batch = [], [], []
for _ in range(num_examples):
logP_old, response_old = actor_model(prompt)
V_old = critic_model(prompt, response_old)
R = reward_model(prompt, response_old)[-1]
logP_ref = ref_model(prompt, response_old)
# KL penalty. Note: R here is only the reward for the final token
KL = logP_old - logP_ref
R_with_KL = R - scale_factor * KL
# Compute advantage Adv via GAE
Adv = GAE_Advantage(R_with_KL, V_old, gamma, λ)
V_target = Adv + V_old
prompt_batch += prompt
response_old_batch += response_old
logP_old_batch += logP_old
Adv_batch += Adv
V_target_batch += V_target
# [2/2] PPO training loop: multiple parameter updates
for _ in range(ppo_epochs):
mini_batches = shuffle_split(
(prompt_batch, response_old_batch, logP_old_batch, Adv_batch, V_target_batch),
mini_batch_size
)
for prompt, response_old, logP_old, Adv, V_target in mini_batches:
logits, logP_new = actor_model(prompt, response_old)
V_new = critic_model(prompt, response_old)
# Probability ratio: ratio(θ) = π_θ(a|s) / π_{θ_old}(a|s)
ratios = exp(logP_new - logP_old)
# Compute clipped policy loss
L_clip = -mean(
min(ratios * Adv,
clip(ratios, 1 - ε, 1 + ε) * Adv)
)
S_entropy = mean(compute_entropy(logits)) # Compute policy entropy
Loss_V = mean((V_new - V_target) ** 2) # Compute value function loss
# Total loss
Loss = L_clip + C1 * Loss_V - C2 * S_entropy
backward_update(Loss, L_clip, Loss_V) # Backpropagate and update parameters
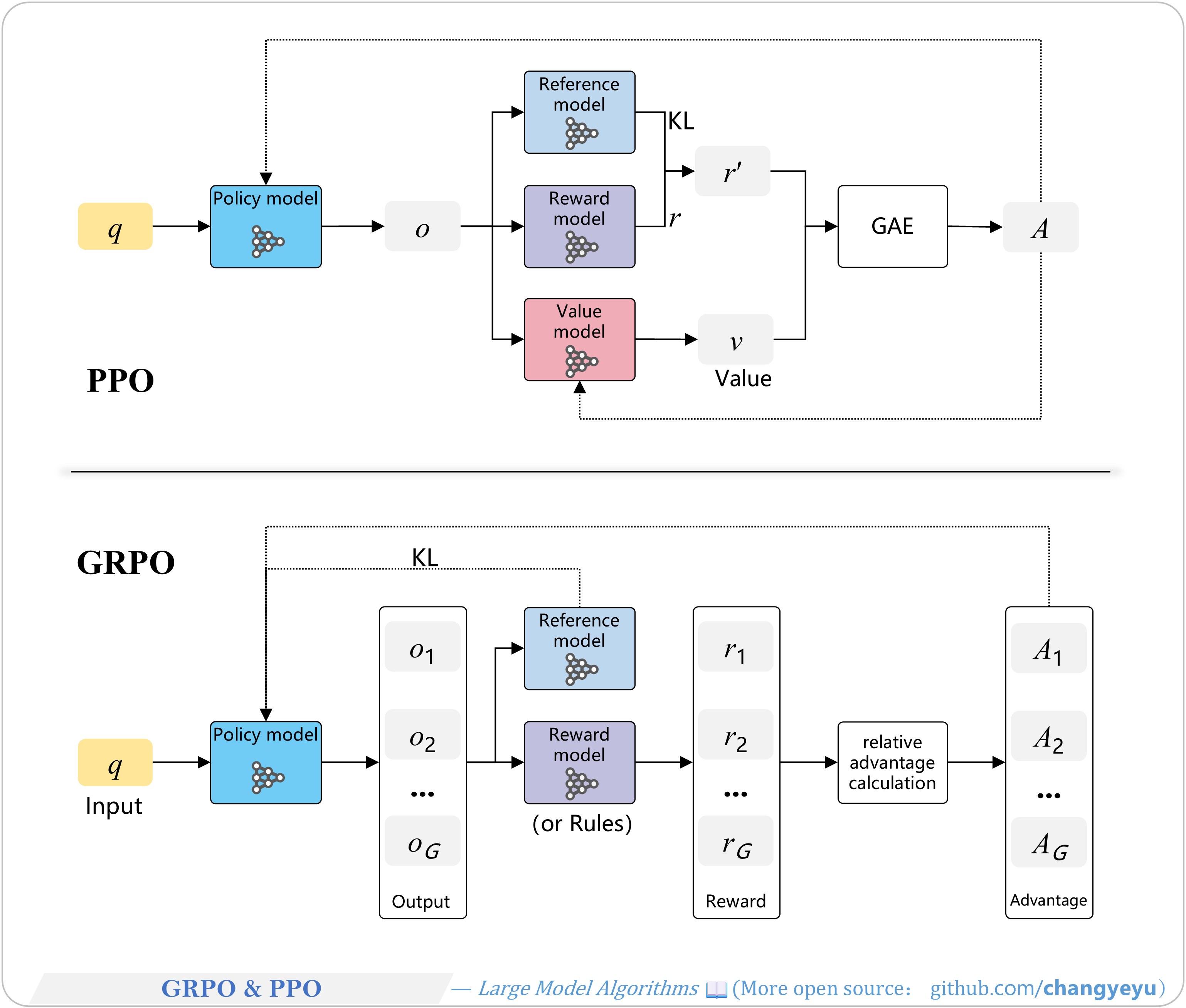
【Policy Optimization & Variants】GRPO & PPO [72]
- GRPO (Group Relative Policy Optimization) is a policy-based RL algorithm by DeepSeek.
- It removes the separate value network and uses group-relative advantage estimation as a baseline, reducing resource usage while maintaining stability.

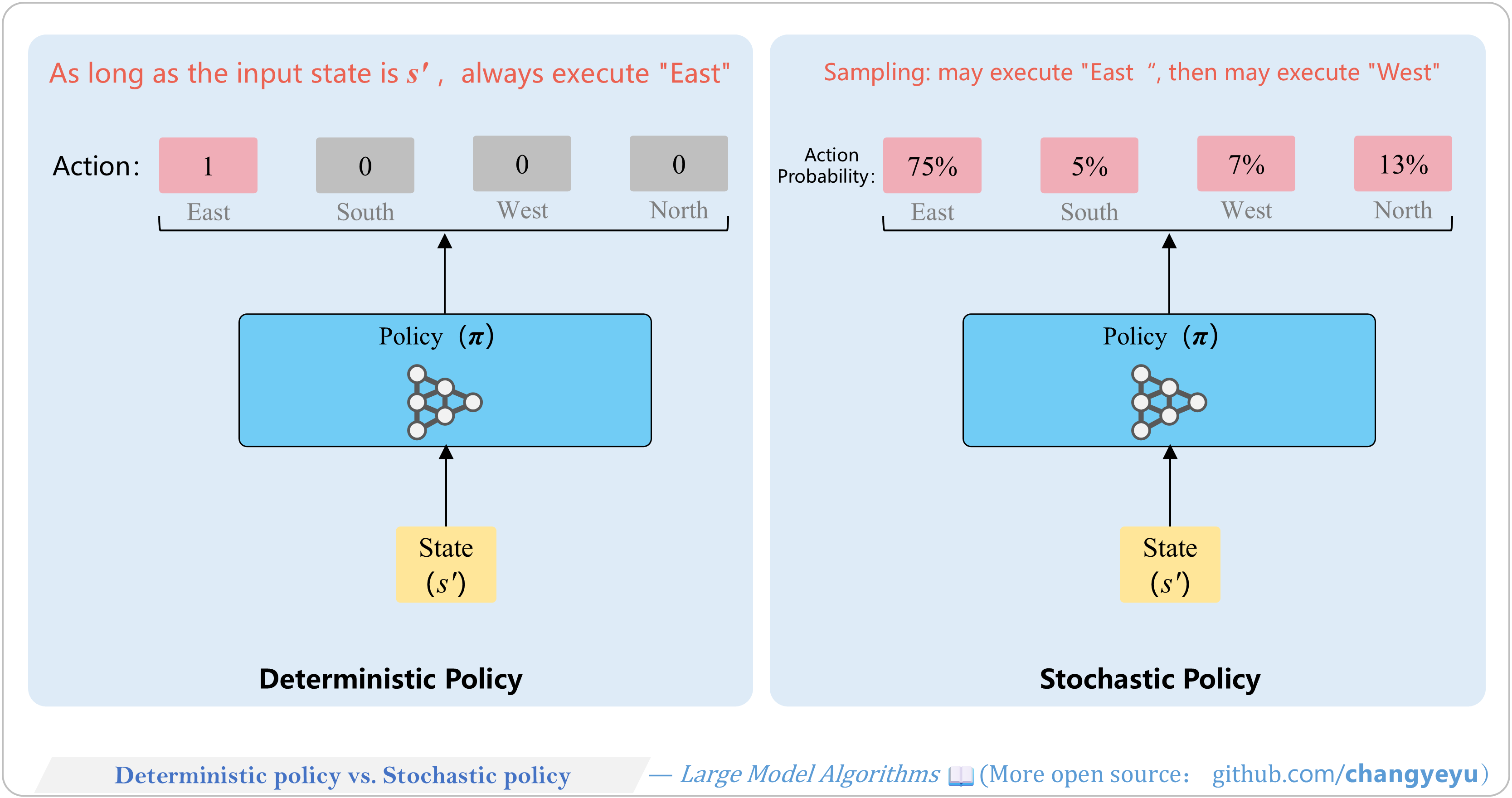
【Policy Optimization & Variants】Deterministic policy vs. Stochastic policy
- Reinforcement learning policies can be deterministic or stochastic.
- Deterministic policies output a single action per state.
- Stochastic policies output a probability distribution over actions.
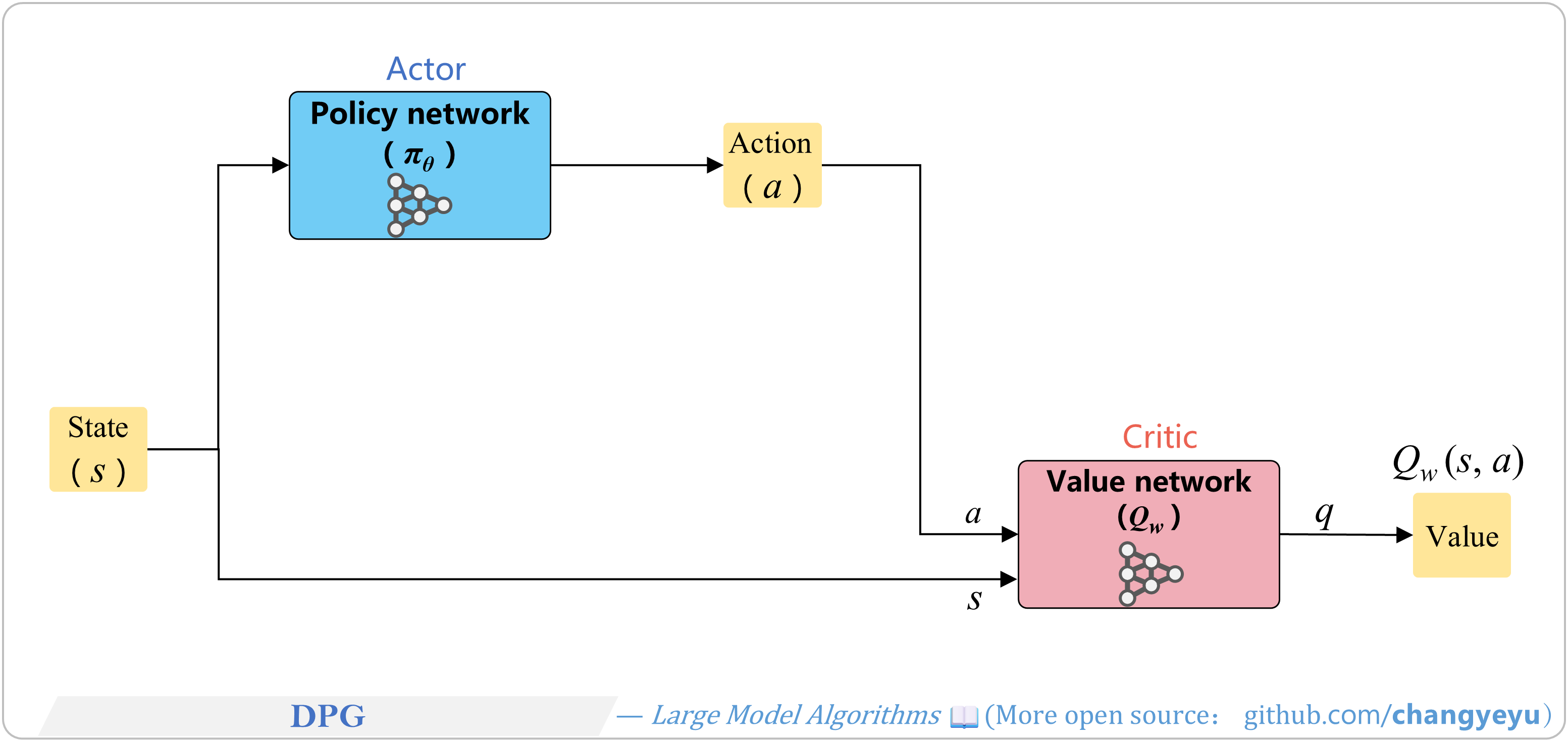
【Policy Optimization & Variants】DPG
- DPG (Deterministic Policy Gradient) was formalized by David Silver et al. in 2014 at DeepMind.
- It uses an actor-critic architecture for continuous action spaces.
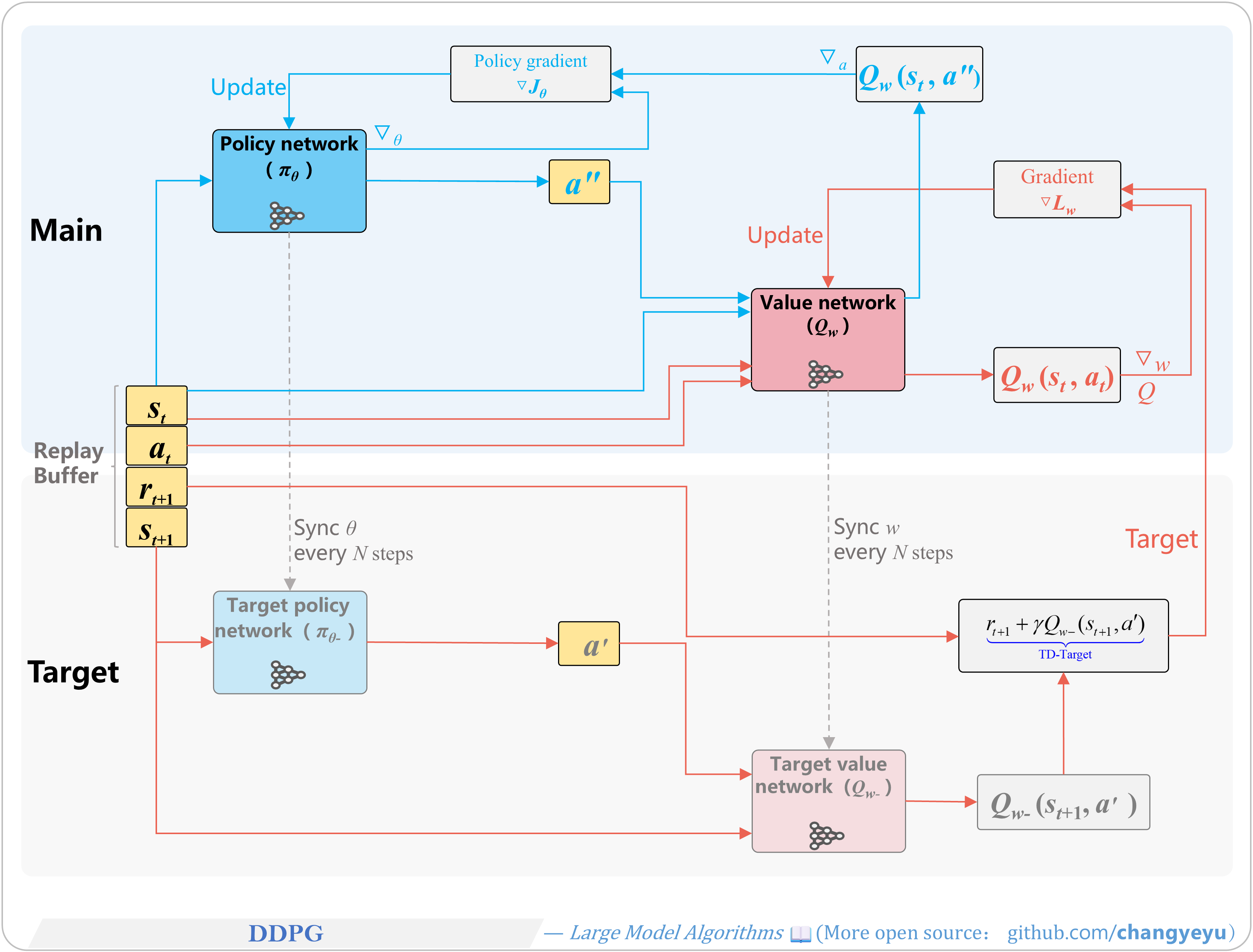
【Policy Optimization & Variants】DDPG(Deep Deterministic Policy Gradient)
- DDPG extends DPG by incorporating deep Q-network concepts, requiring four networks (2 actors, 2 critics).
- TD3 (Twin Delayed DDPG) further improves DDPG with six networks (2 actors, 4 critics) and delayed updates for stability.

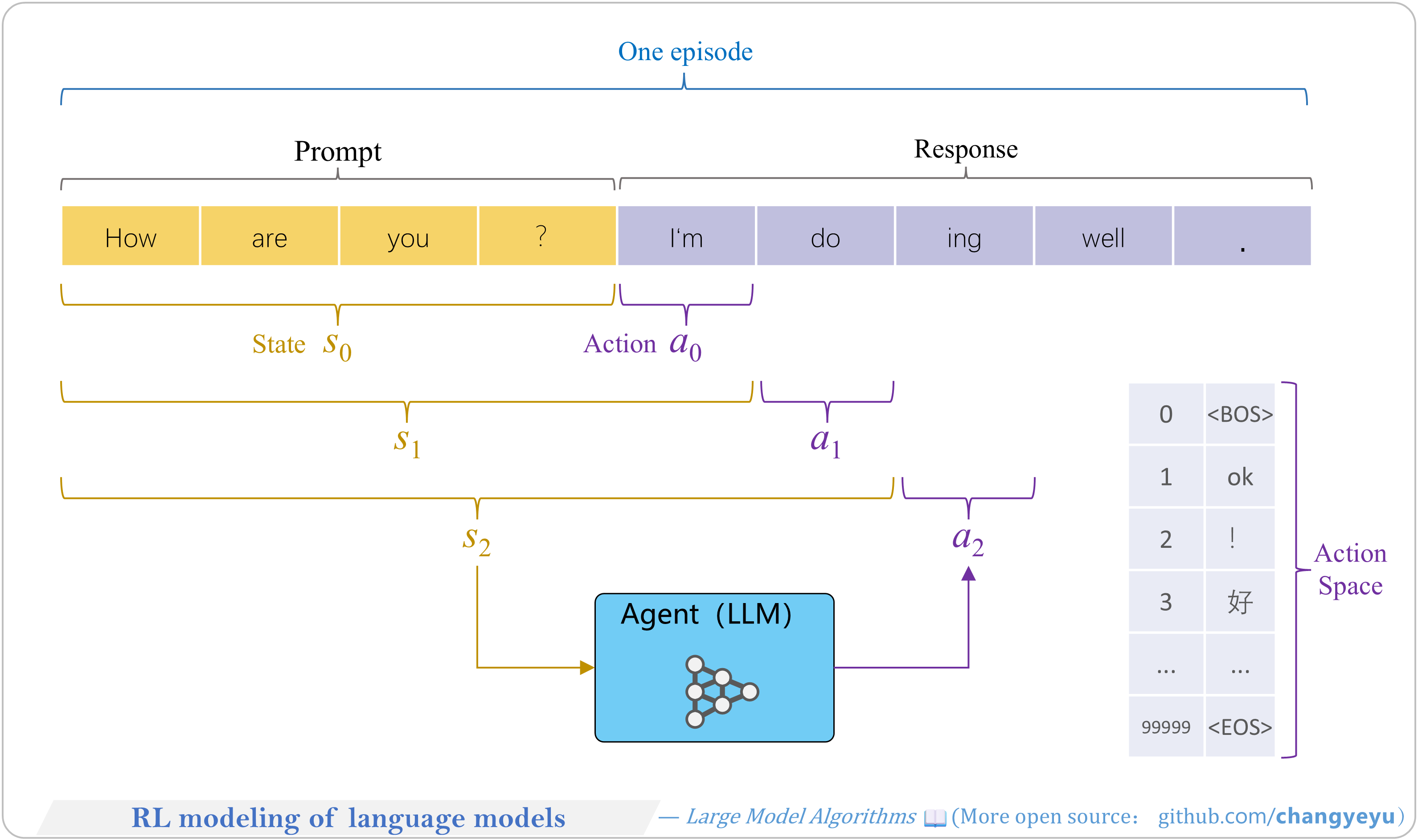
【RLHF and RLAIF】RL modeling of language models
- To apply RL to LMs, define:
- Action: selecting a token.
- Action Space: the vocabulary (~100k tokens).
- Agent: the LLM.
- Policy: the model parameters π.
- State: the generated token sequence.
- Episode: one full generation until EOS.
- Value: expected future return, estimated by a value network.

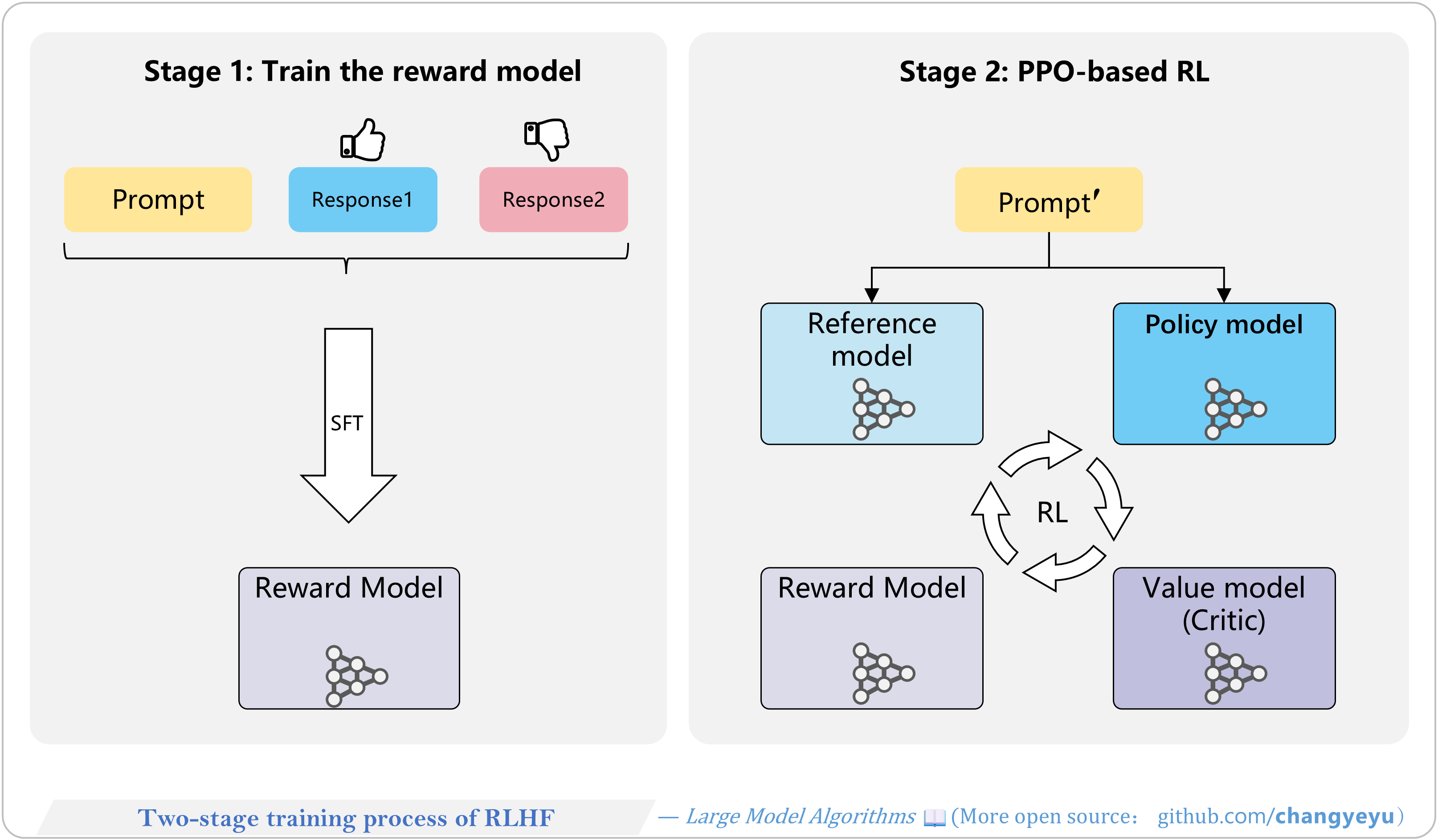
【RLHF and RLAIF】Two-stage training process of RLHF
- RLHF involves two stages:
- Phase 1 (SFT & Reward Model): generate candidate responses and collect human preference labels to train the reward model.
