Agentica
July 24, 2026 · View on GitHub
Agentica
让 Agent 真正跑起来——跑得久、不跑飞、能干活、会进化。 Async-first Python agent harness · 40+ 工具 · 20+ 模型 · MCP · CLI + Web Gateway
![]()

![]()
![]()


![]()
Agentica 不是套一层 LLM API 的聊天壳,而是一个 Async-First 的 agent harness——让 Agent 真正跑起来:调工具、跑长任务、多智能体协作、跨会话记忆,并持续自我进化。
| 跑得久,不跑飞 | 专门 Agentic loop 驱动的 LLM ↔ Tool 长循环,内置上下文压缩、成本预算、死循环防护,长任务不断链 |
| 能干活,不只聊天 | 文件、执行、搜索、浏览器、MCP、多智能体、Workflow——真实动手,不绑定单一 IDE |
| 记得住,会遗忘 | 记忆按条目存储、相关性召回、drift 防御,确认过的偏好同步到全局 ~/.agentica/AGENTS.md |
| 越用越强 | 工具失败 / 用户纠正 / 成功序列沉淀为经验卡片,自动编译成可复用的 SKILL.md,跨会话生效 |
| 全可换,不锁死 | 模型、工具、记忆、Skill、Guardrails、MCP 都是可替换部件,而非封闭 SaaS 黑盒 |
和其它框架对比
| Agentica | LangChain | AutoGen / CrewAI | Pydantic AI | |
|---|---|---|---|---|
| Async-first agentic loop | ✅ 内置压缩/预算/防死循环 | 片段拼装 | ✅ | ✅ |
| 自进化 Skill | ✅ 自动编译 SKILL.md | ❌ | ❌ | ❌ |
/goal 长任务循环 | ✅ | ❌ | ❌ | ❌ |
| 持久跨会话记忆 | ✅ 开箱即用 | 需自行拼装 | 部分 | 需自行拼装 |
| 开箱 CLI + Web Gateway | ✅ | ❌ | ❌ | ❌ |
🔥 News
- [2026/07/24] v1.4.10:支持视觉模型原生图片输入与模型能力 catalog 路由;新增