- Phase 2 (RL with PPO): optimize the policy model using PPO, guided by the reward model and constrained by the reference model’s KL penalty.
- Phase 1 uses preference pairs (Prompt + Responses); Phase 2 uses only prompts, relying on RL interactions.
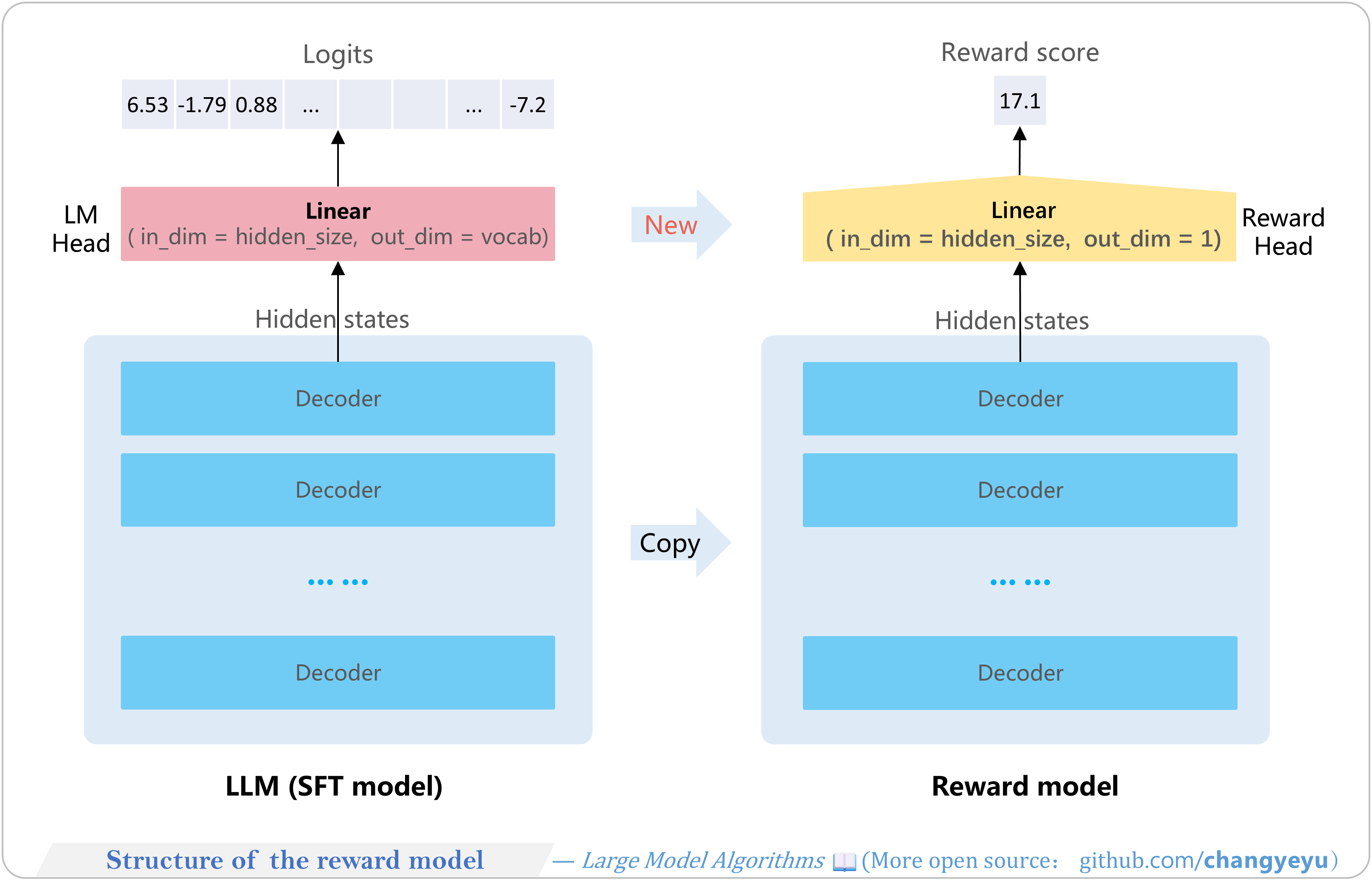
【RLHF and RLAIF】Structure of the reward model
- The Reward Model shares the decoder layers of the SFT model and replaces its LM head with a reward head that outputs a single scalar score.
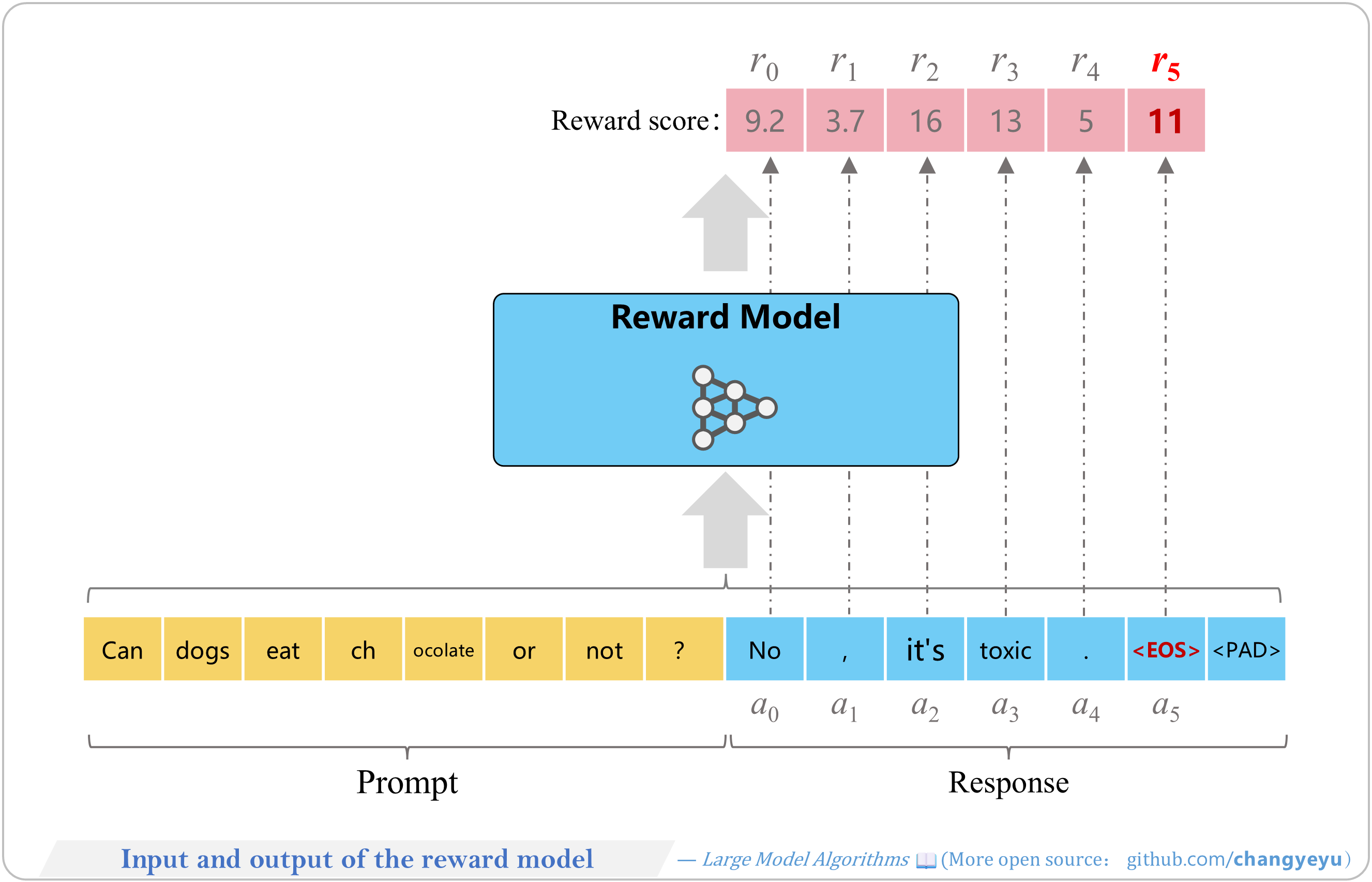
【RLHF and RLAIF】Input and output of the reward model
- Input: Prompt + Response sequence.
- Output: reward scores r0, r1, … for each token of the response.
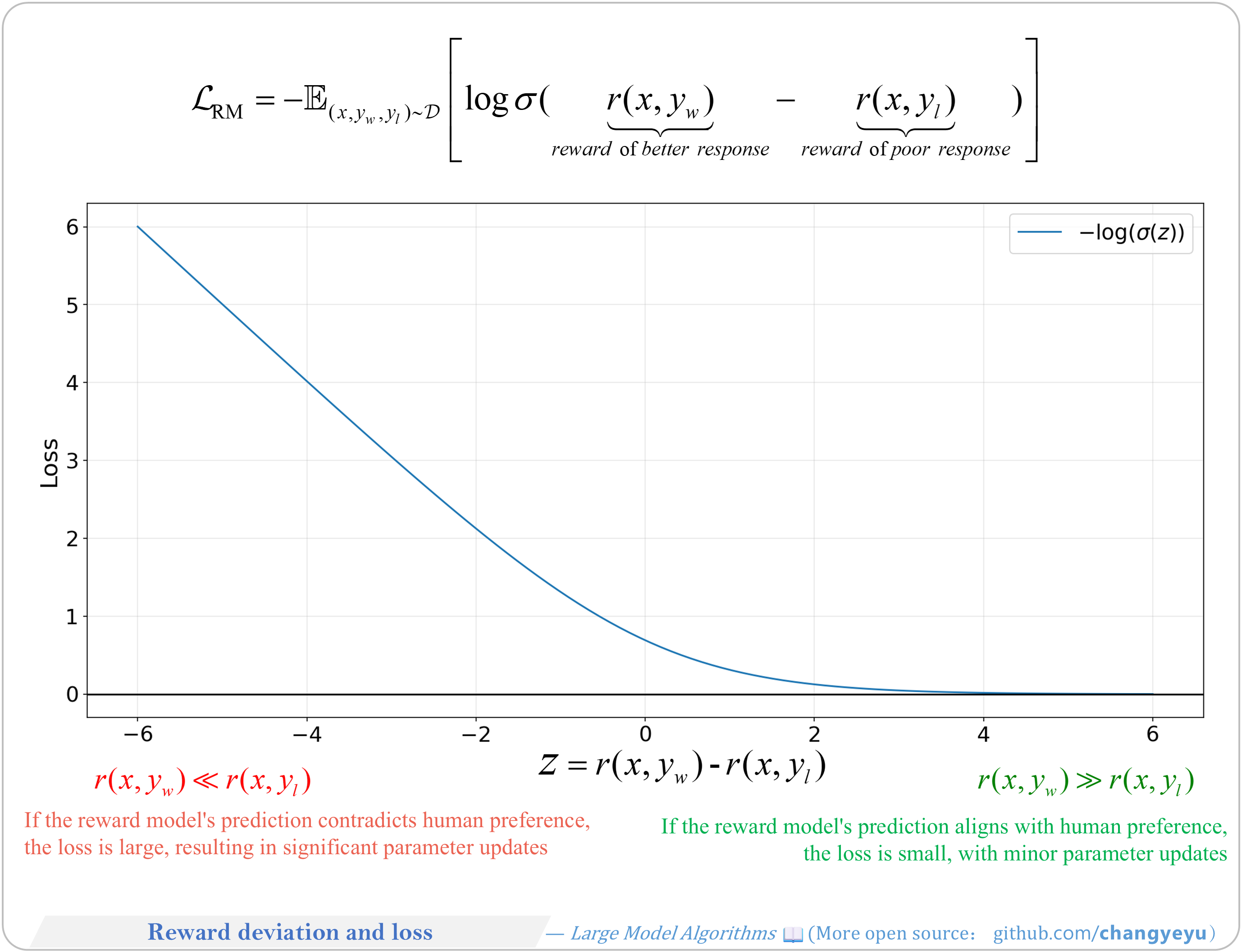
【RLHF and RLAIF】Reward deviation and loss
- The Reward Model’s objective is a contrastive negative log-likelihood loss, fitting human preference scores similarly to DPO’s reward modeling.
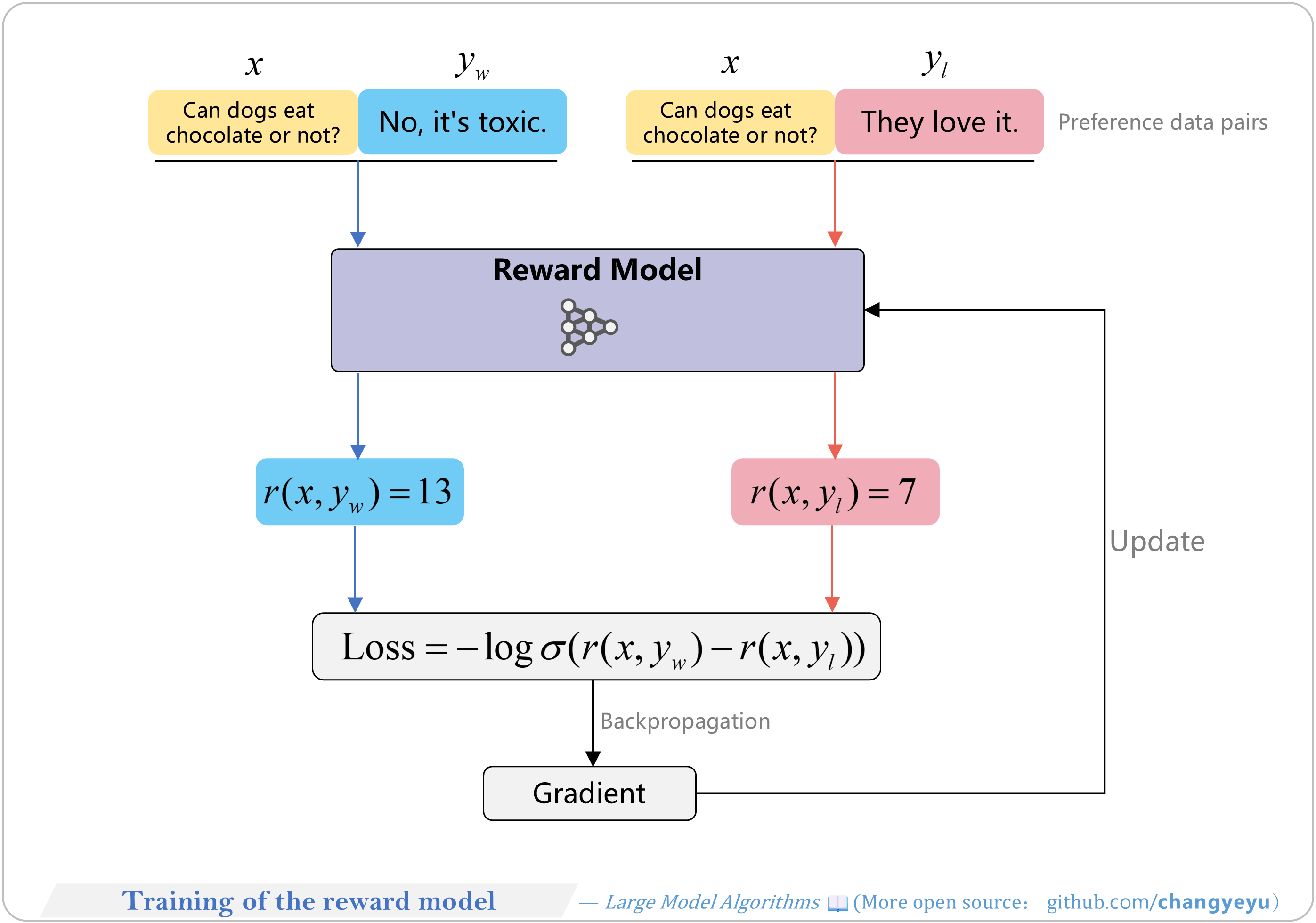
【RLHF and RLAIF】Training of the reward model
- (1) Compute reward scores for preferred (yw) and less preferred (yl) responses.
- (2) Calculate loss based on score difference.
- (3) Backpropagate to update parameters.
- (4) Iterate over preference samples until alignment with human judgments.
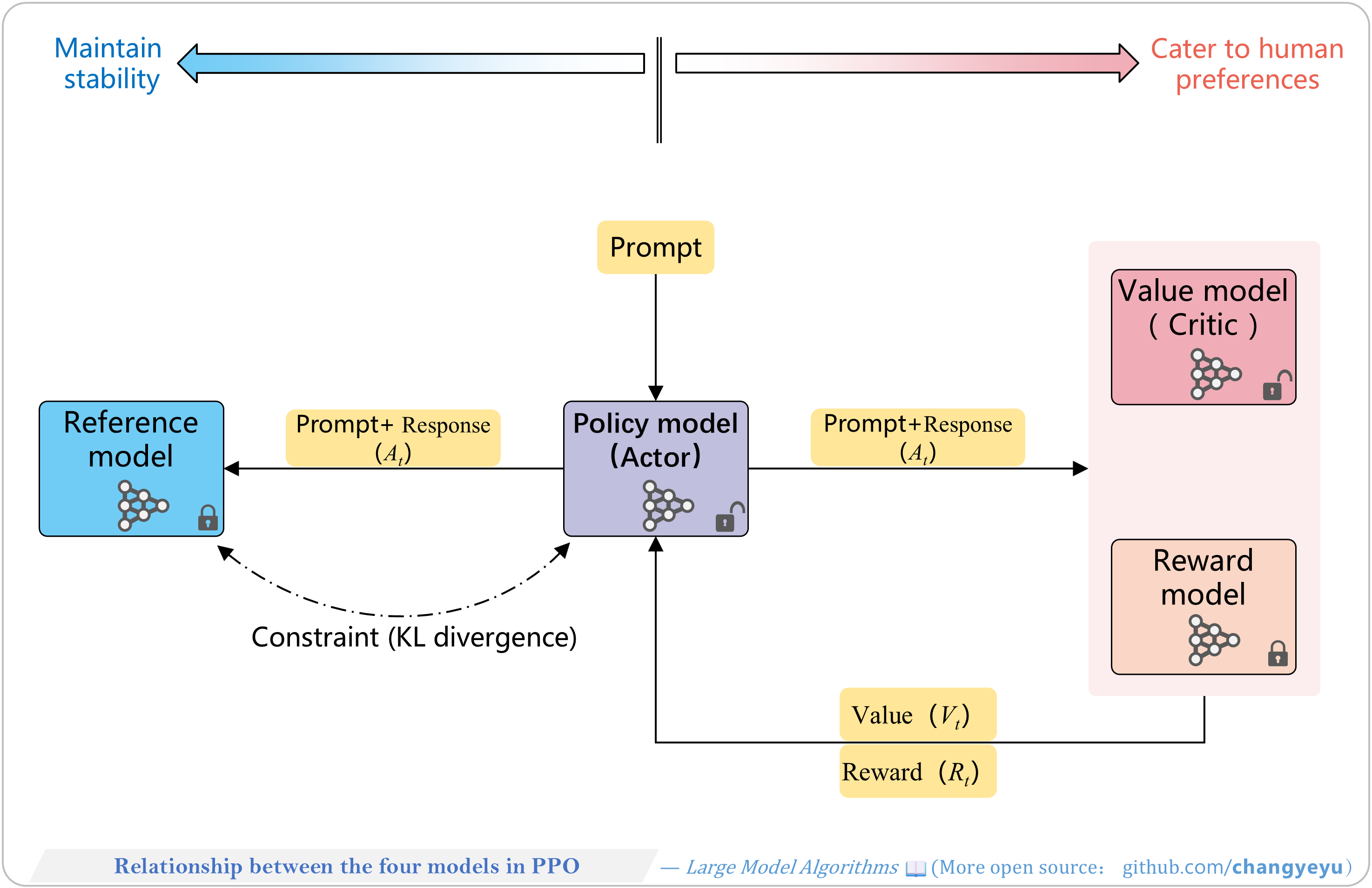
【RLHF and RLAIF】Relationship between the four models in PPO
- Four models collaborate:
- Policy Model (Actor): generates responses, balances reward guidance and KL constraint.
- Reference Model: provides KL baseline to prevent divergence.
- Reward Model: scores responses to simulate human feedback.
- Value Model (Critic): estimates long-term returns Vt.
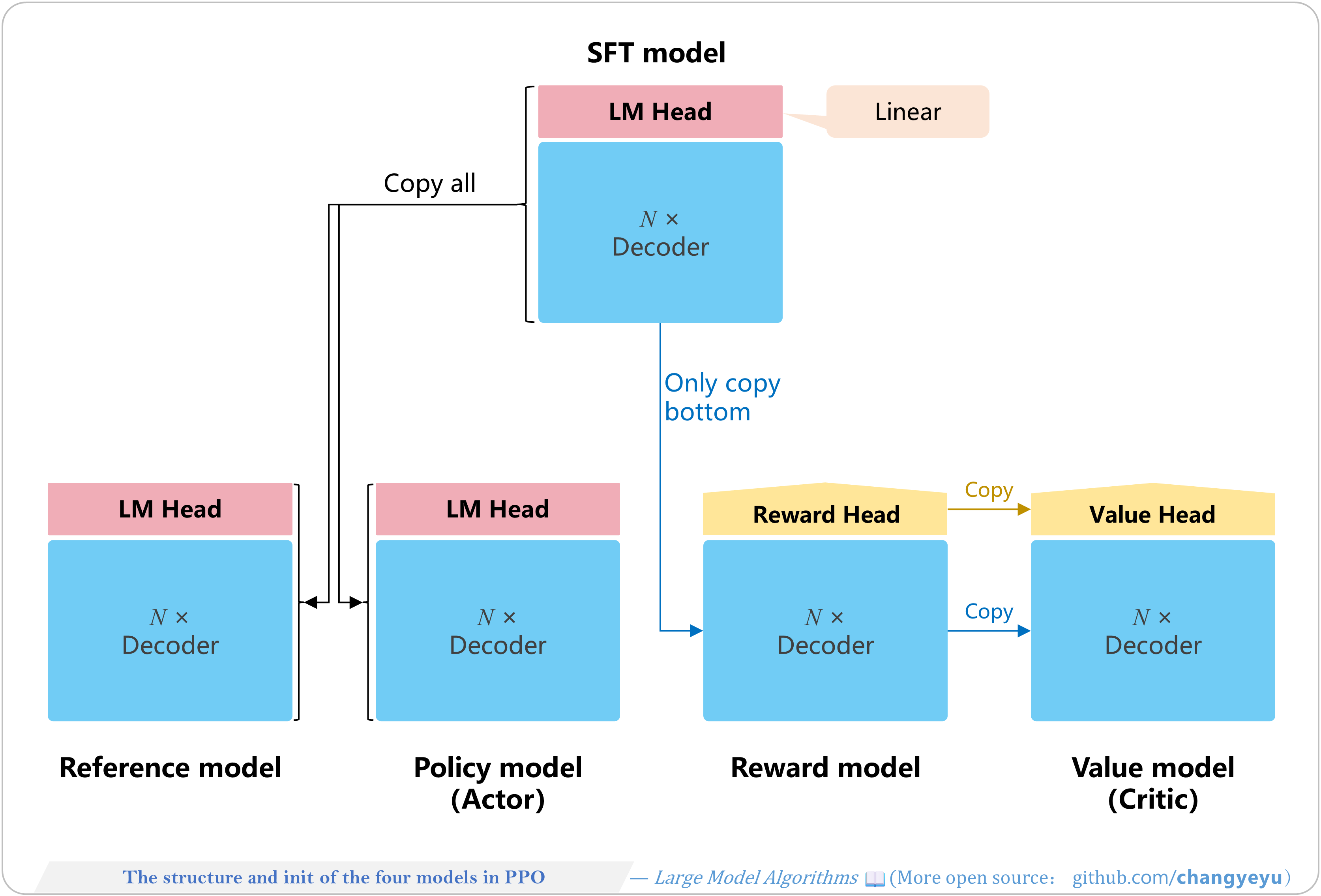
【RLHF and RLAIF】The structure and init of the four models in PPO
- All four share the same N-layer decoder but differ in heads and LoRA modules:
- Policy Model: SFT model + LM head, parameters updated during PPO.
- Reference Model: SFT model + LM head, frozen.
- Reward Model: SFT decoder + Reward head (random init), frozen.
- Value Model: SFT decoder + Value head, updated during PPO.
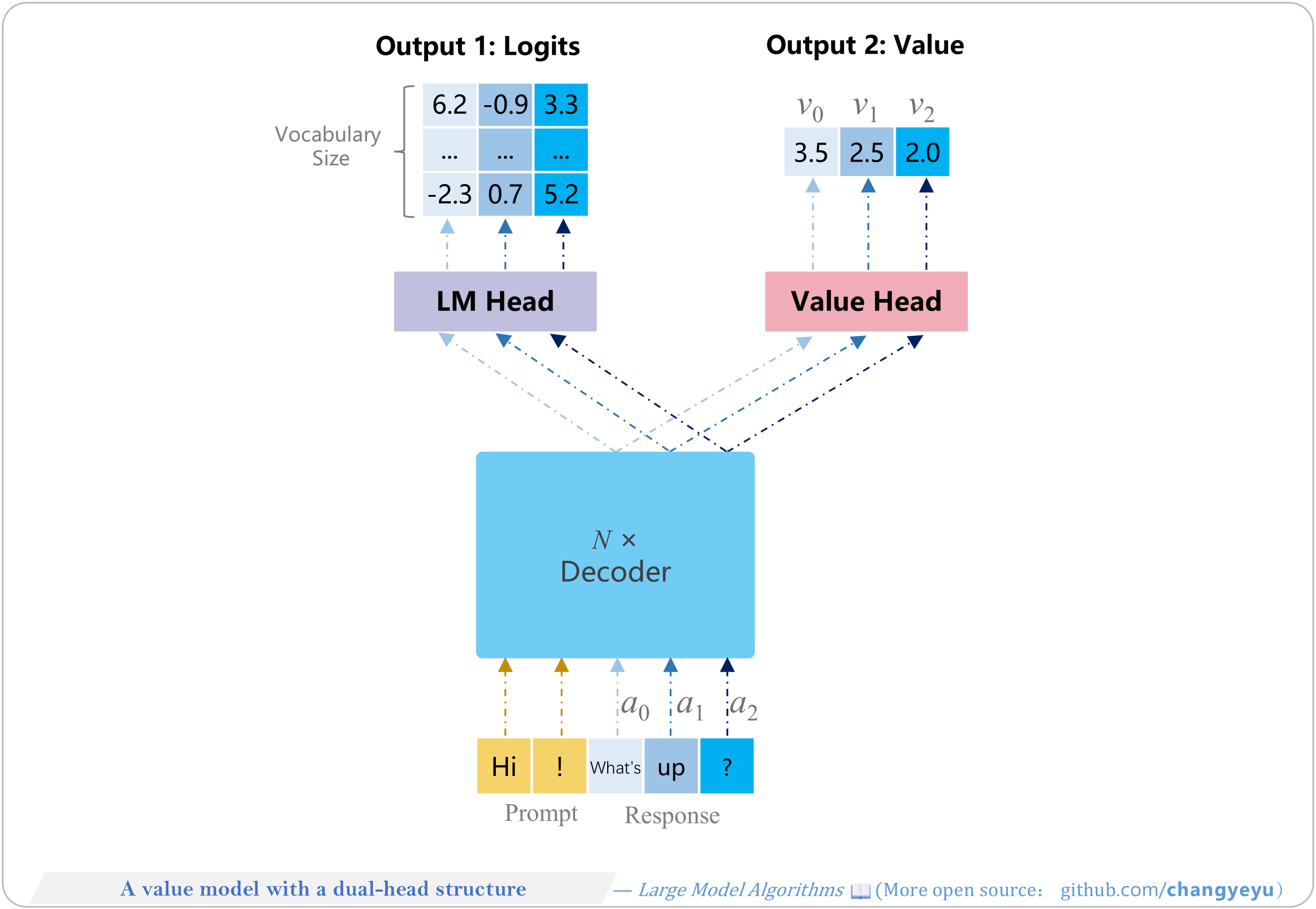
【RLHF and RLAIF】A value model with a dual-head structure
- TRL’s AutoModelForCausalLMWithValueHead uses two heads:
- LM Head outputs logits ([seq_len, vocab_size]).
- Value Head outputs values ([seq_len, 1]).
- Shared decoder pass reduces compute and memory.

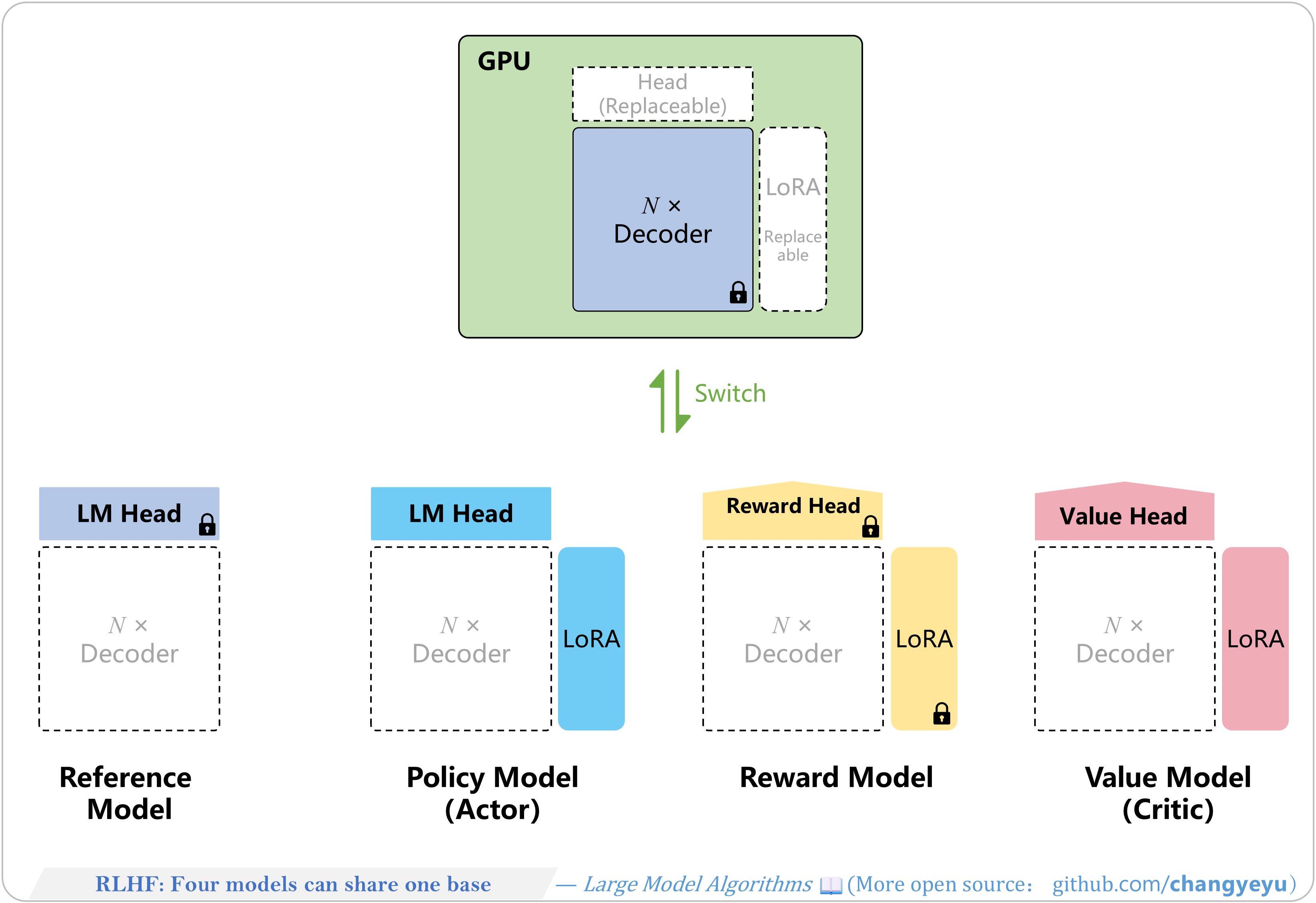
【RLHF and RLAIF】Four models can share one base in RLHF
- By sharing a frozen decoder and using separate LoRA modules for each head, RLHF minimizes GPU memory. LoRA modules and heads can be dynamically loaded or swapped.
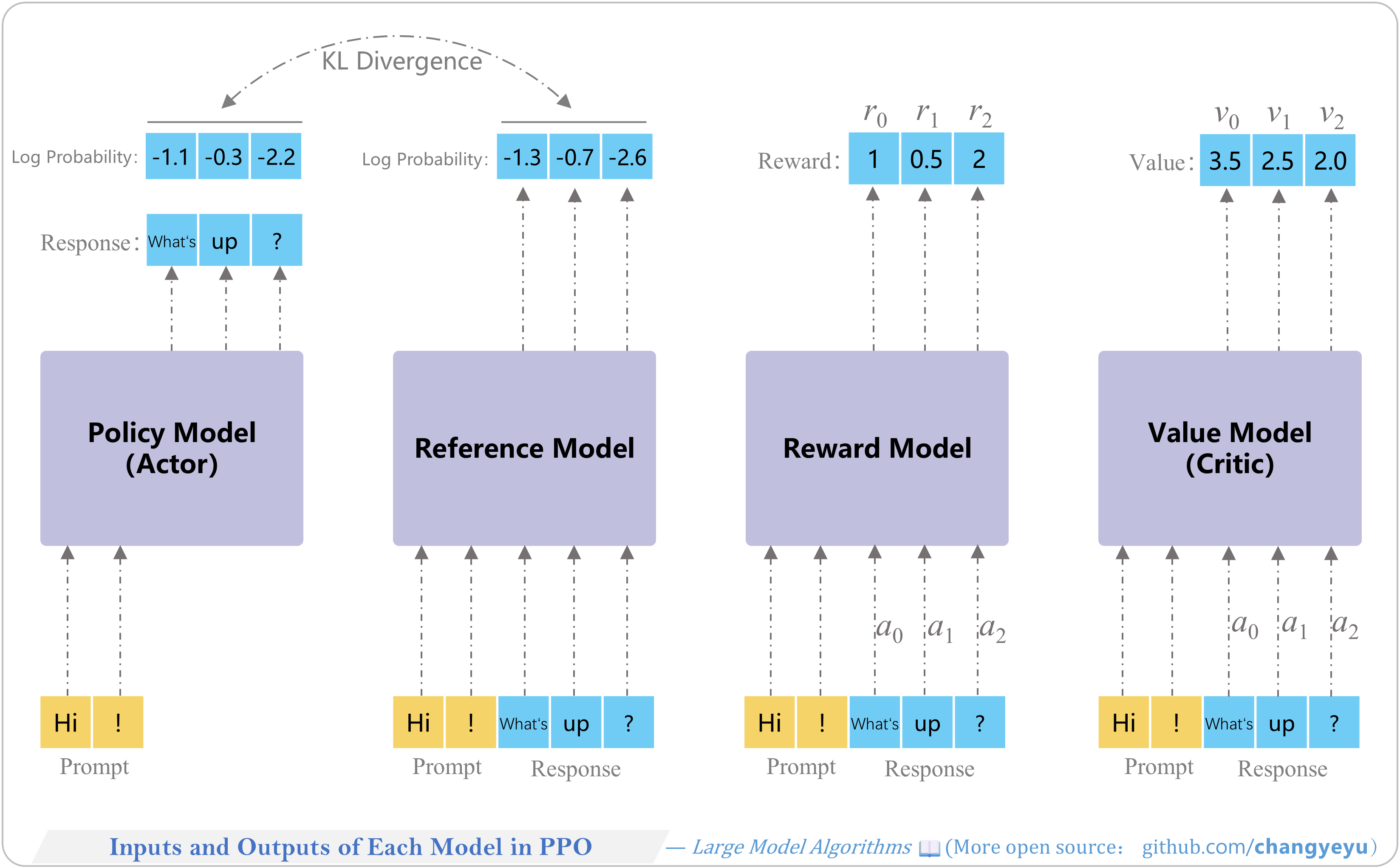
【RLHF and RLAIF】Inputs and Outputs of Each Model in PPO
PPO training models’ inputs and outputs
| Model | Input | Output |
|---|---|---|
| Policy Model | Prompt (or context) | Response and its log-probs (LogProbs) |
| Reference Model | Prompt (or context) + Response | Response log-probs (LogProbs) |
| Reward Model | Prompt (or context) + Response | Per-token reward scores |
| Value Model | Prompt (or context) + Response | Per-token value estimates |
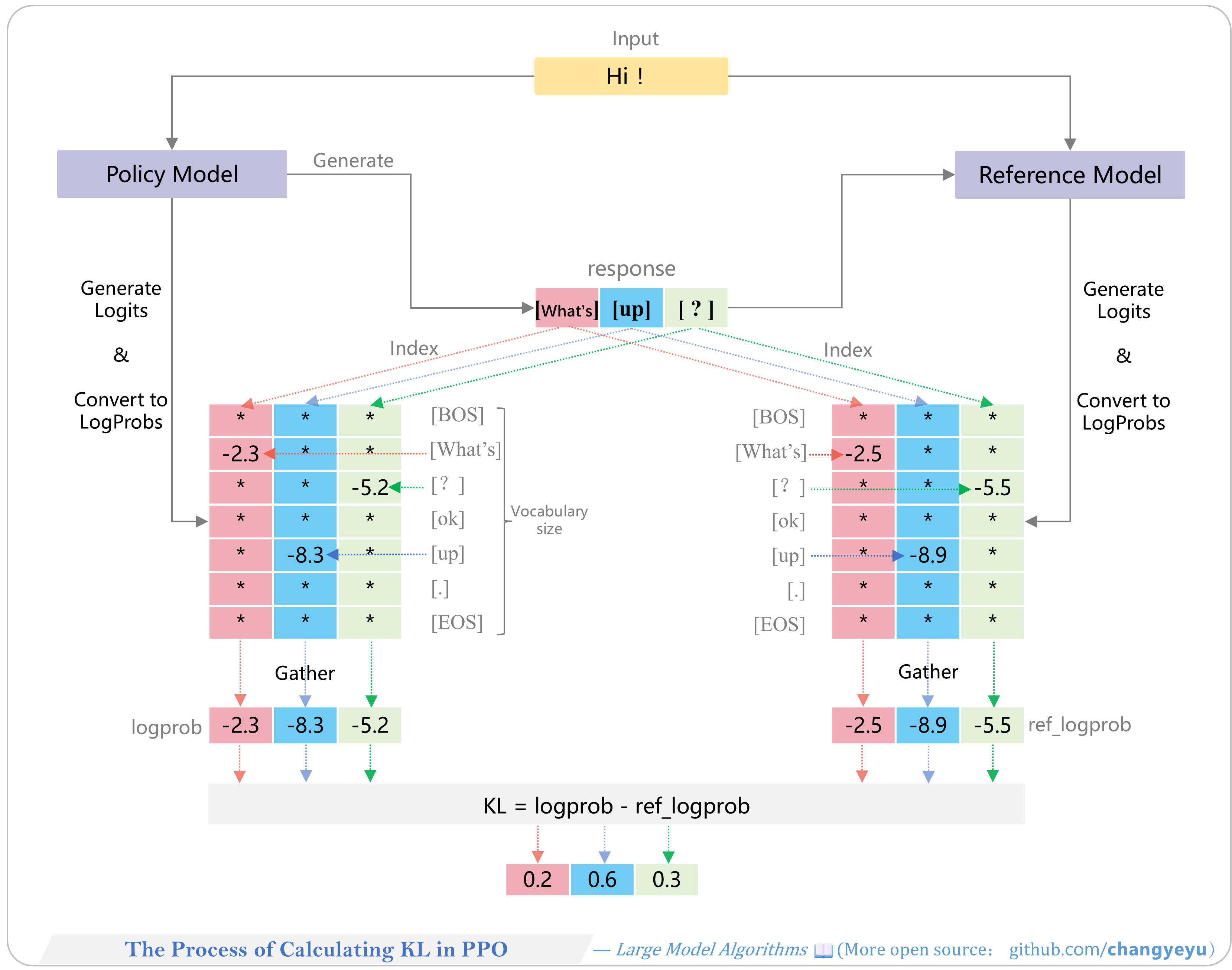
【RLHF and RLAIF】The Process of Calculating KL in PPO
- In frameworks like TRL, KL is penalized during advantage computation: policy and reference logits → log-probs → gather token log-probs → compute per-token KL differences.
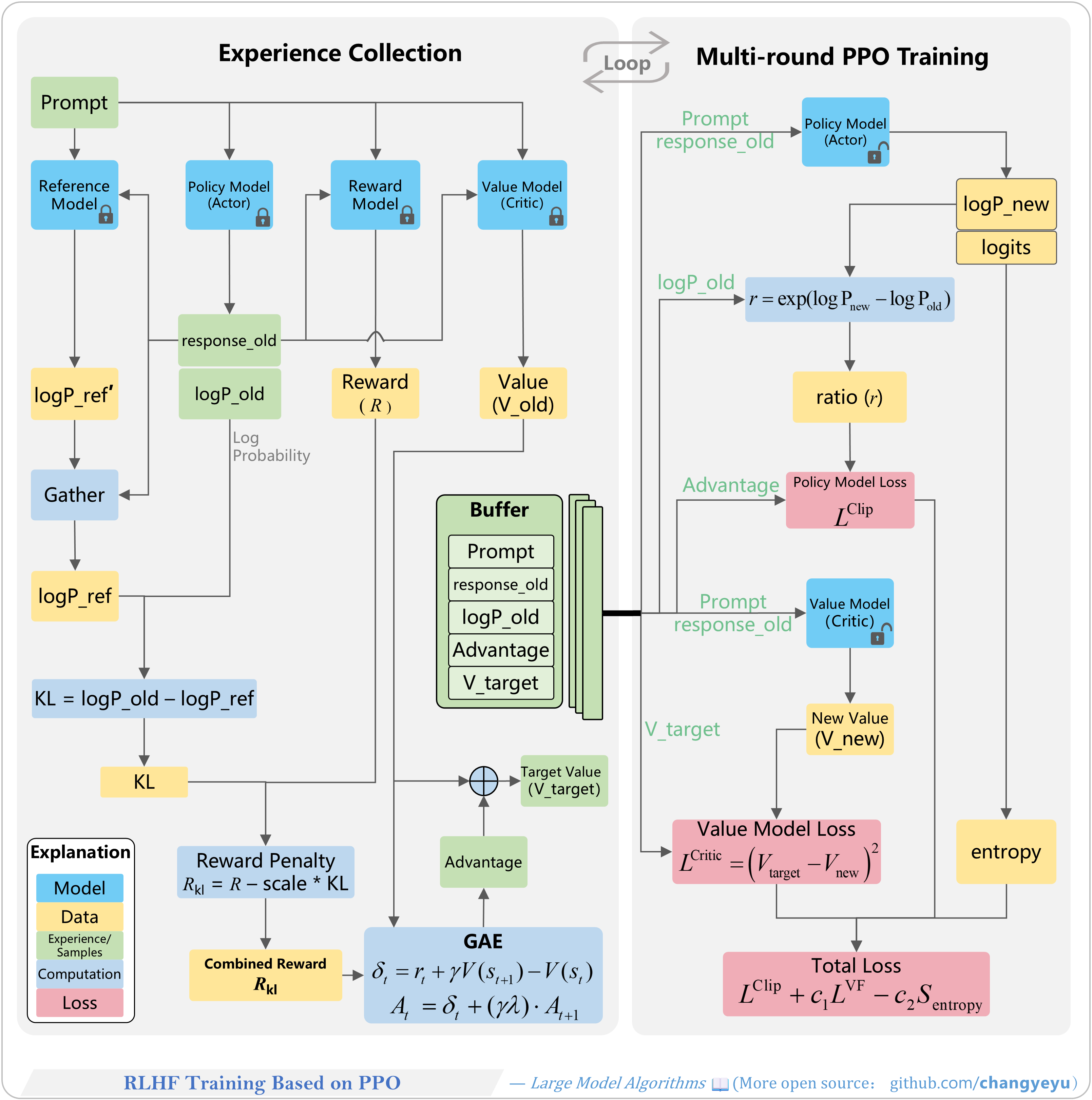
【RLHF and RLAIF】RLHF Training Based on PPO
- The PPO RLHF workflow is split into two halves: experience collection and multi-epoch PPO training, iterating via a replay buffer with old/new model versions.
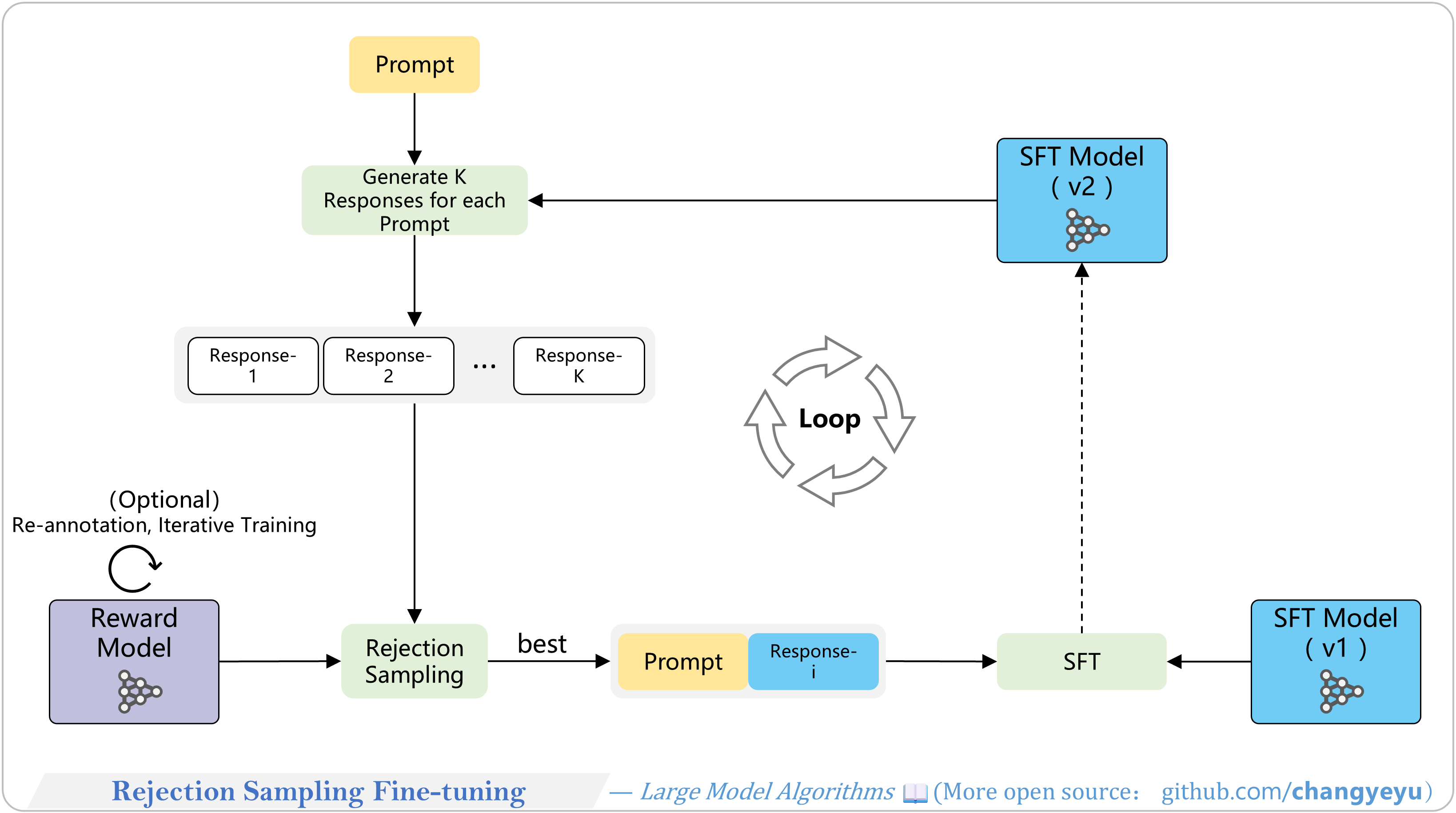
【RLHF and RLAIF】Rejection Sampling Fine-tuning
- Rejection Sampling Fine-Tuning filters out low-quality generated samples, retaining only high-quality ones for further fine-tuning. Used by Anthropic, Meta, etc., and can iterate multiple rounds.