/rename和按名称/resume。详见 Release-v1.4.10 - [2026/07/21] v1.4.9:内置 subagent 全部改为只读;
edit_file改为 tip 提示而非硬拒;修复ask_user_questionCLI 卡死。详见 Release-v1.4.9 - [2026/07/05] v1.4.7:CLI 新增 cron 运行时(
/cron命令 + daemon)、自管理(/upgrade、/config set|env);统一配置到~/.agentica/config.yaml。详见 Release-v1.4.7 - [2026/06/03] v1.4.6:支持fallback模型可配置,支持多个fallback模型;支持 LSP, CLI 开启 LSP 开关(
--enable-diagnostics/--diagnostics-server);支持agentica doctor;支持/goal长程任务。详见 Release-v1.4.6 - [2026/05/11] v1.4.4:MemoryExtractHooks 优化,新增
auto_extract_memory_background后台抽取(不再阻塞on_agent_end),memory 抽取优先走更快更便宜的auxiliary_model。详见 Release-v1.4.4 - [2026/05/10] v1.4.3:Skill 生命周期重构 + VaG 解耦,新增
SkillLifecycleHooks统一扩展点。详见 Release-v1.4.3
架构
Agentica 提供了从底层模型路由到顶层多智能体协作的完整抽象:
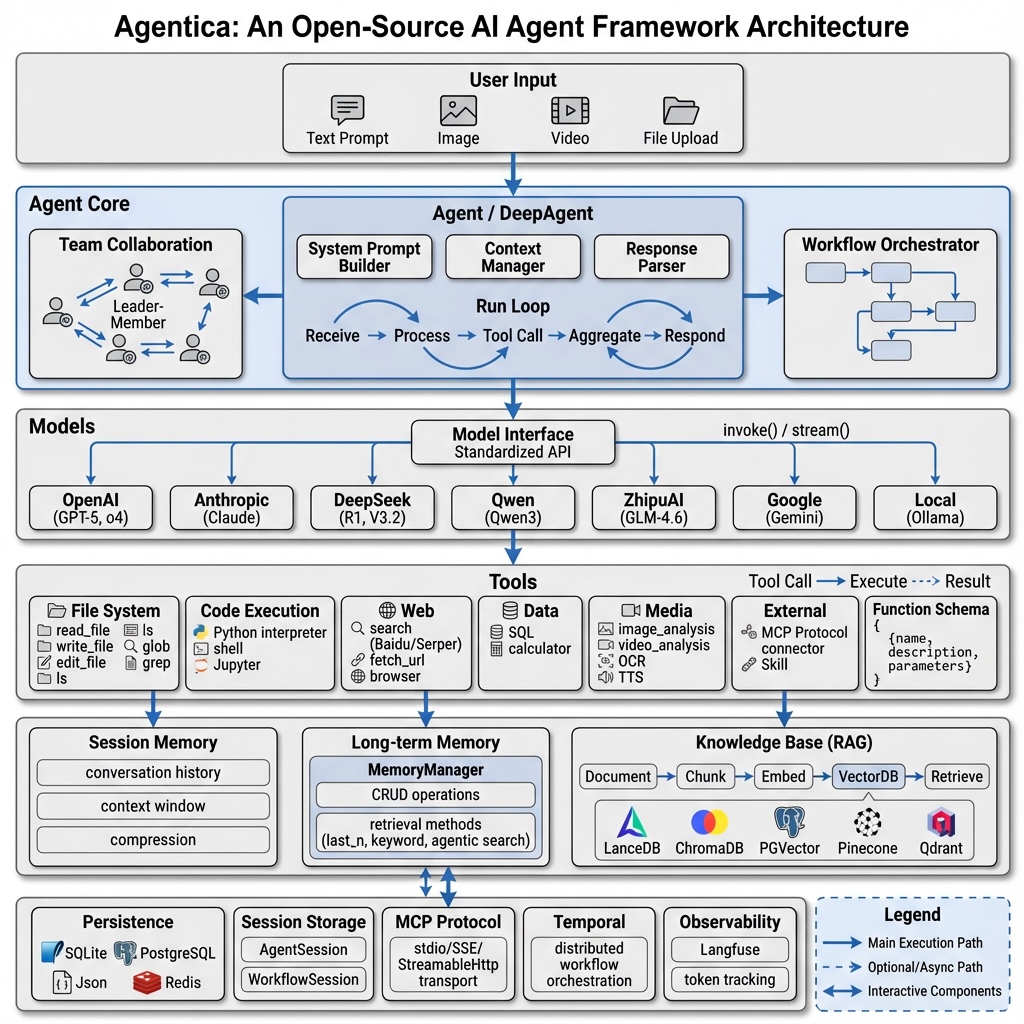
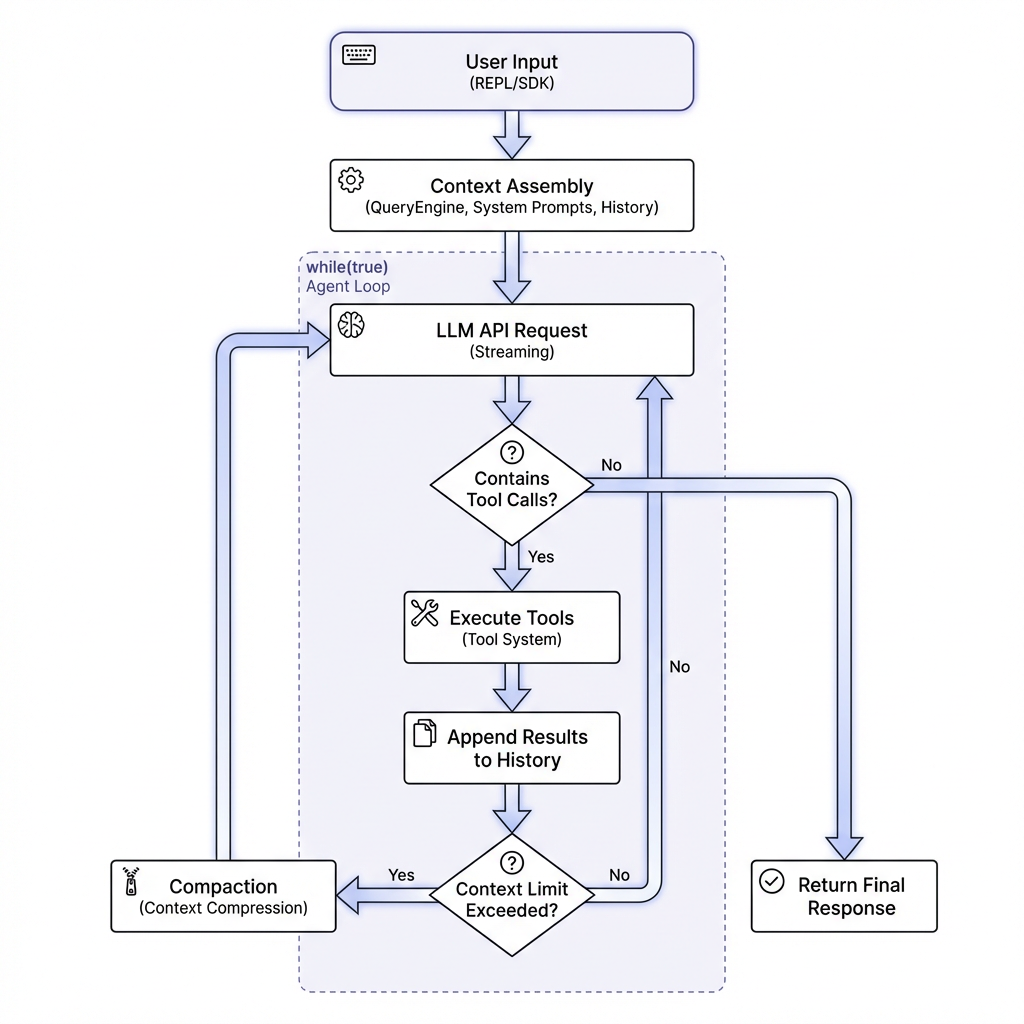
核心执行引擎 (Agentic Loop)
Agentica 的单体 Agent 运行在一个纯粹的基于控制流的 while(true) 引擎中,严格依据工具调用来驱动,并内置了防死循环、成本追踪、上下文微压缩(Compaction)和四层安全护栏:
安装
pip install -U agentica
快速开始
from agentica import Agent, OpenAIChat
agent = Agent(model=OpenAIChat(id="gpt-4o-mini"))