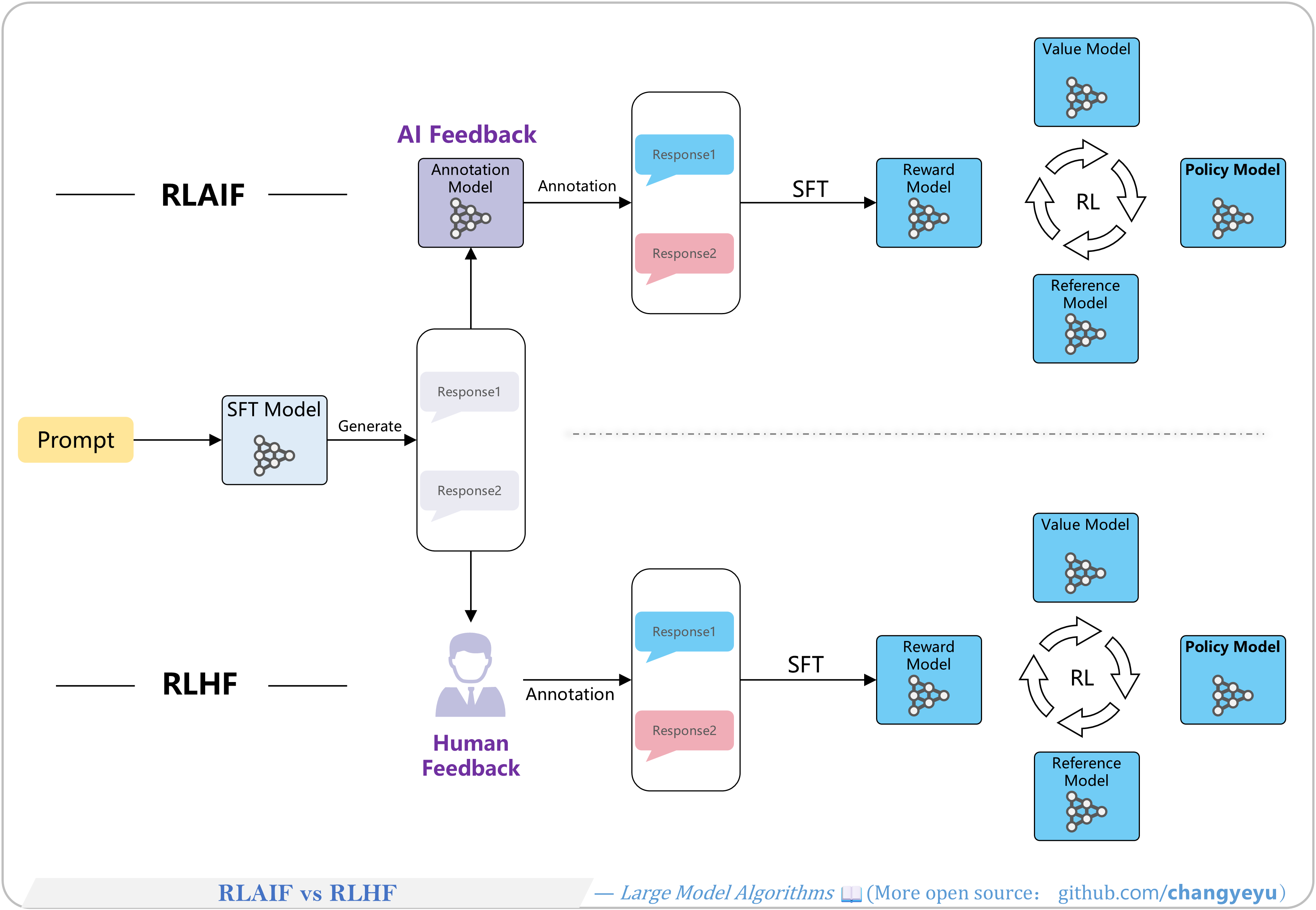
【RLHF and RLAIF】RLAIF vs RLHF
- RLAIF (Reinforcement Learning from AI Feedback) mirrors RLHF but uses AI for preference labeling instead of humans.
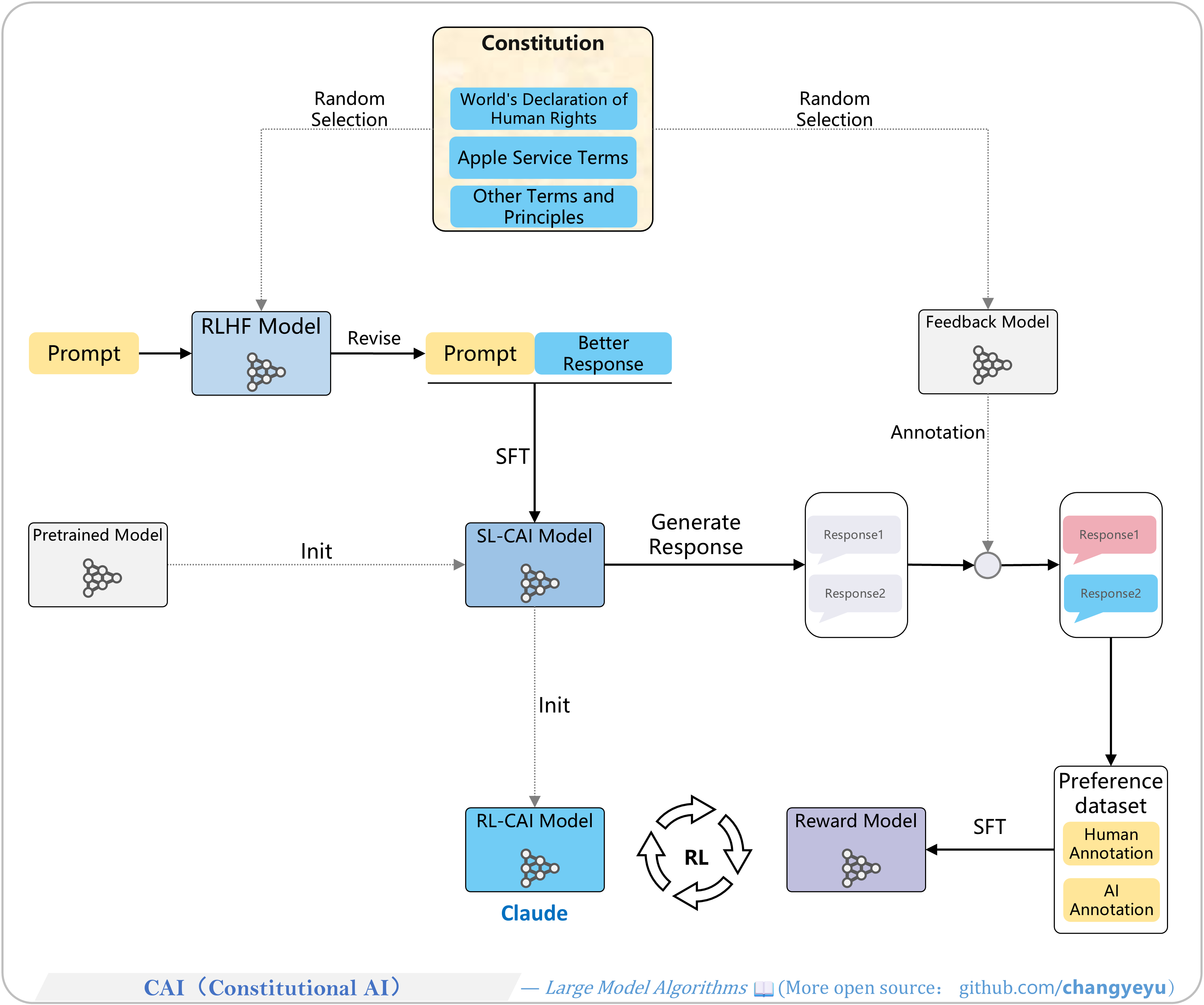
【RLHF and RLAIF】CAI(Constitutional AI)
- Constitutional AI (CAI) by Anthropic (2022) uses a set of constitutional principles:
- Self-critique & revision by a random principle.
- Train SL-CAI on revised + human-labeled data.
- Generate candidates and AI-label via random principle.
- Train reward model on combined labels.
- RL-CAI: optimize target model with PPO and the reward model.
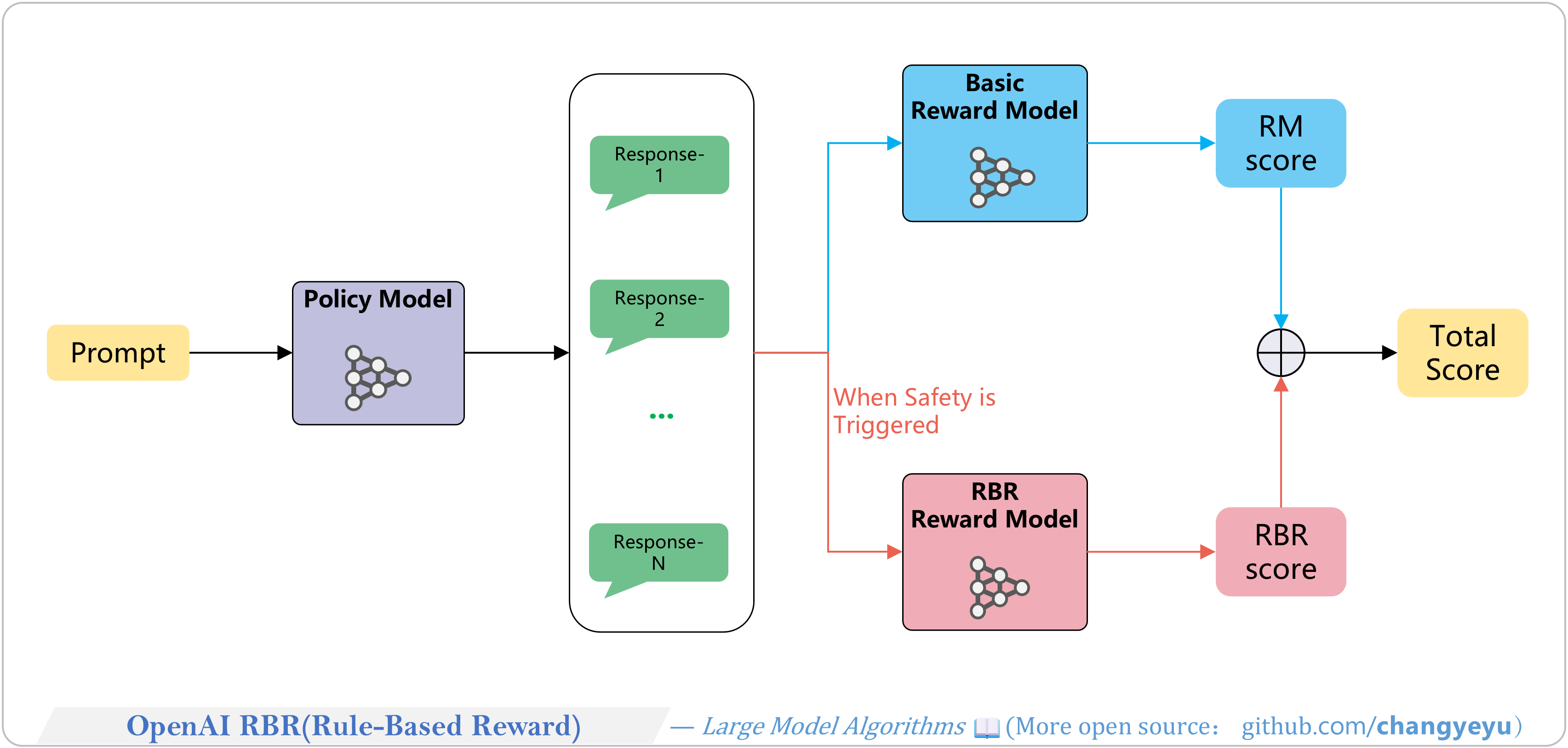
【RLHF and RLAIF】OpenAI RBR(Rule-Based Reward)
- RBR (Rule Based Rewards) by OpenAI (2024) trains a rule-based reward model on human data, integrating AI feedback into RLHF. It is central to GPT-4’s safety system.
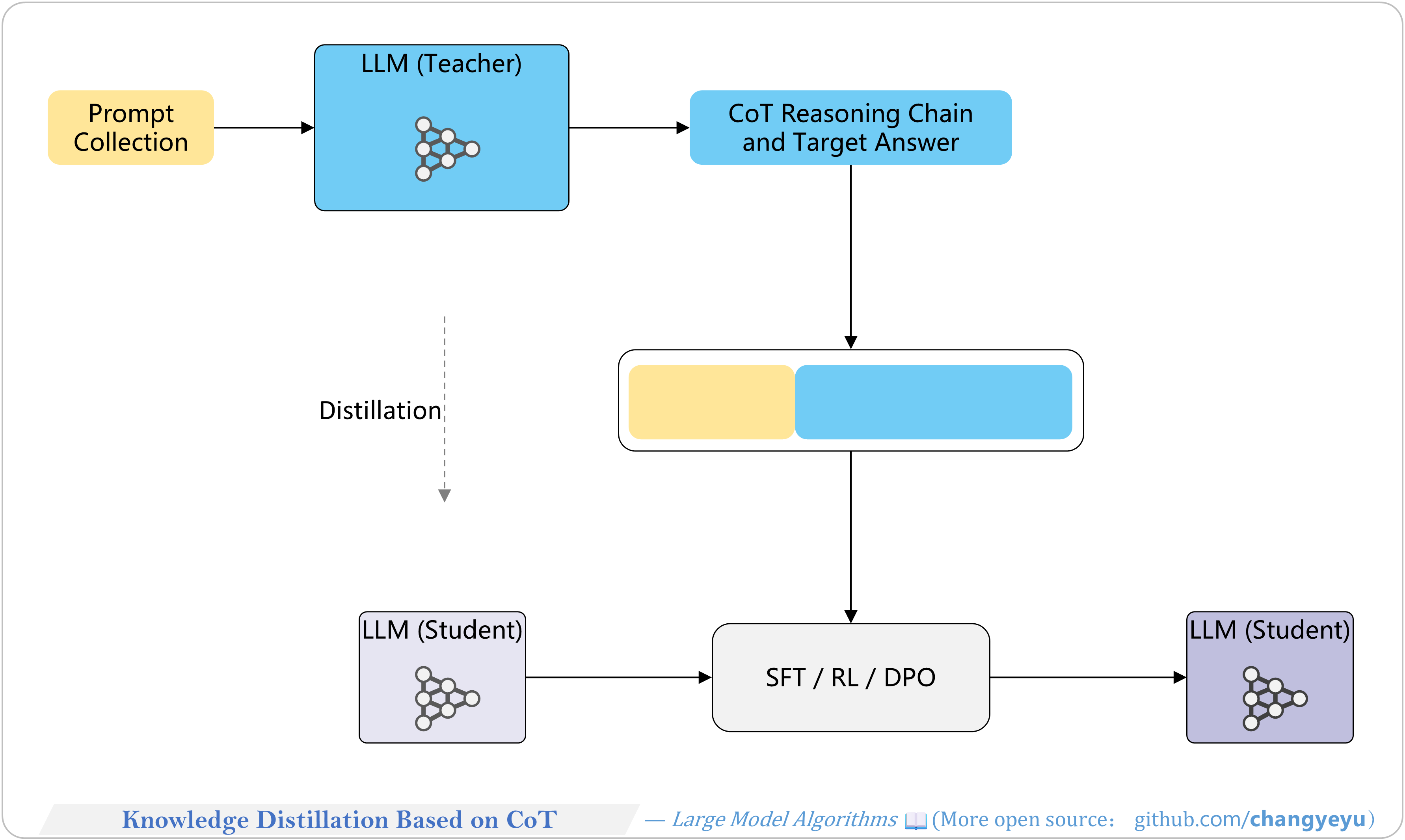
【Reasoning capacity optimization】Knowledge Distillation Based on CoT
- Knowledge Distillation (KD) by Hinton et al. (2015) compresses models by transferring teacher outputs (soft labels) to a student. In reasoning tasks, distill CoT chains and answers from a strong model to a smaller one.
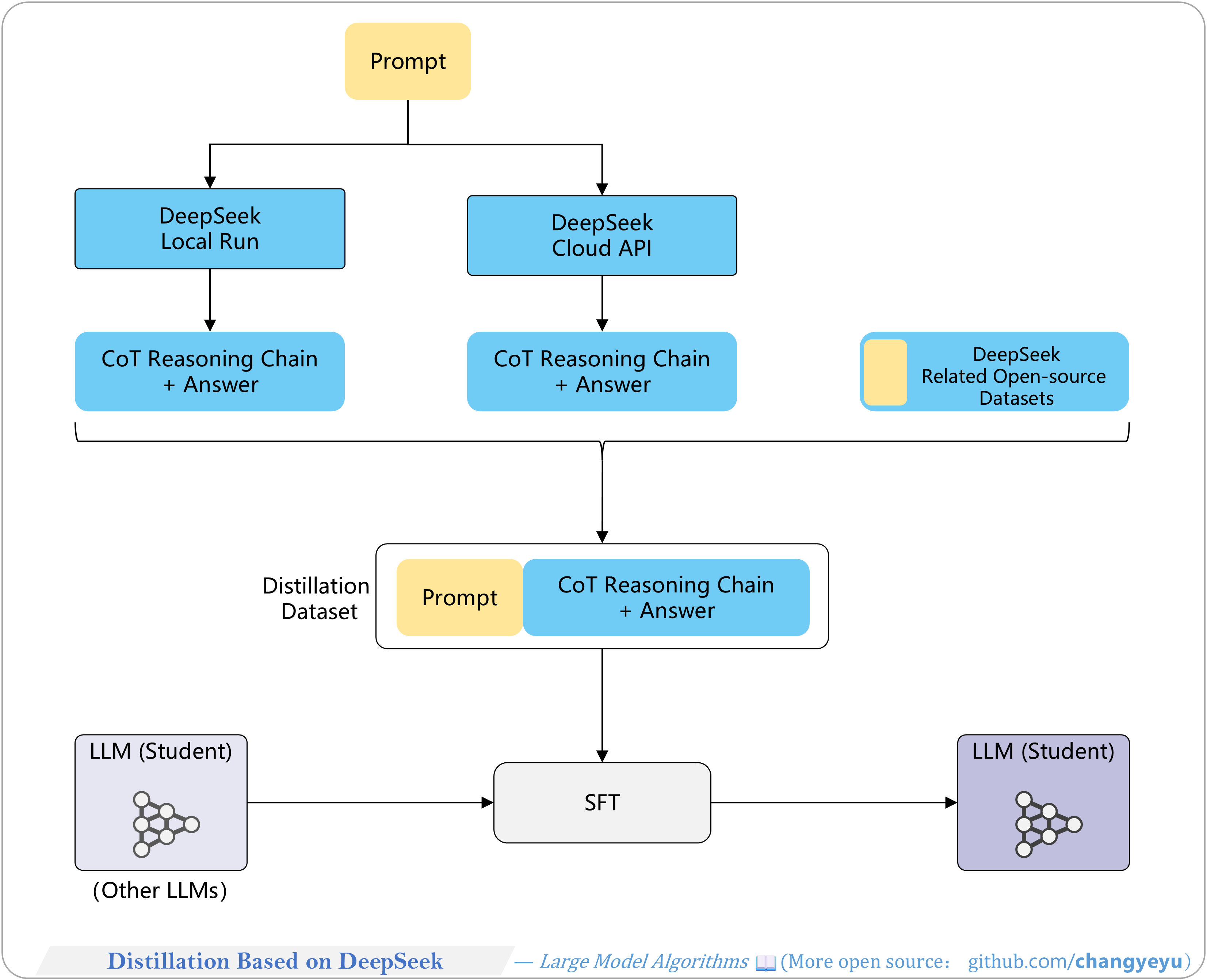
【Reasoning capacity optimization】Distillation Based on DeepSeek
- To reduce model size and deployment overhead, distill capabilities from a strong model (e.g., DeepSeek) into a smaller model.
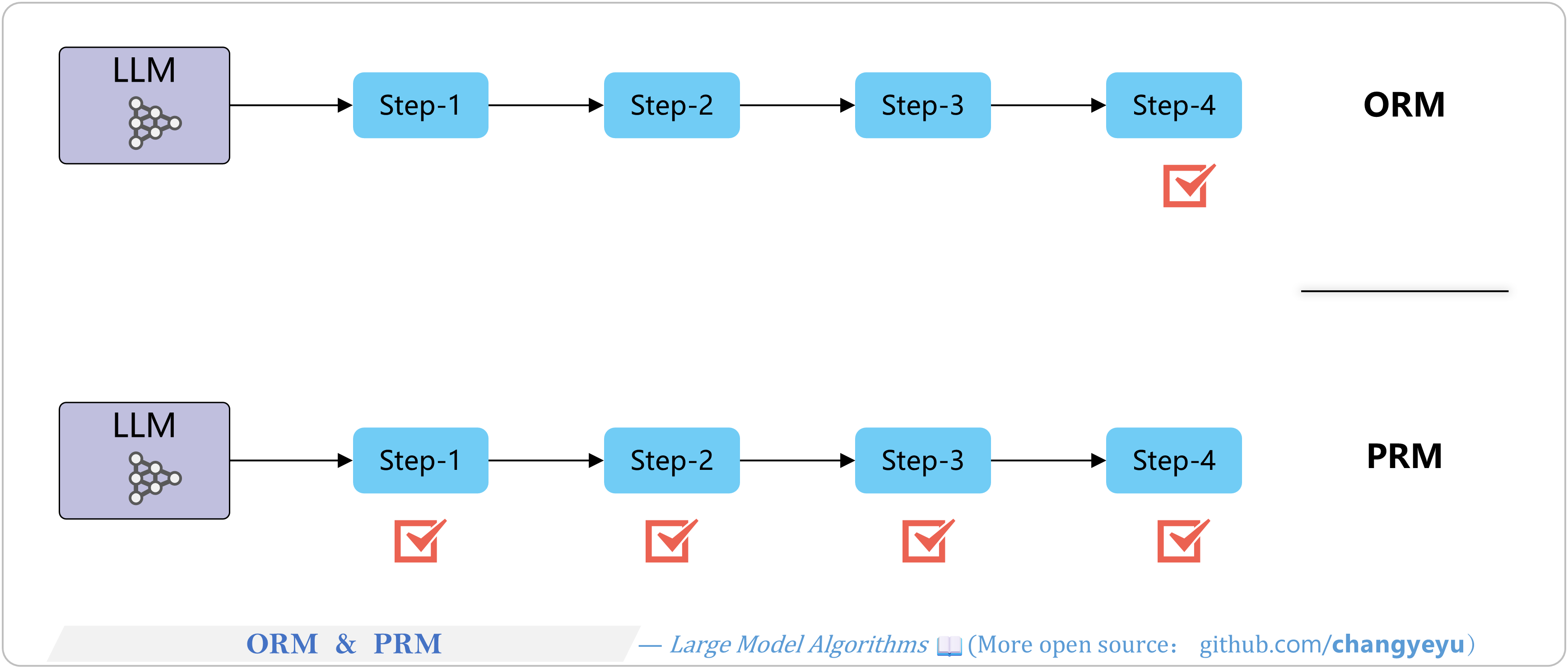
【Reasoning capacity optimization】ORM(Outcome Reward Model) & PRM (Process Reward Model)
- Outcome Reward Model (ORM) scores only the final result.
- Process Reward Model (PRM) scores each intermediate reasoning step for finer feedback.
【Reasoning capacity optimization】Four Key Steps of Each MCTS
- MCTS iterates four key steps: Selection, Expansion, Simulation, Backpropagation.
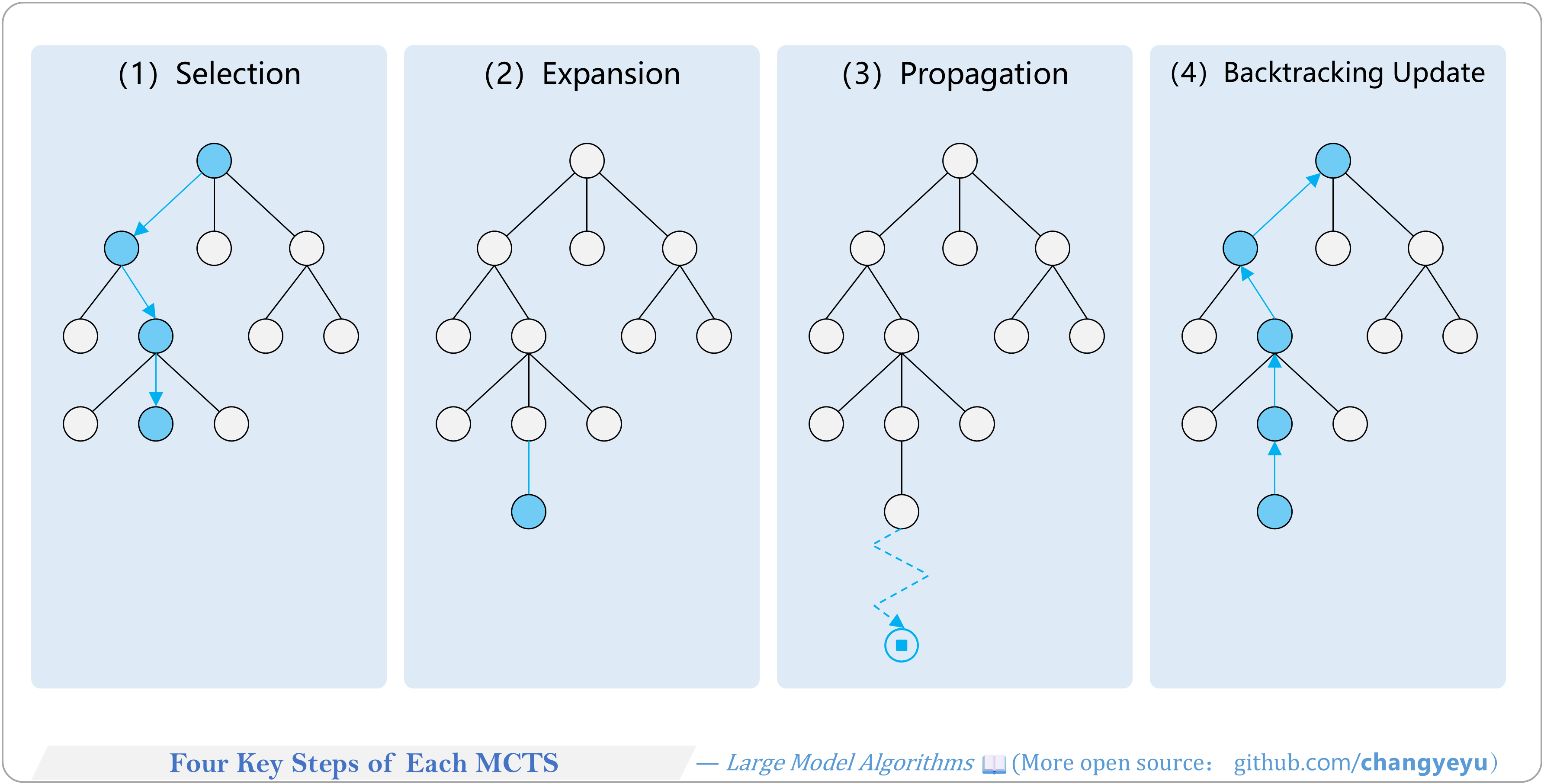
【Reasoning capacity optimization】MCTS
- MCTS repeats these steps to expand and refine the search tree, gradually favoring better paths as simulation count increases.
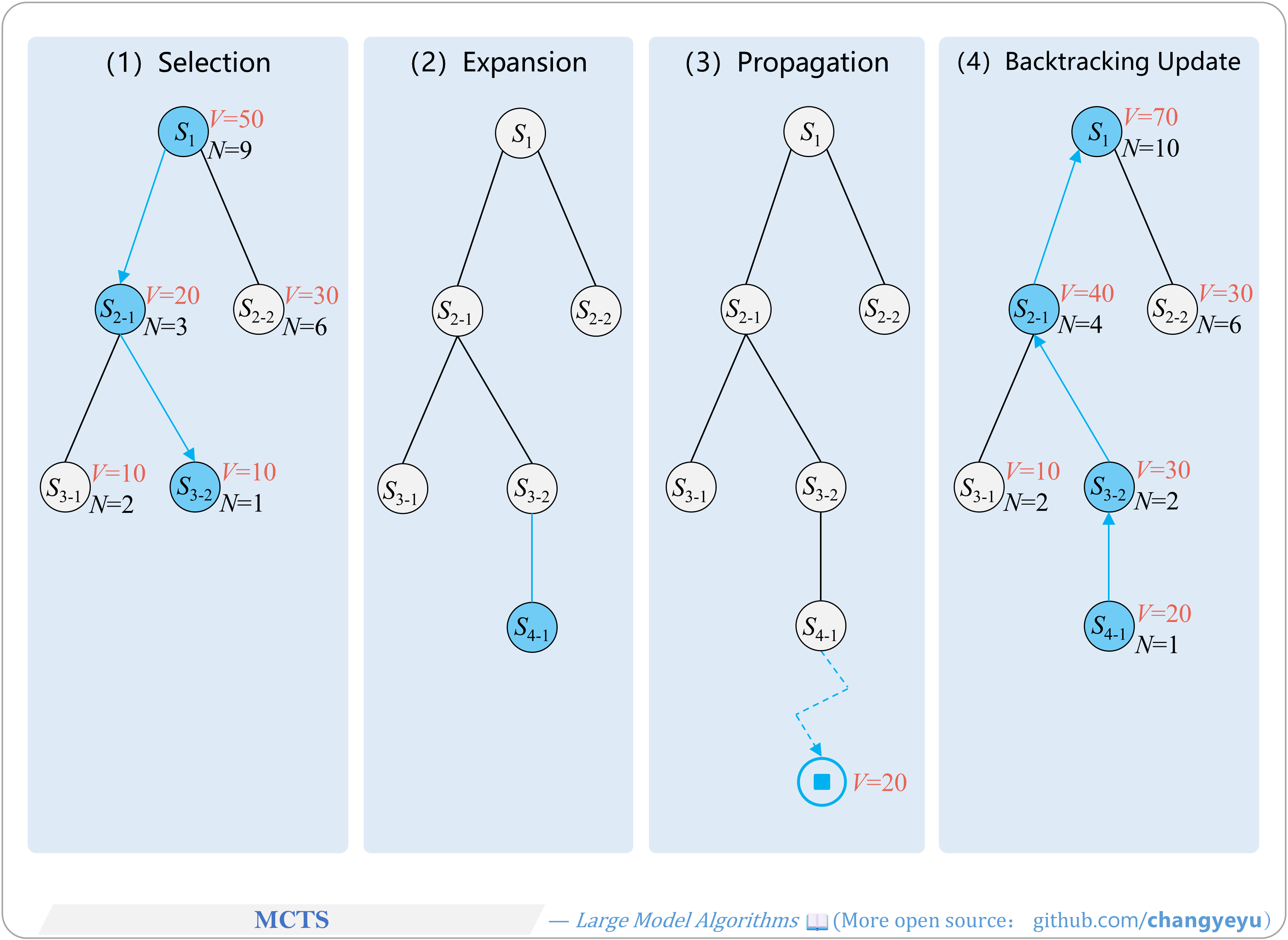
【Reasoning capacity optimization】Search Tree Example in a Linguistic Context
- In language tasks, each tree node represents a sentence or paragraph-level reasoning step.
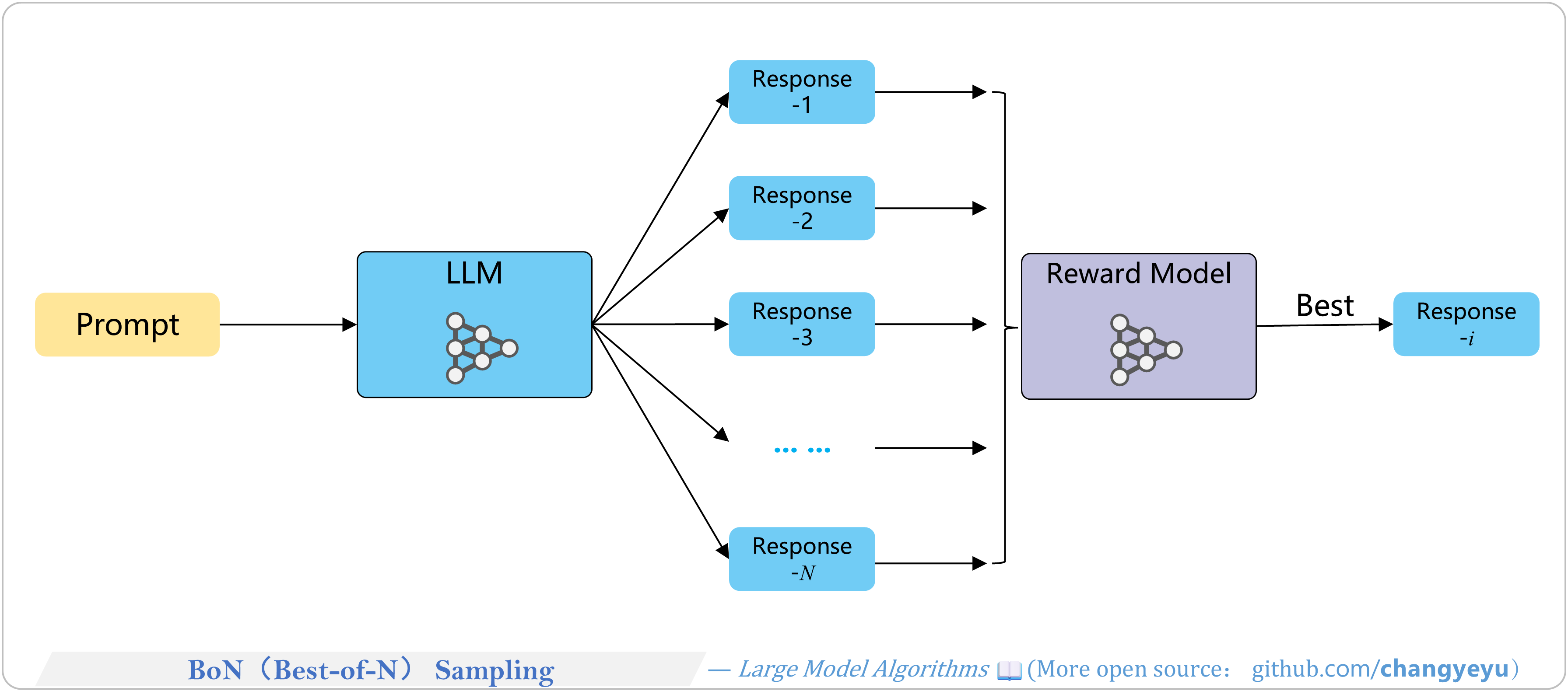
【Reasoning capacity optimization】BoN(Best-of-N) Sampling
- Best-of-N sampling: generate N candidates and select the highest-scoring one.
- Run multiple reasoning paths, then choose the most frequent final answer.
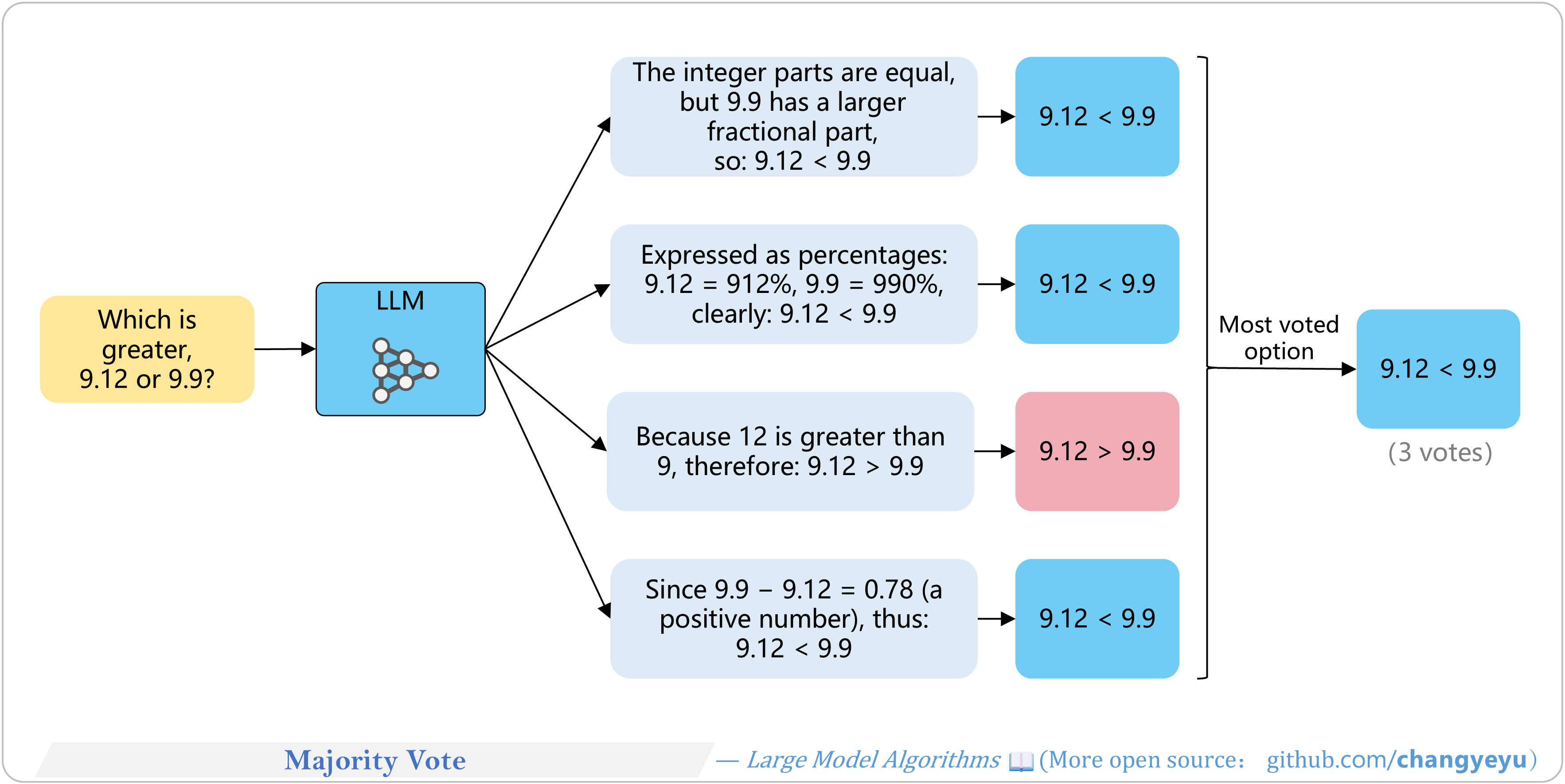
【Reasoning capacity optimization】Majority Vote
- Run multiple reasoning paths, then choose the most frequent final answer.
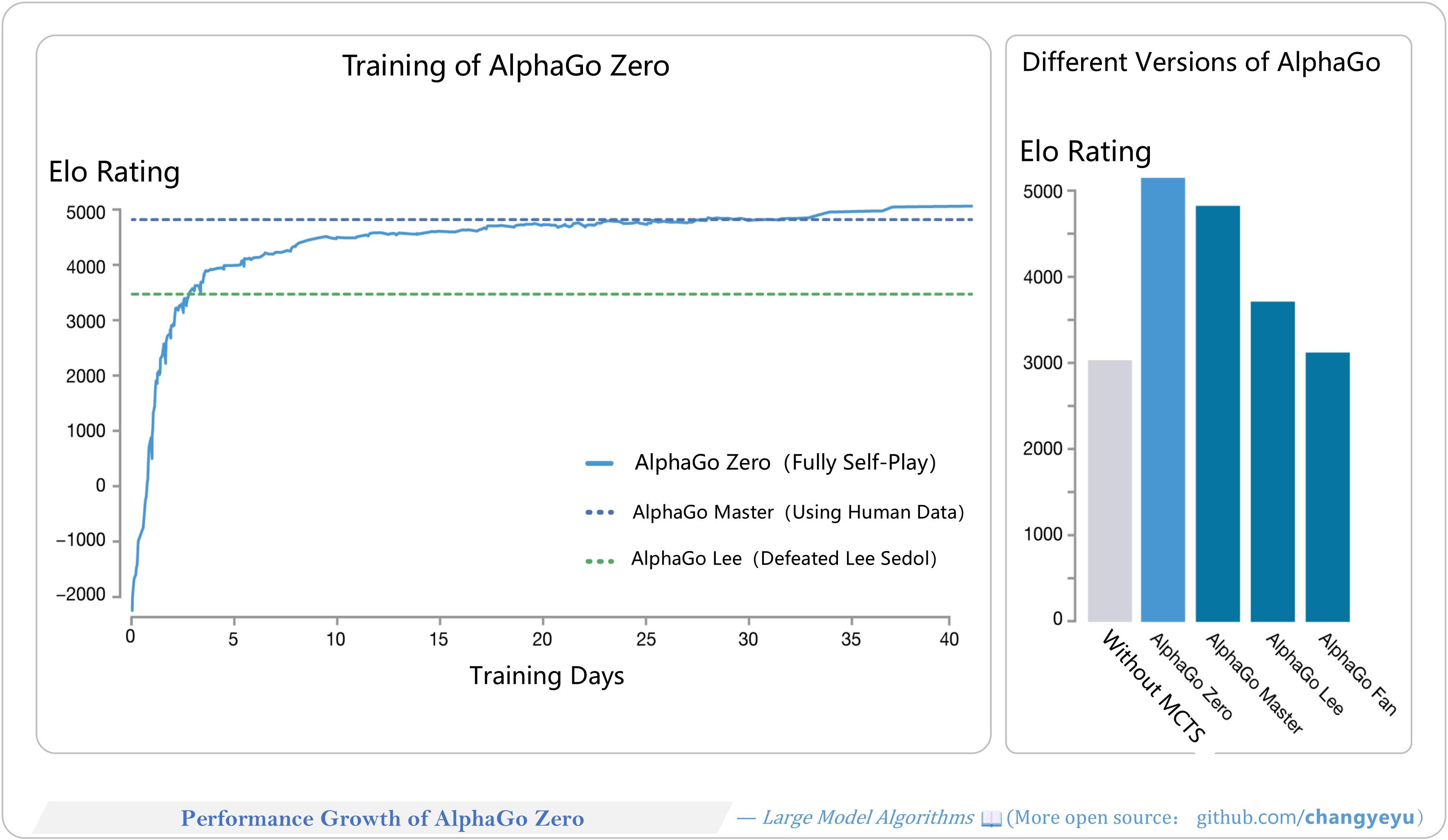
【Reasoning capacity optimization】Performance Growth of AlphaGo Zero [179]
- AlphaGo Zero achieved an Elo of 5185 with MCTS; without MCTS pre-search, its Elo was only 3055, highlighting search’s impact.
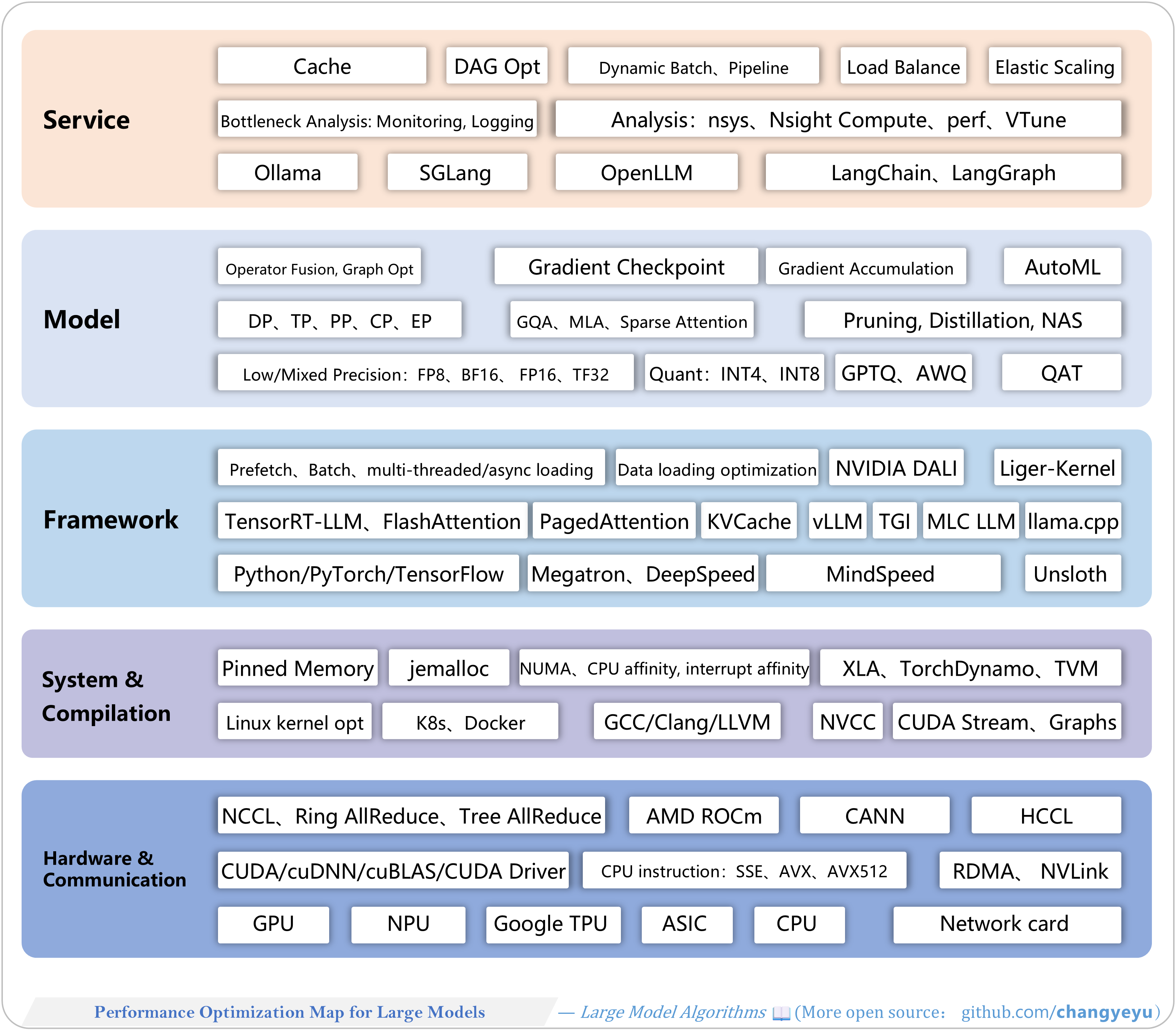
【LLM basics extended】Performance Optimization Map for Large Models
- The optimization map shows five levels—service, model, framework, compiler, hardware/communication—for training and inference.