result = agent.run_sync("一句话介绍北京")
print(result.content)
让 Agent 真正干活——搜资料 + 写文件,一行 run_sync 搞定:
from agentica import Agent, OpenAIChat, BuiltinWebSearchTool, BuiltinFileTool, BuiltinExecuteTool
agent = Agent(
model=OpenAIChat(id="gpt-4o-mini"),
tools=[BuiltinWebSearchTool(), BuiltinFileTool(work_dir="./workspace"), BuiltinExecuteTool(work_dir="./workspace")],
)
agent.run_sync("帮我搜 Python 3.13 新特性,写到 features.md")
功能特性
- Async-First — 原生 async API,
asyncio.gather()并行工具执行,同步适配器兼容 - 20+ 模型 — OpenAI / DeepSeek / Claude / ZhipuAI / Qwen / Moonshot / Ollama / LiteLLM 等
- 40+ 内置工具 — 搜索、代码执行、文件操作、浏览器、OCR、图像生成
- RAG — 知识库管理、混合检索、Rerank,集成 LangChain / LlamaIndex
- 多智能体 —
Agent.as_tool()(轻量组合)、Swarm(并行/自治)和 Workflow(确定性编排) - Actor-Critic 精炼 —
refine()+ 多 Critic 并行评审,SchemaCritic程序级零成本验证 /AgentCritic异构强模型把关,循环检测自动早停 /goal长任务循环 —await agent.run_goal("xxx")持续推进,自动判断完成、续跑、暂停;支持 token / wall-clock / turn 三种 hard cap;CLI/goal /subgoal即开即用,详见 文档- 安全守卫 — 输入/输出/工具级 Guardrails,流式实时检测
- MCP / ACP — Model Context Protocol 和 Agent Communication Protocol 支持