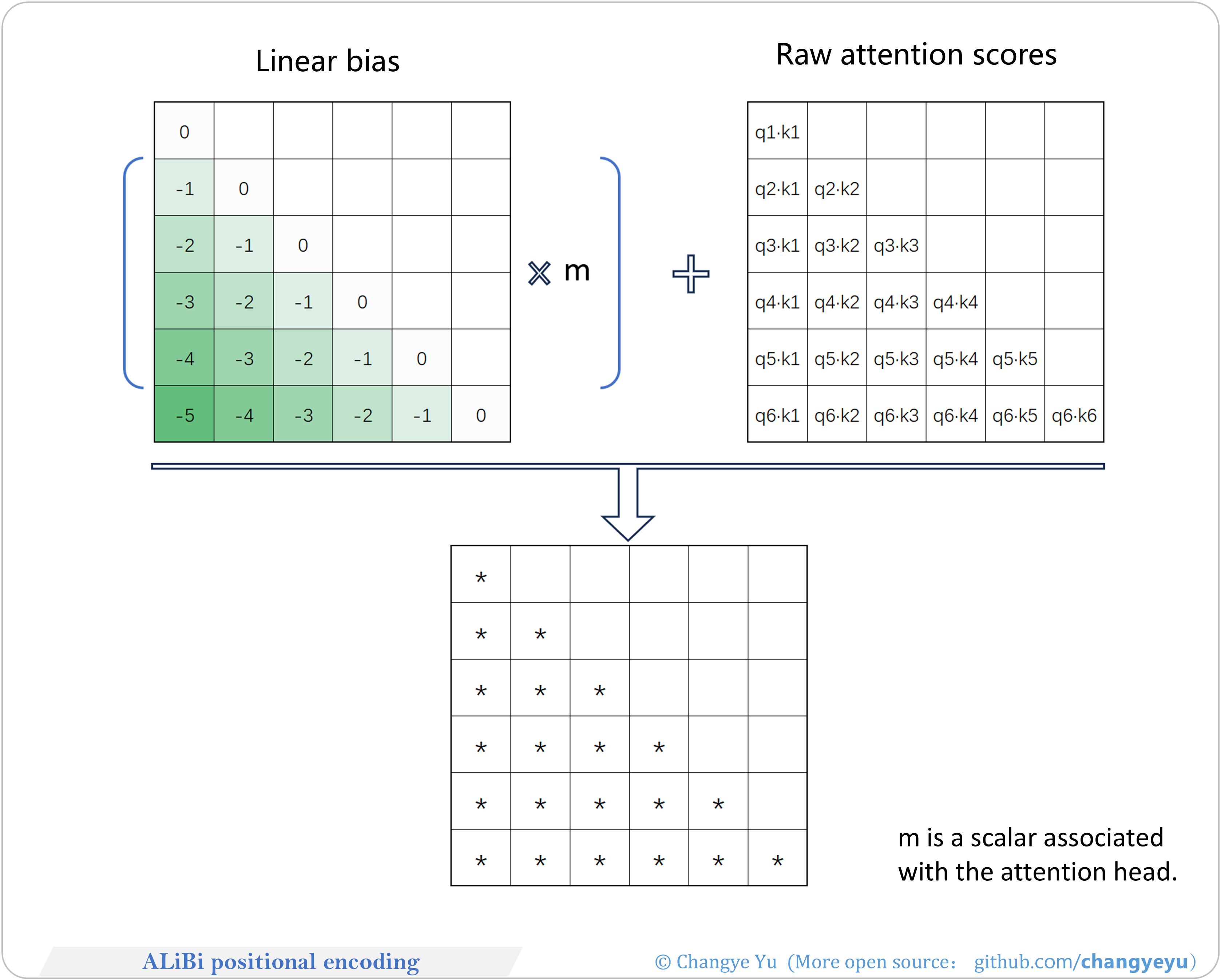
【LLM basics extended】ALiBi positional encoding
- RoPE is mainstream; ALiBi is being phased out.
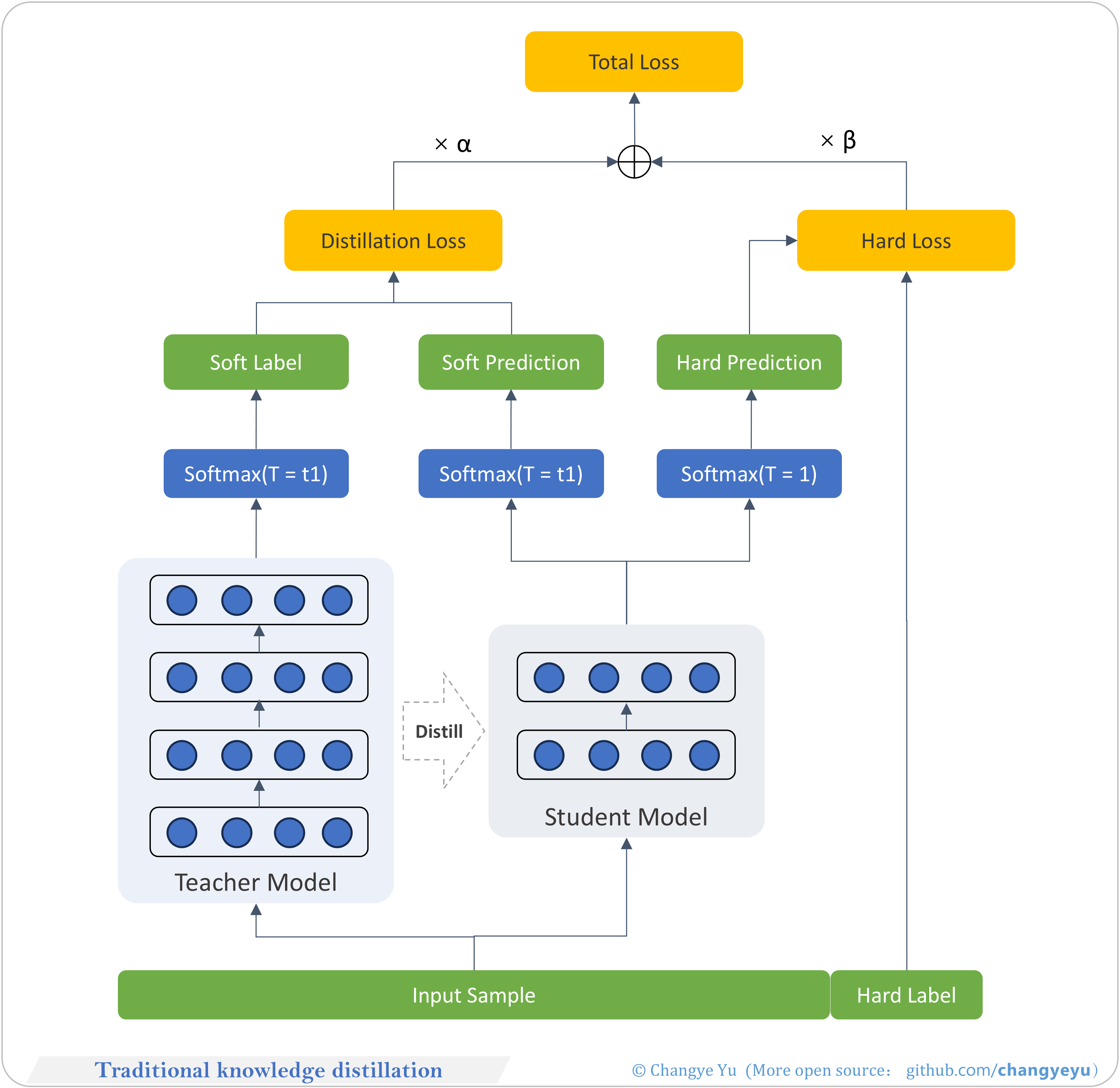
【LLM basics extended】Traditional knowledge distillation
- Knowledge Distillation: transfer teacher soft labels to a student for compression and faster inference. Introduced by Hinton in “Distilling the Knowledge in a Neural Network.”
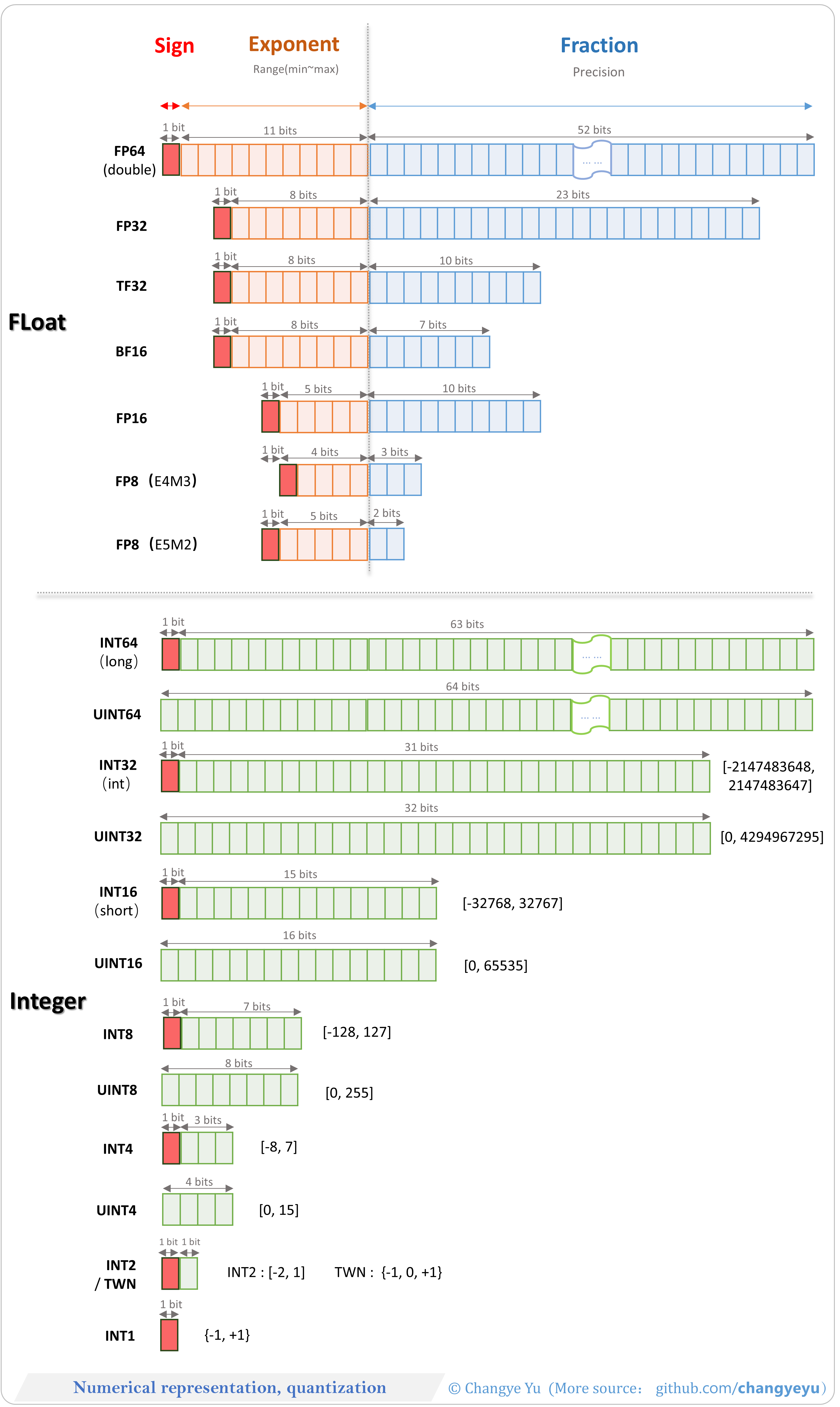
【LLM basics extended】Numerical representation, quantization
| Type | Total Bits | Sign Bits | Exponent Bits | Mantissa/Integer Bits |
|---|---|---|---|---|
| FP64 | 64 | 1 | 11 | 52 (mantissa) |
| FP32 | 32 | 1 | 8 | 23 (mantissa) |
| TF32 | 19 | 1 | 8 | 10 (mantissa) |
| BF16 | 16 | 1 | 8 | 7 (mantissa) |
| FP16 | 16 | 1 | 5 | 10 (mantissa) |
| INT64 | 64 | 1 | – | 63 (integer) |
| INT32 | 32 | 1 | – | 31 (integer) |
| INT8 | 8 | 1 | – | 7 (integer) |
| UINT8 | 8 | 0 | – | 8 (integer) |
| INT4 | 4 | 1 | – | 3 (integer) |
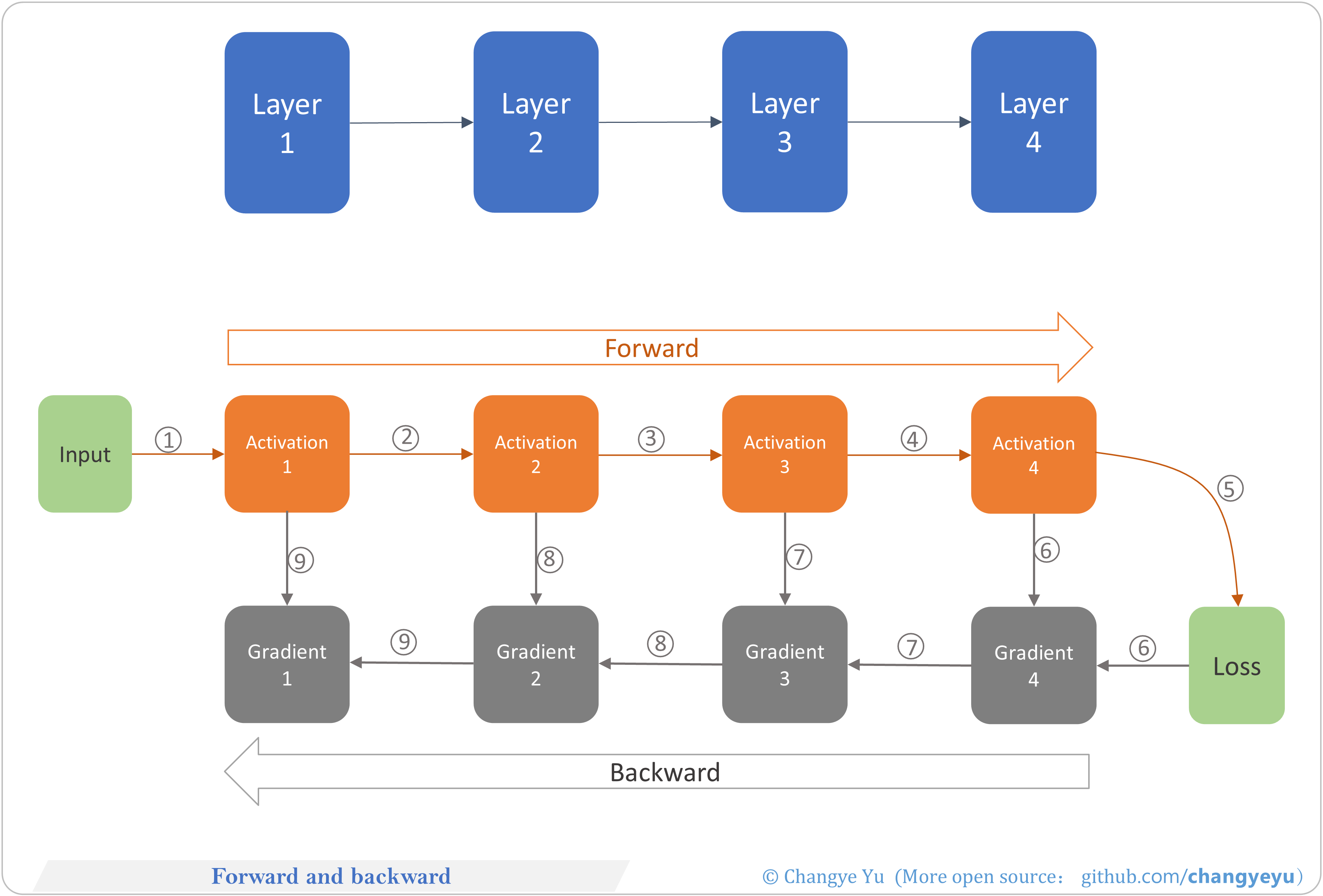
【LLM basics extended】Forward and backward
- Forward Propagation: inputs pass through layers (1–4), caching activations.
- Backward Propagation: compute gradients from loss back through layers using cached activations.
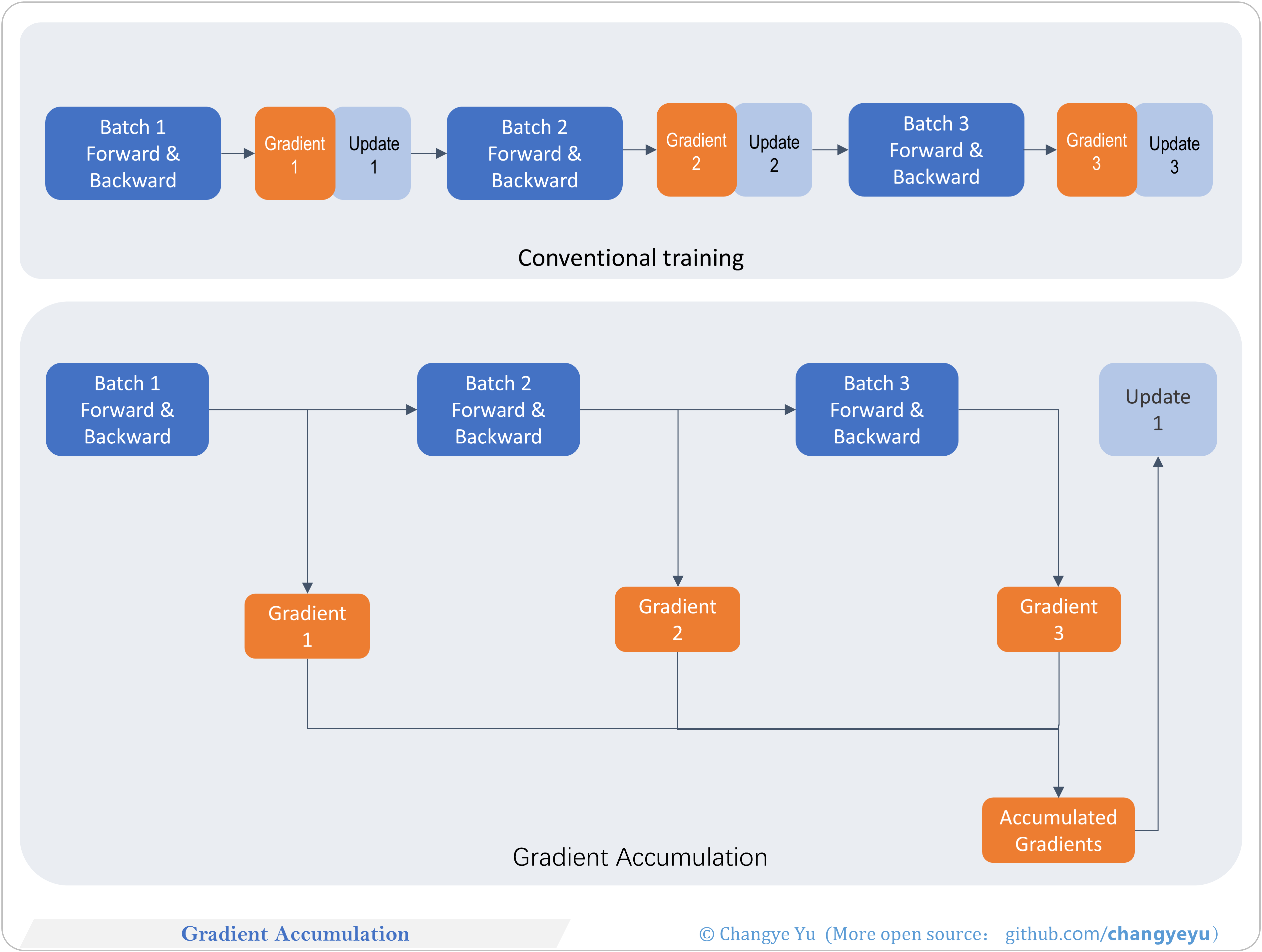
【LLM basics extended】Gradient Accumulation
- Standard: each batch runs forward & backward immediately, updating parameters frequently with low memory usage.
- Accumulation: accumulate gradients over several batches before updating, simulating a larger batch size.

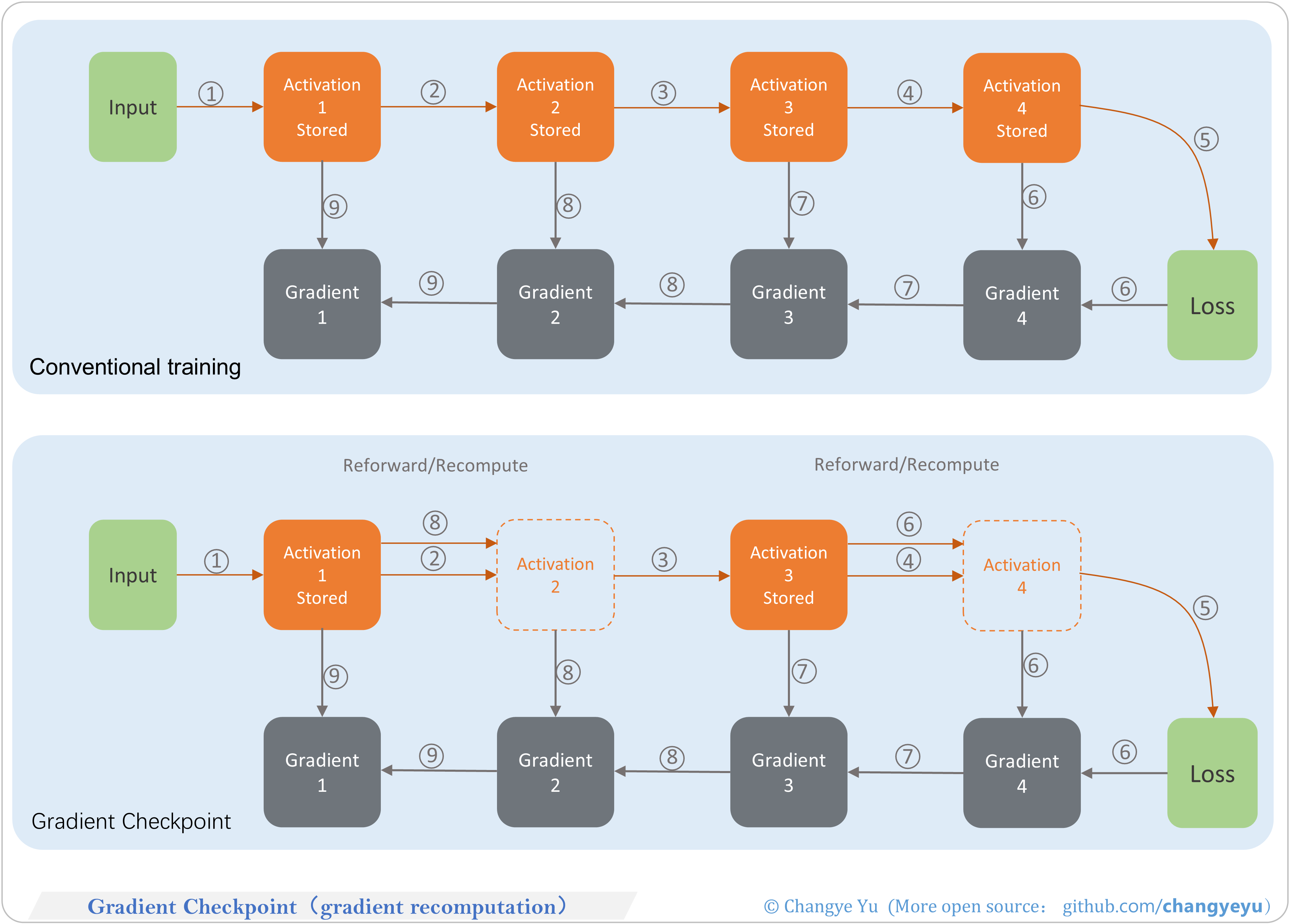
【LLM basics extended】Gradient Checkpoint(gradient recomputation)
- Standard: store all activations for backward, high memory cost.
- Checkpointing: save only key activations, recompute others during backward to save memory at the expense of compute.
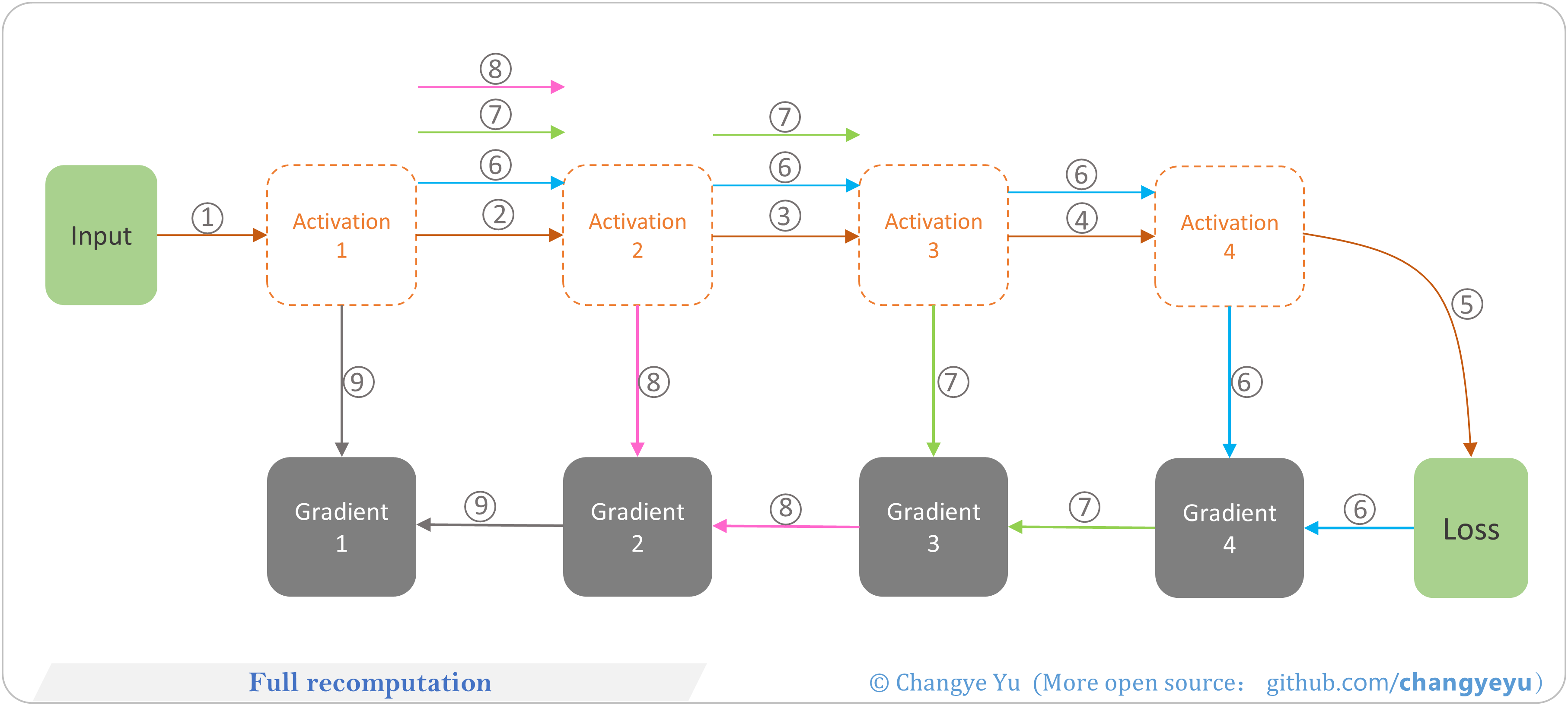
【LLM basics extended】Full recomputation
- Full Recomputation: store no activations, recompute the forward pass during backward propagation. Minimizes memory usage, increases compute time.
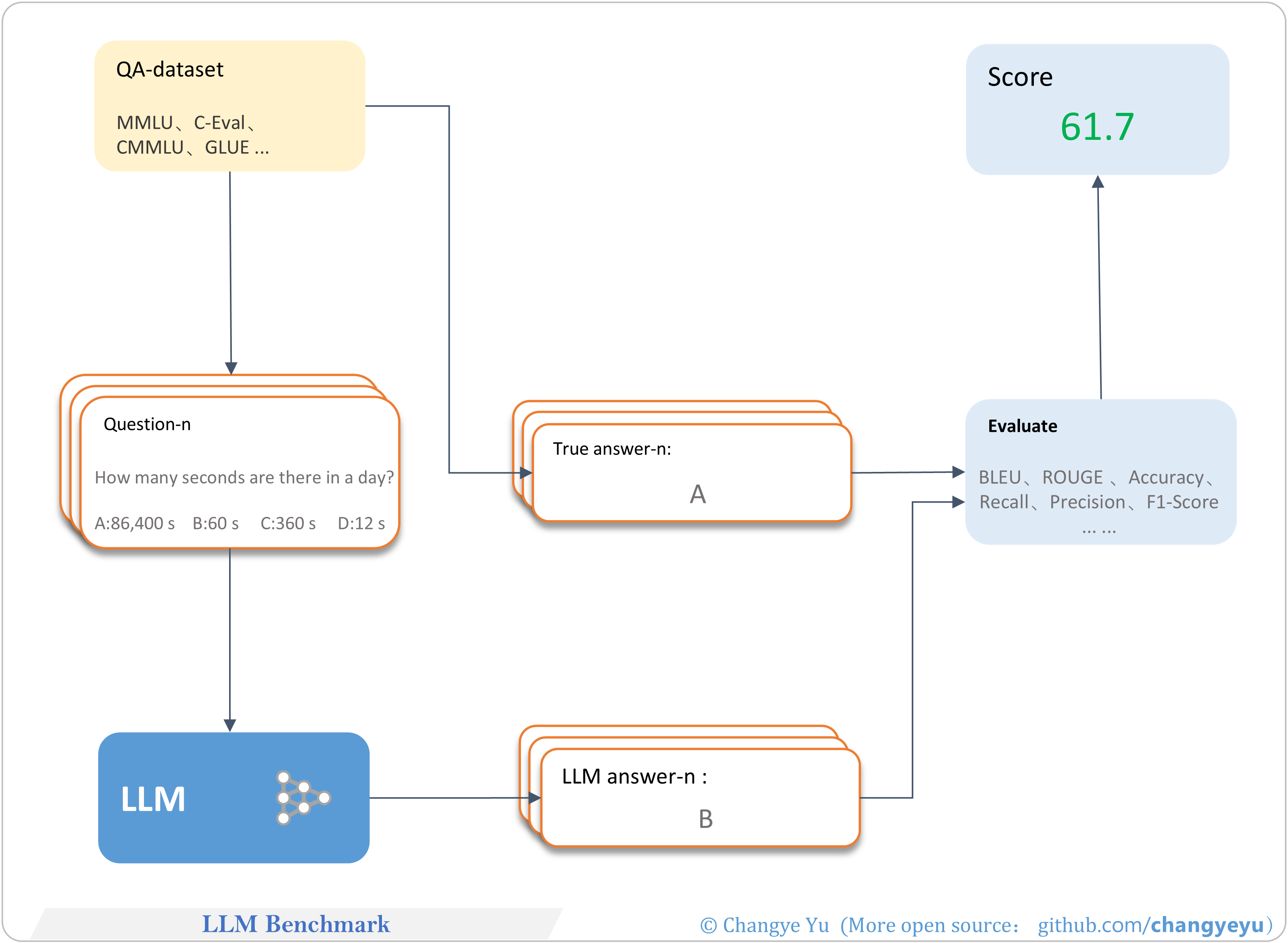
【LLM basics extended】LLM Benchmark
- LLM benchmarks (e.g., MMLU, C-eval) follow similar evaluation protocols as illustrated.
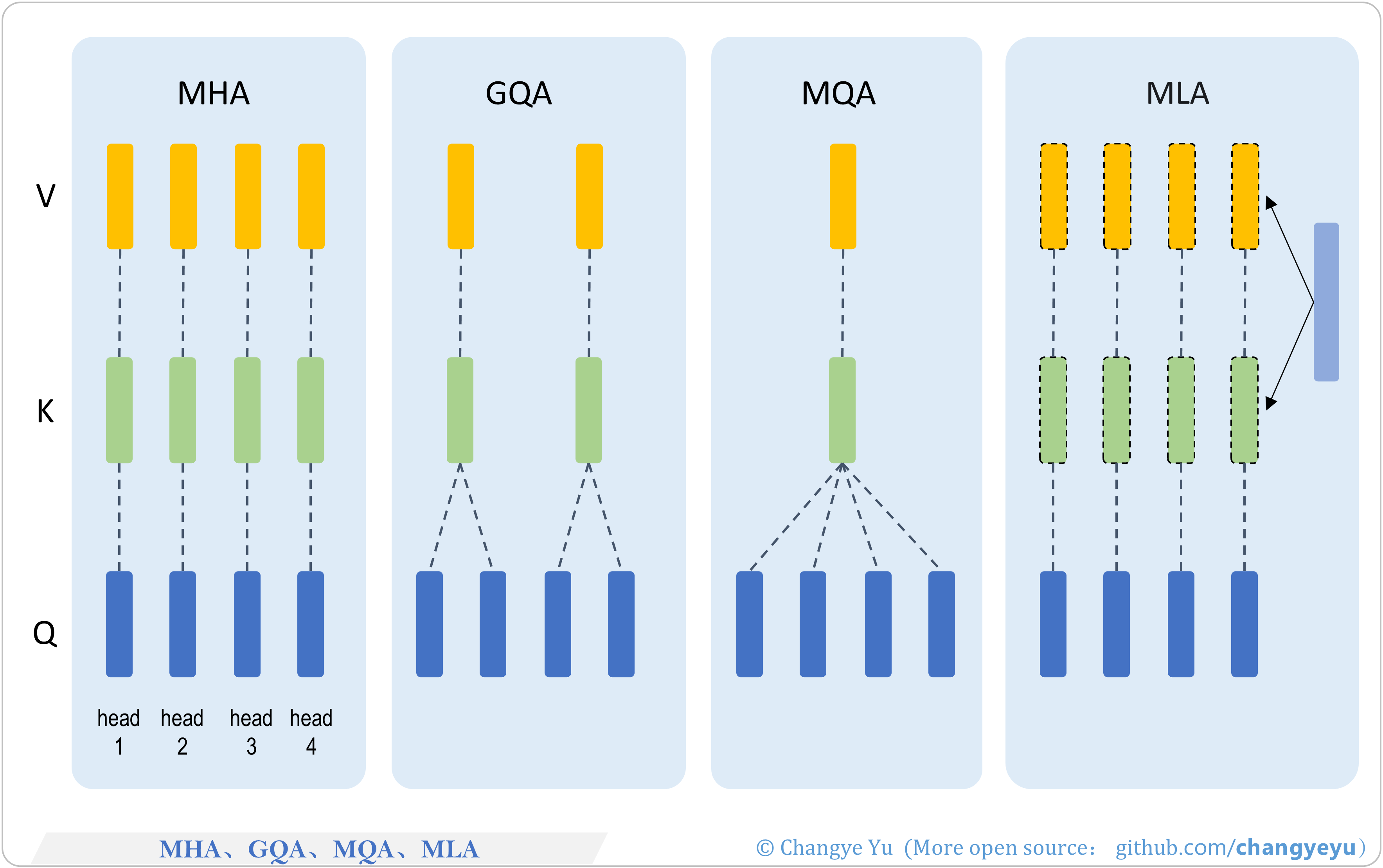
【LLM basics extended】MHA、GQA、MQA、MLA
- MHA: Multi-Head Attention
- GQA: General Question Answering
- MQA: Multimodal QA
- MLA: Multimodal Language and Action (various naming conventions)

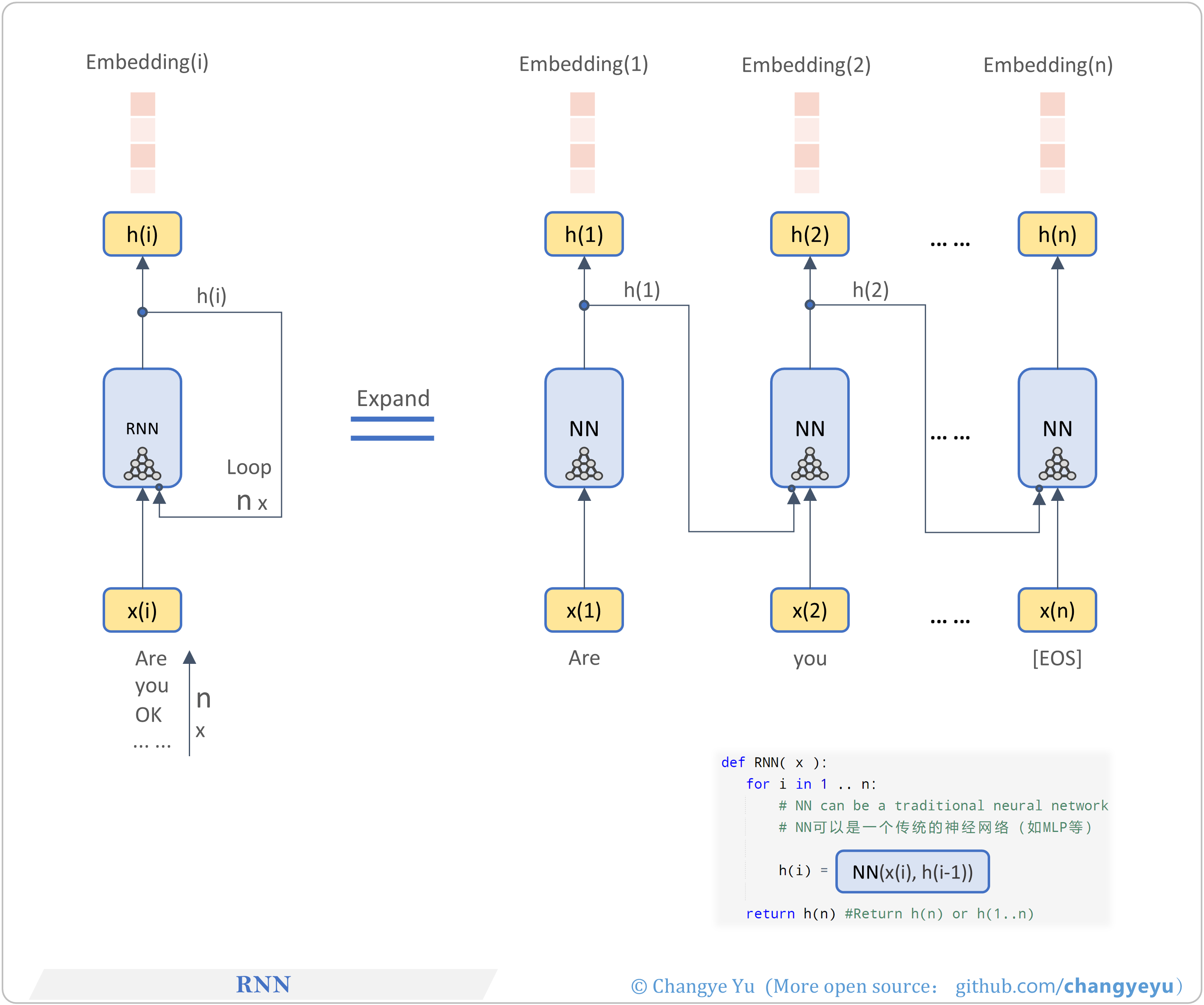
【LLM basics extended】RNN(Recurrent Neural Network)
- RNN processes sequential data via recurrent connections to maintain hidden state.
- Pros: simple, handles short-term dependencies.
- Cons: suffers from vanishing/exploding gradients, poor long-term dependencies.

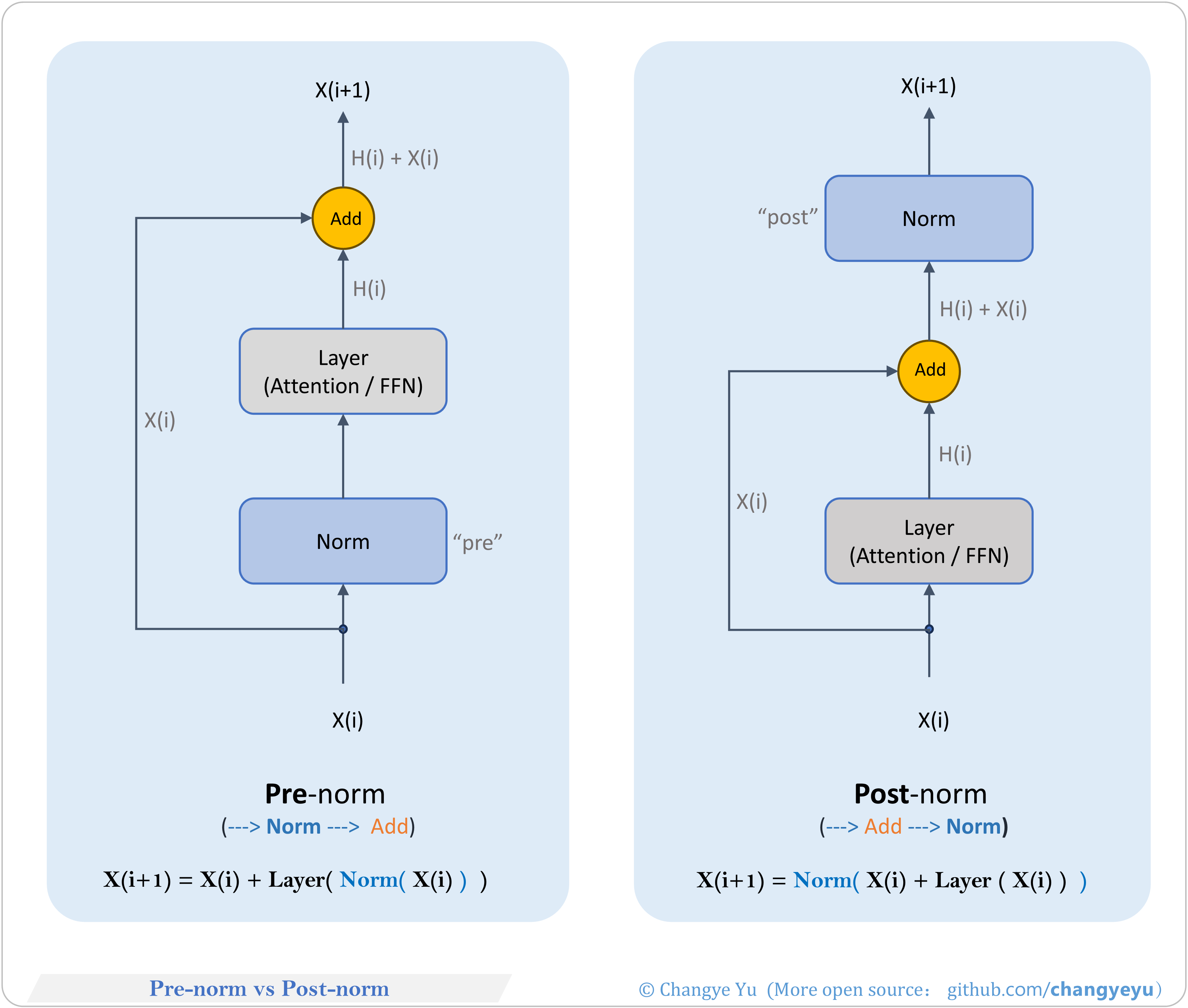
【LLM basics extended】Pre-norm vs Post-norm
- Pre-norm: apply LayerNorm before sublayer then add residual, improving gradient flow in deep networks.
- Post-norm: traditional Transformer norm after residual, may cause gradient decay in deep models.
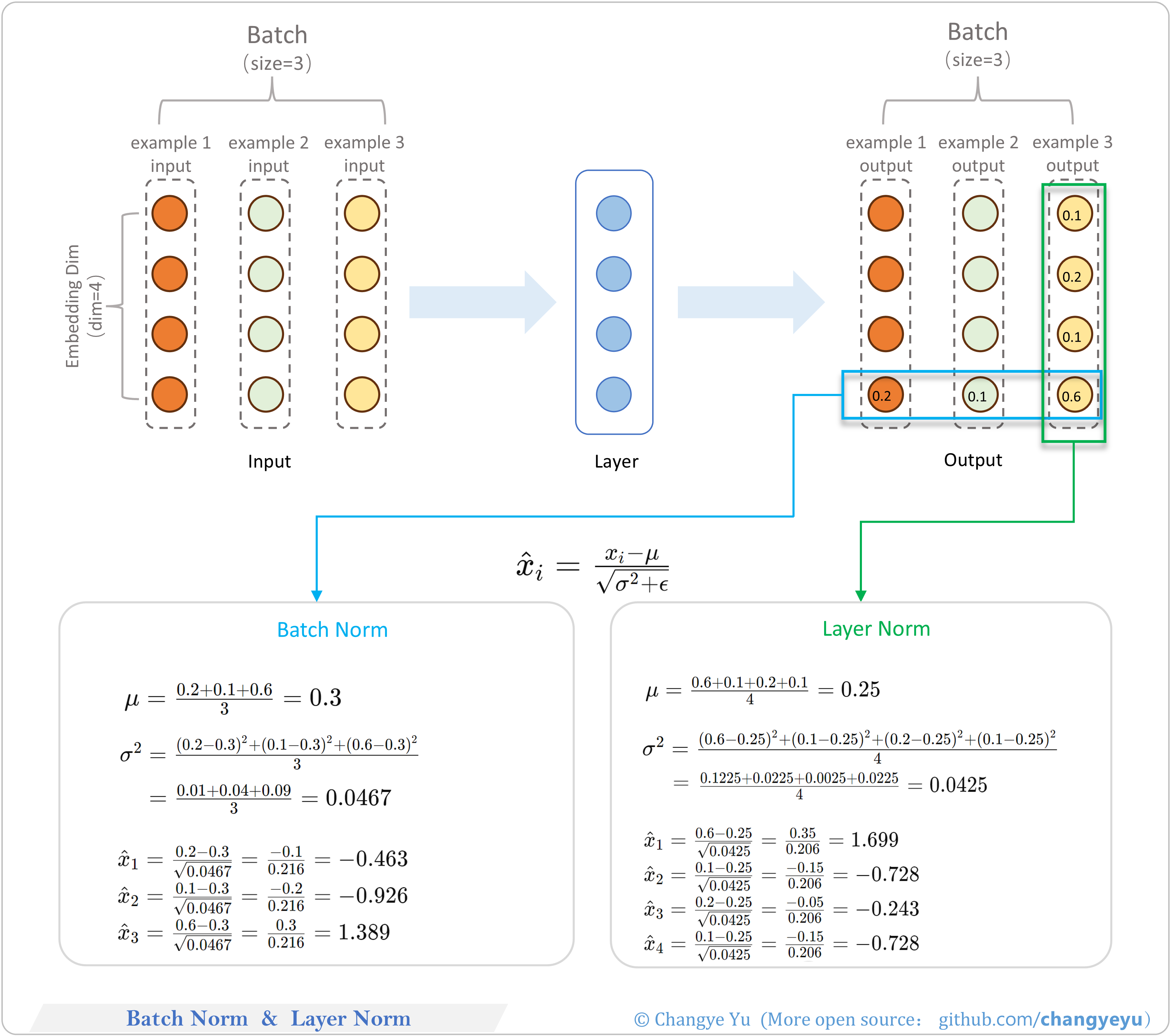
【LLM basics extended】BatchNorm & LayerNorm
- BatchNorm: normalize each channel across the batch, then scale and shift.
- LayerNorm: normalize all features of each sample, then scale and shift.

【LLM basics extended】RMSNorm
- RMSNorm normalizes by the root-mean-square of input features (no mean subtraction), then scales and shifts. More efficient and comparable or superior to LayerNorm.