- Skill 系统 — 基于 Markdown 的技能注入,支持项目级、用户级和外部托管 skill 目录
- 持久化记忆 — 索引/内容分离、相关性召回、四类型分类、drift 防御,可同步长期偏好到全局
AGENTS.md - 多模态 — 文本、图像、音频、视频理解
- 自进化 — 经验卡片自动编译为可跨会话复用的
SKILL.md(流程见下图)
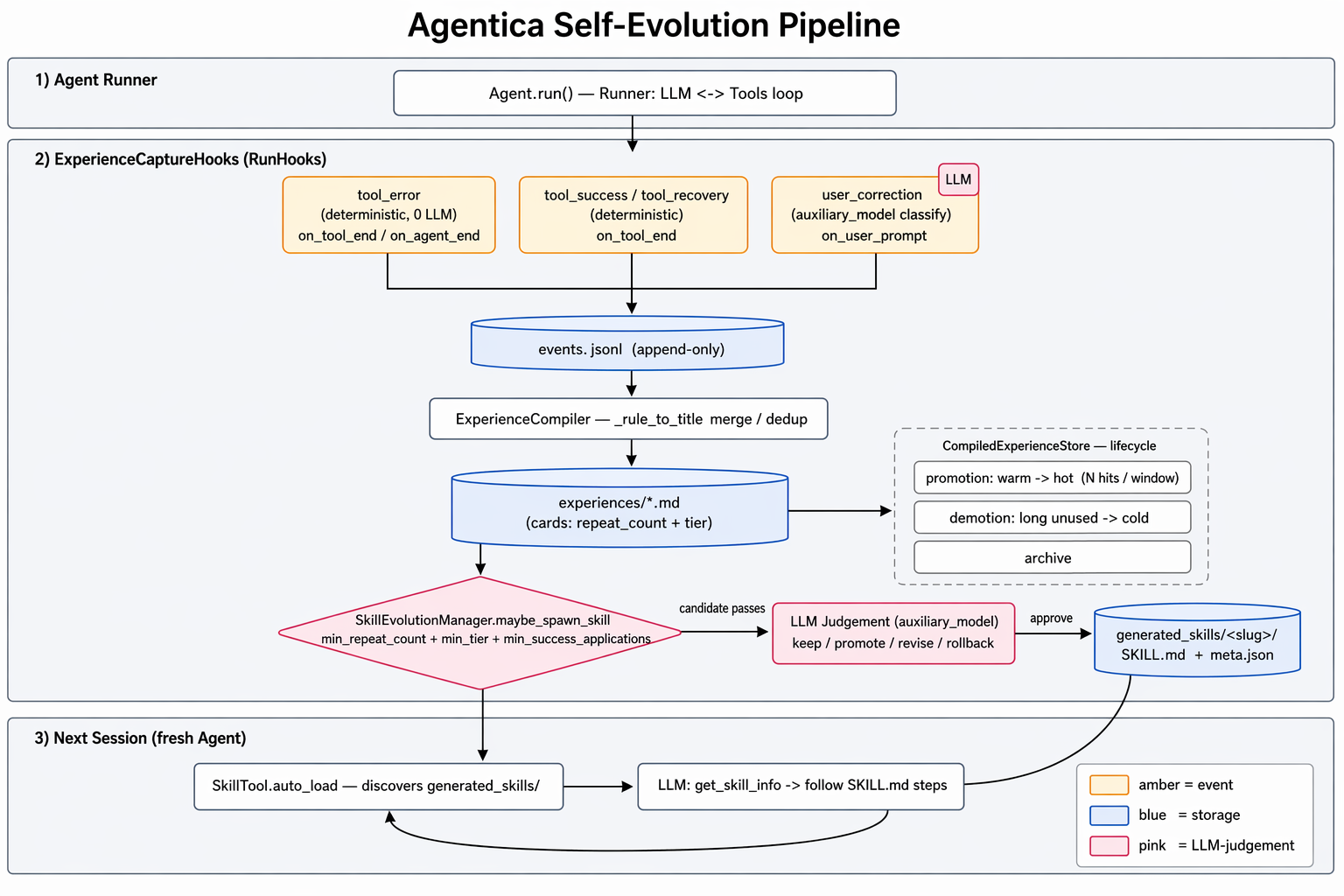
Agent 用例
自定义工具组合
from agentica import Agent, OpenAIChat, BuiltinWebSearchTool, BuiltinFileTool, BuiltinExecuteTool
agent = Agent(
model=OpenAIChat(id="gpt-4o-mini"),
tools=[BuiltinWebSearchTool(), BuiltinFileTool(work_dir="./workspace"), BuiltinExecuteTool(work_dir="./workspace")],
)
agent.run_sync("帮我搜 Python 3.13 新特性,写到 features.md")
完全体(CLI / Gateway / 长任务)
from agentica import DeepAgent
agent = DeepAgent() # 40+ 内置工具 + 压缩 + 长期记忆 + skills + MCP,开箱即用
CLI
agentica

长任务:/goal
让 Agent 持续向一个目标推进,每轮结束自动判断是否完成,没完成就续跑——直到 judge 判 done、预算耗尽、或用户主动停下。
CLI:
/goal 实现 xxx 功能并跑通 pytest # 设置目标 + 自动开跑
/goal status # 显示状态、预算、subgoals
/goal pause | resume | clear
/subgoal 必须补单测 # 给目标加验收条件
完整说明:Standing Goal Loop 文档。
Web UI / IM 集成
pip install -U "agentica[gateway]"
启动:
agentica-gateway