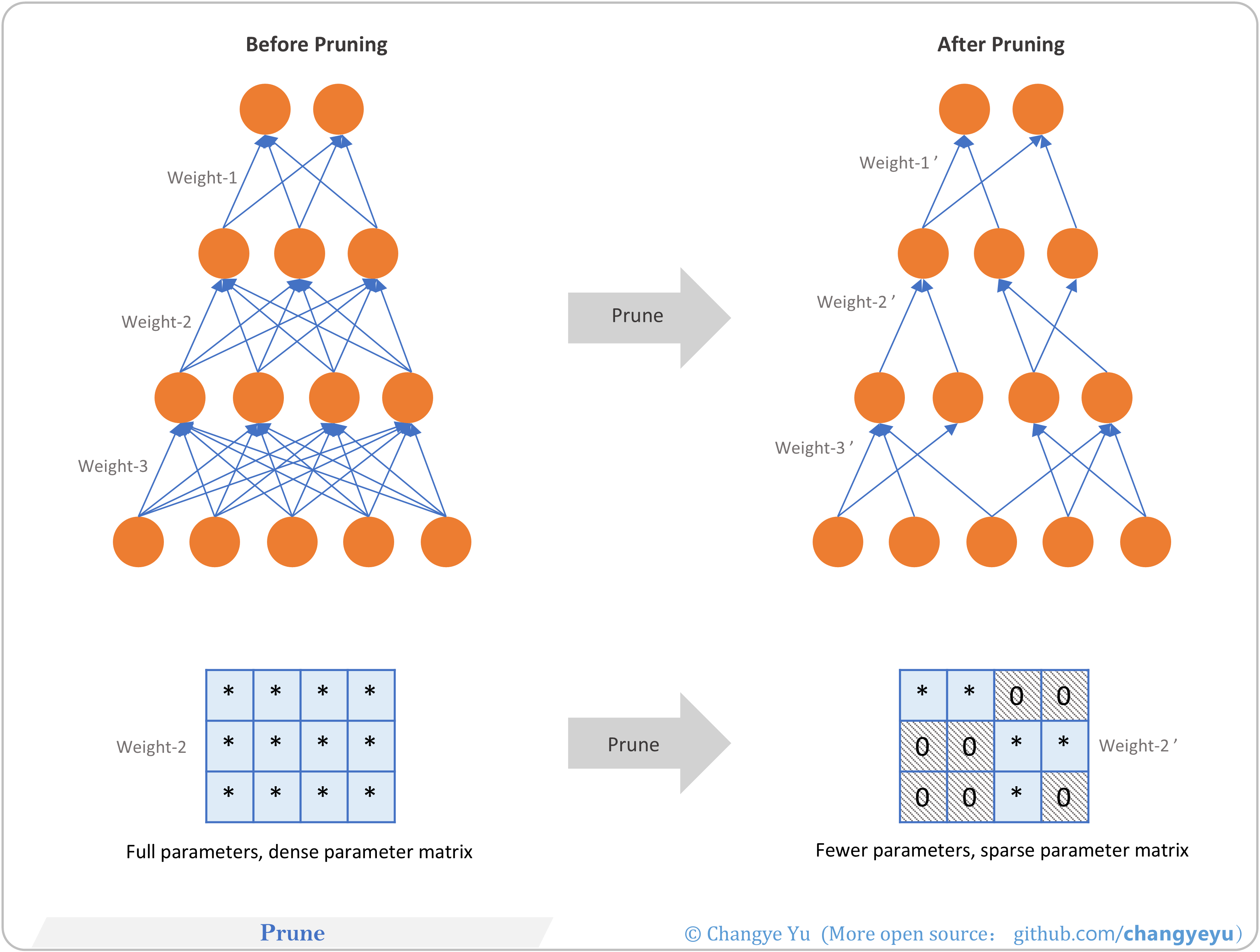
【LLM basics extended】Prune
- Model pruning removes redundant weights/neuron channels to compress networks, then fine-tunes to retain accuracy. Steps: importance scoring → prune → fine-tune → validate.
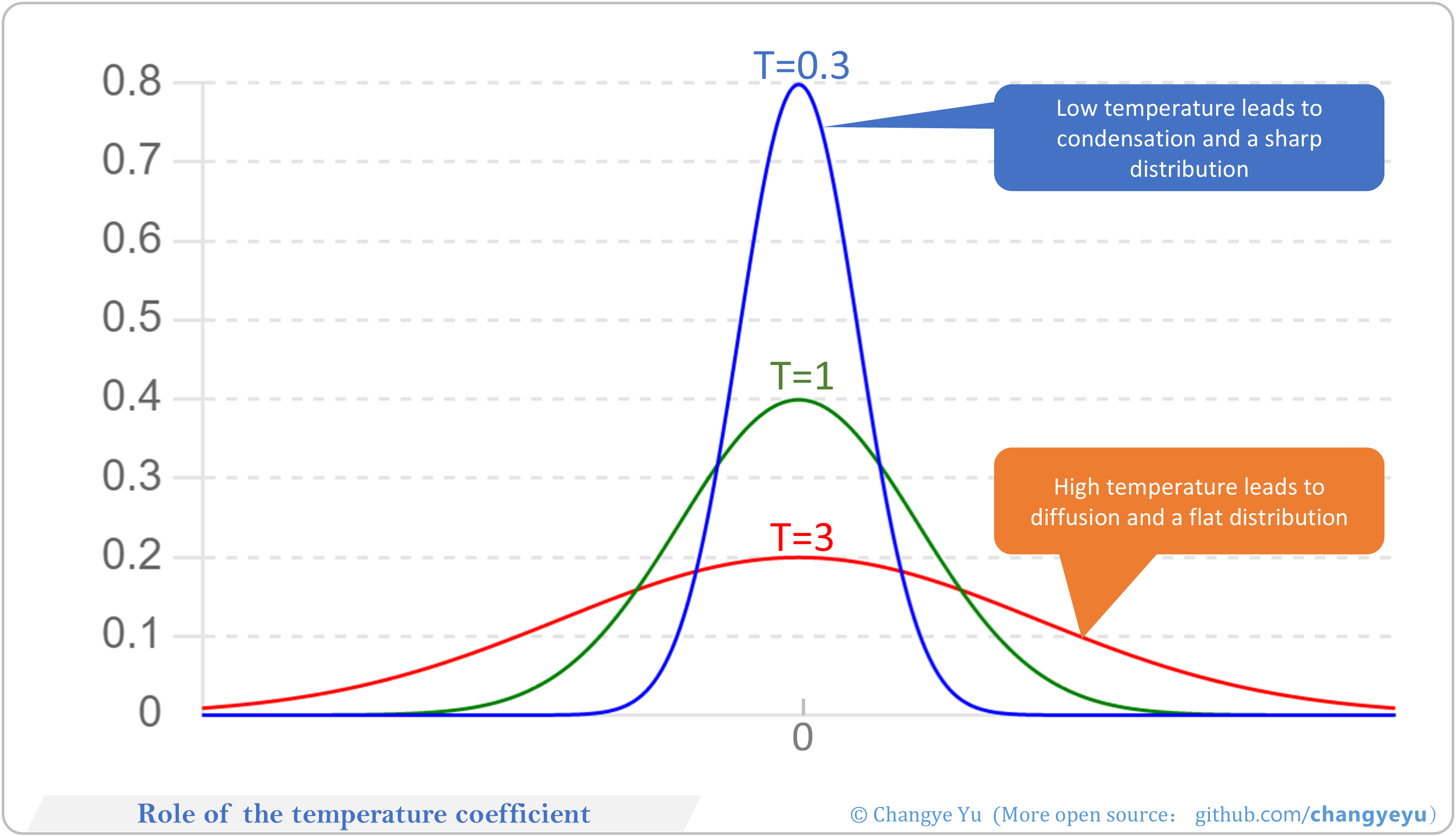
【LLM basics extended】Role of the temperature coefficient
- Temperature T scales logits for sampling diversity:
- T<1 sharpens distribution, more deterministic.
- T>1 flattens distribution, more random.
- Adjusting T balances accuracy vs creativity.

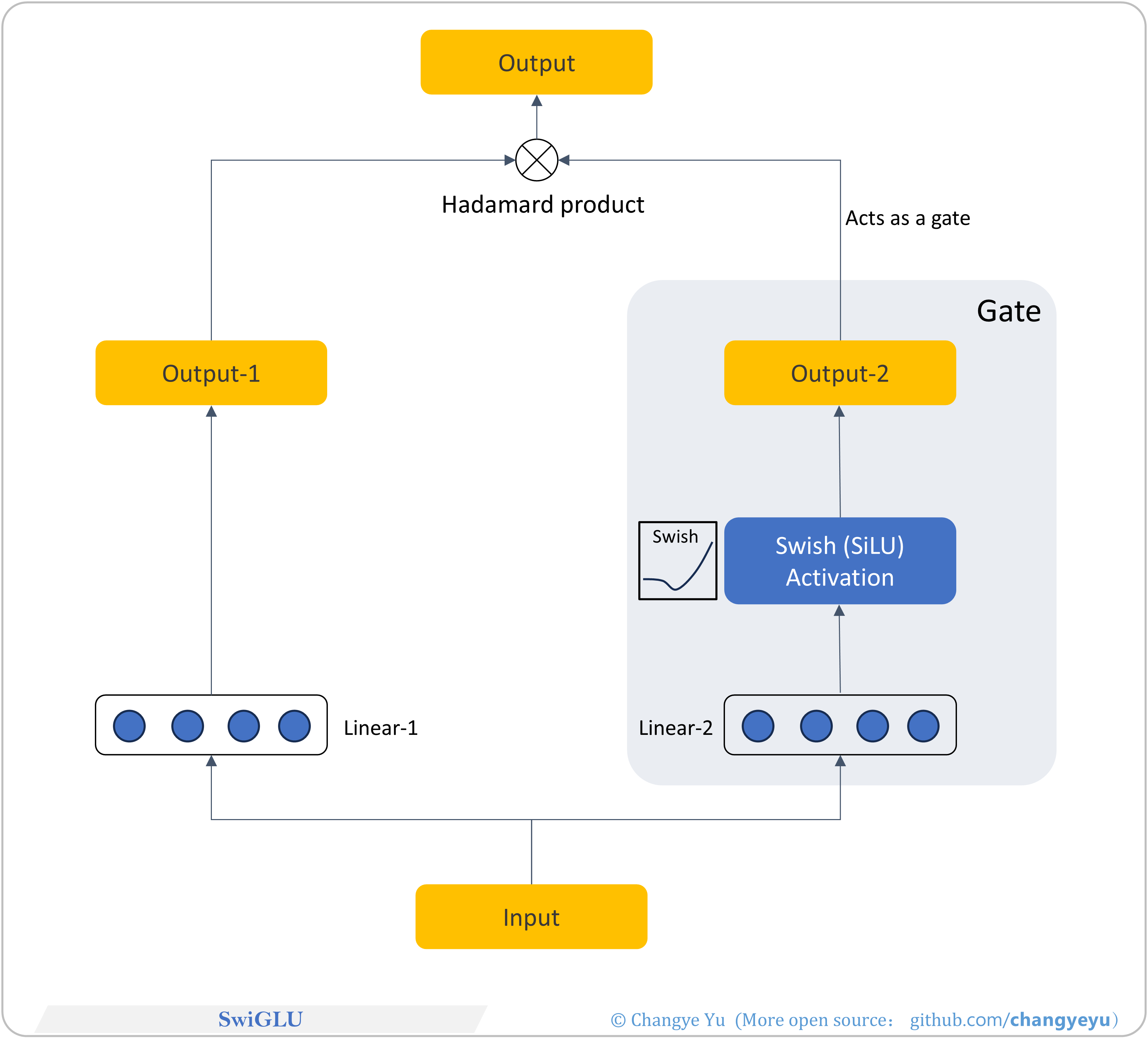
【LLM basics extended】SwiGLU
- SwiGLU is a GLU variant with two linear projections: one direct, one through a SiLU gate, multiply elementwise. Smooth gating improves gradient stability and convergence.
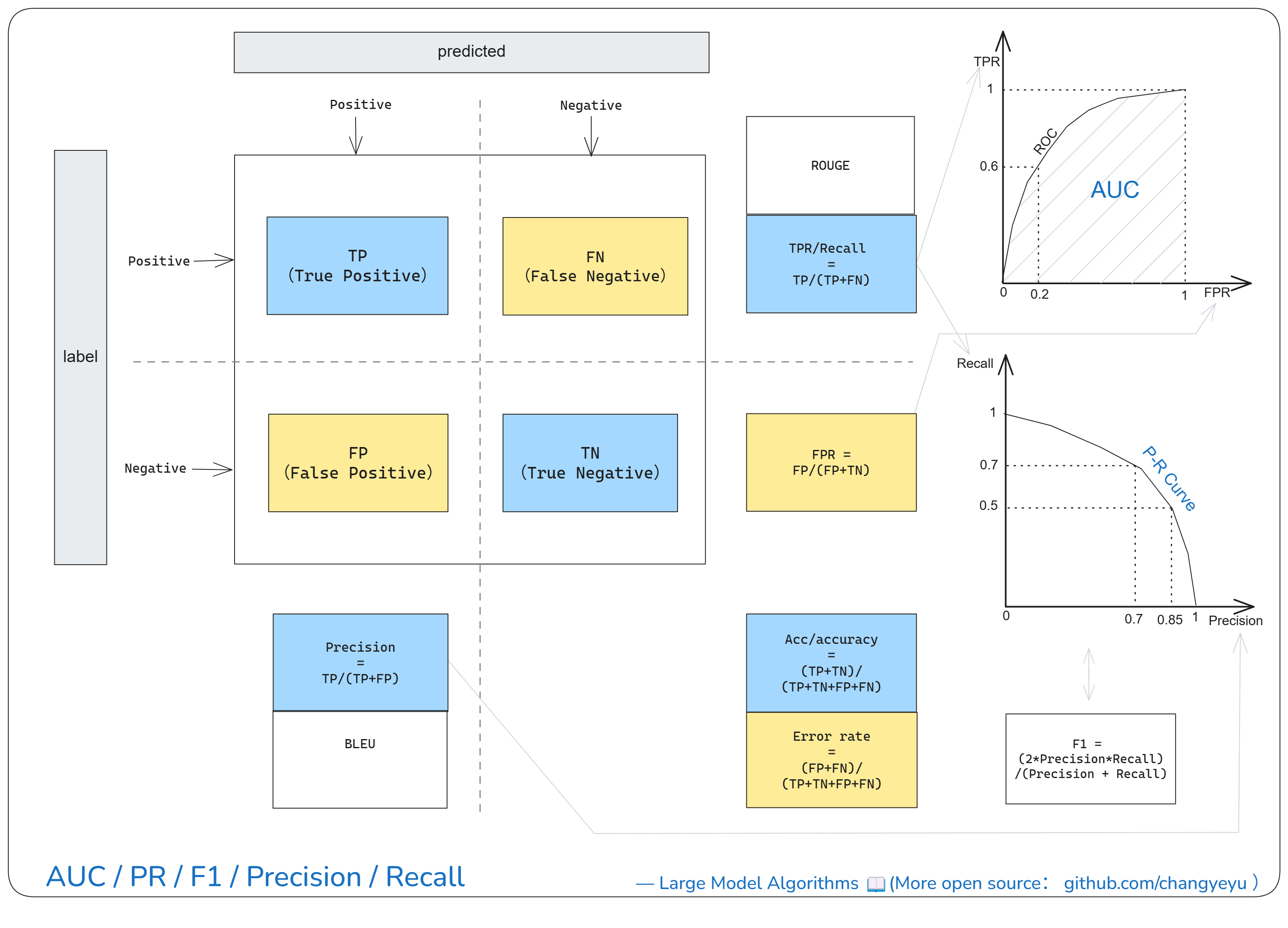
【LLM basics extended】AUC、PR、F1、Precision、Recall
- AUC: Area Under the ROC Curve.
- PR Curve: precision–recall across thresholds.
- Precision = TP/(TP+FP).
- Recall = TP/(TP+FN).
- F1 Score = 2 * (Precision * Recall) / (Precision + Recall).
- Accuracy = (TP+TN)/(TP+TN+FP+FN).
- BLEU: n-gram overlap for MT.
- ROUGE: n-gram/LCS overlap for summarization.

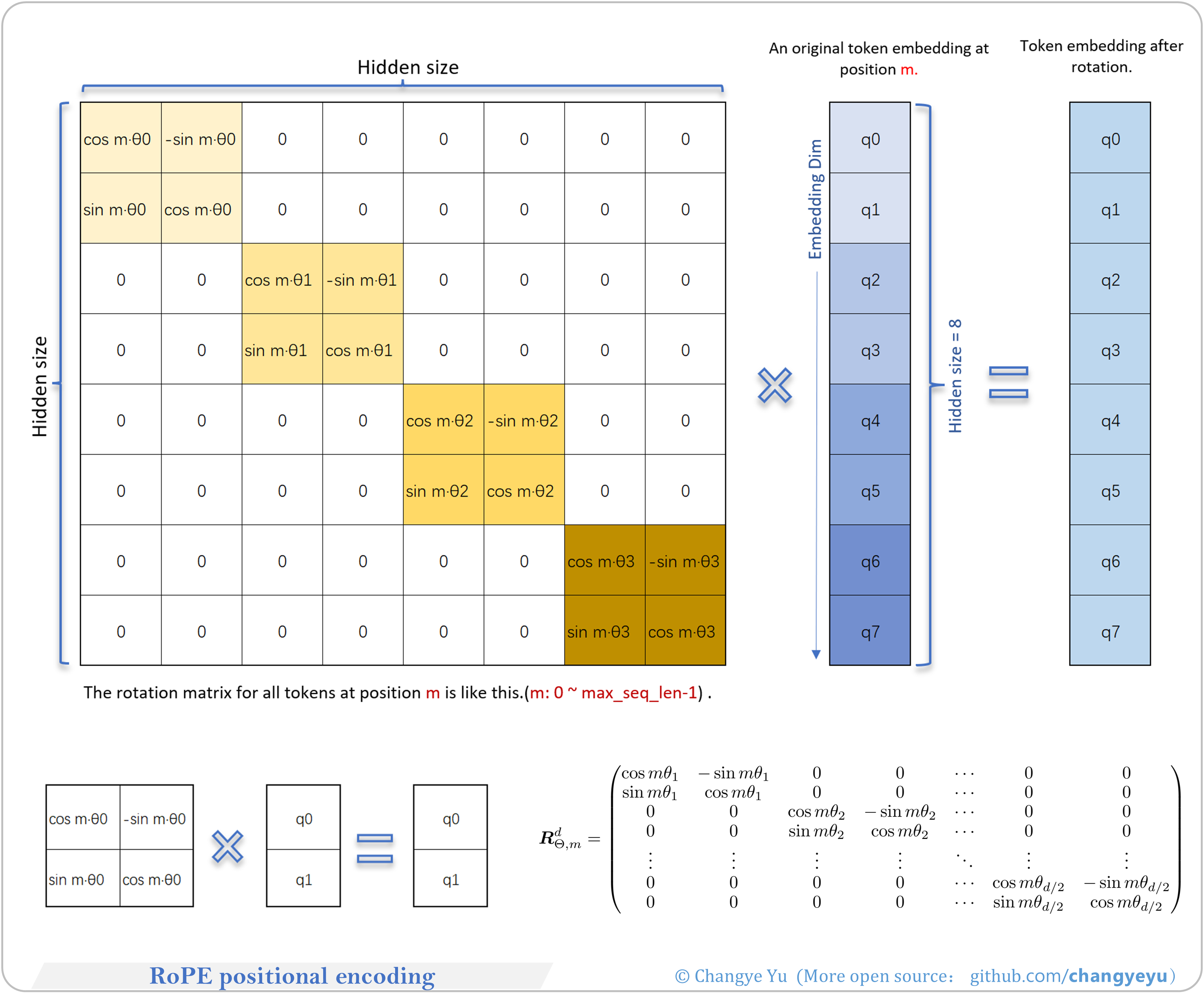
【LLM basics extended】RoPE positional encoding
- Rotary Position Embedding applies sinusoidal rotations to query/key vectors, encoding positions as phase differences. No extra parameters, efficient for long sequences.
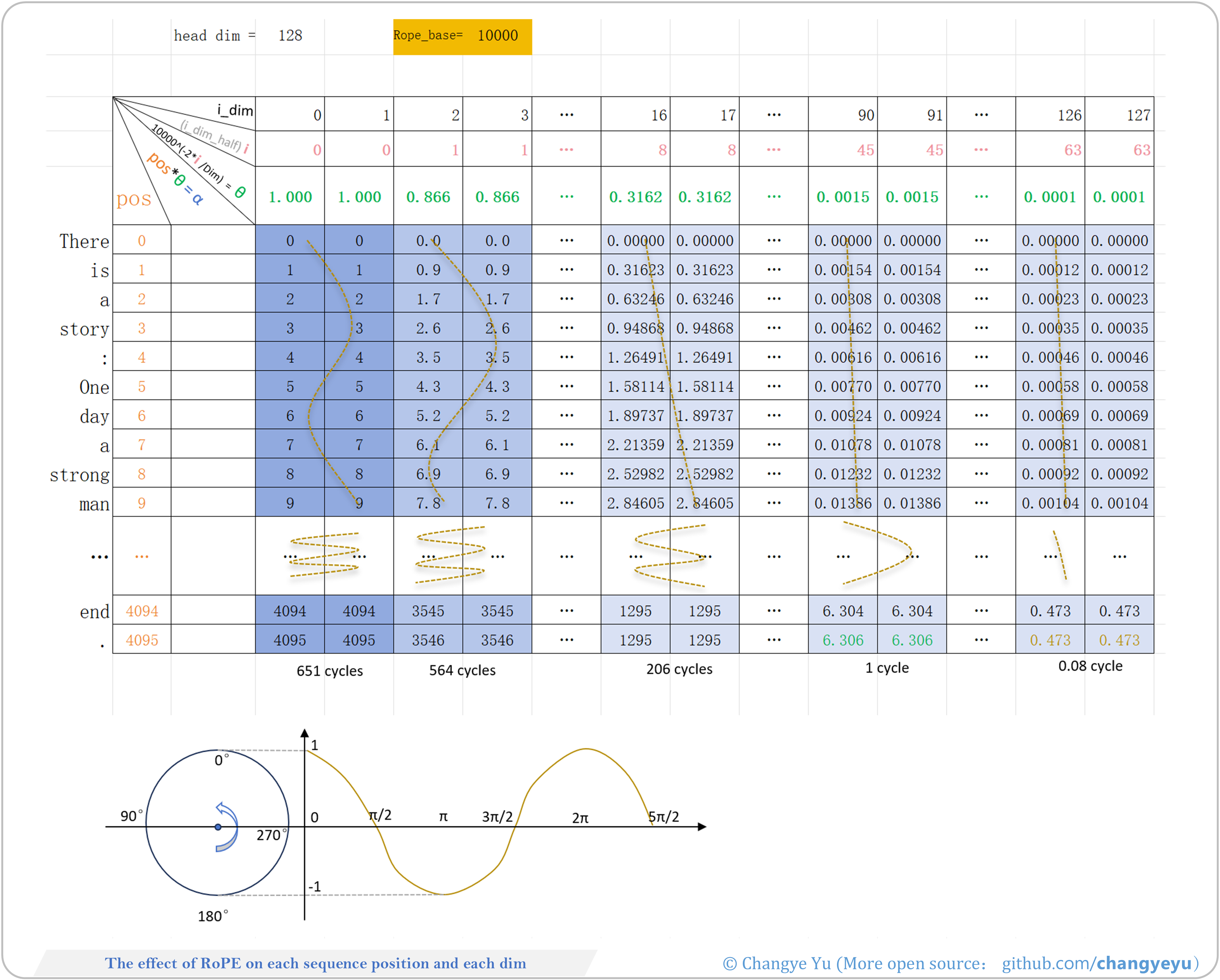
【LLM basics extended】The effect of RoPE on each sequence position and each dim
- For details on the principles of RoPE, the base and θ values, and how they work, see: RoPE-theta-base.xlsx
- RoPE groups embedding dimensions in pairs and applies a 2D rotation per pair with an angle based on position and frequency.
- High-frequency dimensions capture short-range relative positions.
- Low-frequency dimensions capture long-range relative positions.
Contributing
-
Contributions are welcome! Example diagram template: images-template.pptx
-
How to contribute:
(1) Fork: Click the "Fork" button to create a copy of the repo under your GitHub account →
(2) Clone: Clone the forked repo to your local environment →
(3) Create a new local branch →
(4) Make changes and commit →
(5) Push changes to your remote repo →
(6) Submit a PR: On GitHub, go to your forked repo and click "Compare & pull request" to submit a PR. The maintainer will review and merge it into the main repository. -
Suggested color scheme for diagram design:
Light Blue (#71CCF5) ;
Light Yellow (#FFE699) ;
Blue-Purple (#C0BFDE) ;
Pink (#F0ADB7)
Terms of Use
All images in this repository are licensed under LICENSE. You are free to use, modify, and remix the materials under the following terms:
- Sharing — You may copy and redistribute the material in any format.
- Adapting — You may remix, transform, and build upon the material.
You must also comply with the following terms:
- For Web Use — If using the materials in blog posts or online content, please retain the original author information embedded in the images.
- For Papers, Books, and Publications — If using the materials in formal publications, please cite the source using the format below. In such cases, the embedded author info may be removed from the image.
- Non-commercial Use Only — These materials may not be used for any direct commercial purposes.
Citation
If you use any content from this project (including diagrams or concepts from the book), please cite it as follows:
📌 For Reference Section
Yu, Changye. Large Model Algorithms: Reinforcement Learning, Fine-Tuning, and Alignment.
Beijing: Publishing House of Electronics Industry, 2025. https://github.com/changyeyu/LLM-RL-Visualized
📌 BibTeX Citation Format
@book{yu2025largemodel_en,
title = {Large Model Algorithms: Reinforcement Learning, Fine-Tuning, and Alignment},
author = {Yu, Changye},
publisher = {Publishing House of Electronics Industry},
year = {2025},
address = {Beijing},
isbn = {9787121500725},
url = {https://github.com/changyeyu/LLM-RL-Visualized},
language = {en}
}