Web网页会启动在 http://127.0.0.1:8881/chat。
除Web网页,还支持手机端(IM)接入 QQ / 飞书 / 微信 / 企微 / Telegram / Discord / Slack 等。内置调度定时任务。
IM 接入详细参考(扫码绑定、渠道配置、环境变量):Gateway 文档。
示例
查看 examples/ 获取完整示例,涵盖:
| 类别 | 内容 |
|---|---|
| 基础用法 | Hello World、流式输出、结构化输出、多轮对话、多模态、Agentic Loop 对比 |
| 工具 | 自定义工具、Async 工具、搜索、代码执行、并行工具、并发安全、成本追踪、沙箱隔离、压缩 |
| Agent 模式 | Agent 作为工具、并行执行、团队协作、辩论、路由分发、Swarm、子 Agent、模型层钩子、会话恢复 |
| 安全护栏 | 输入/输出/工具级 Guardrails、流式护栏 |
| 记忆 | 会话历史、WorkingMemory、上下文压缩、Workspace 记忆、LLM 自动记忆 |
| RAG | PDF 问答、高级 RAG、LangChain / LlamaIndex 集成 |
| 工作流 | 数据管道、投资研究、新闻报道、代码审查 |
| MCP | Stdio / SSE / HTTP 传输、JSON 配置 |
| 可观测性 | Langfuse、Token 追踪、Usage 聚合 |
| 应用 | LLM OS、深度研究、客服系统、金融研究(6-Agent 流水线) |
文档
完整使用文档:https://shibing624.github.io/agentica
社区与支持
如果 Agentica 帮到了你,欢迎点个 ⭐ Star,让更多人看到!
- GitHub Issues — 提交 issue
- 微信群 — 添加微信号
xuming624,备注 "llm",加入技术交流群

引用
如果您在研究中使用了 Agentica,请引用:
Xu, M. (2026). Agentica: A Human-Centric Framework for Large Language Model Agent Workflows. GitHub. https://github.com/shibing624/agentica
许可证
贡献
欢迎贡献!请查看 CONTRIBUTING.md。