🦑 Welcome to TruLens!
May 16, 2026 · View on GitHub




![]()
![]()
🦑 Welcome to TruLens!

Don't just vibe-check your LLM app! Systematically evaluate and track your LLM experiments with TruLens. As you develop your app including prompts, models, retrievers, knowledge sources and more, TruLens is the tool you need to understand its performance.
Fine-grained, stack-agnostic instrumentation and comprehensive evaluations help you to identify failure modes & systematically iterate to improve your application.
Read more about the core concepts behind TruLens including Feedback Functions, The RAG Triad, and Honest, Harmless and Helpful Evals.
TruLens in the development workflow
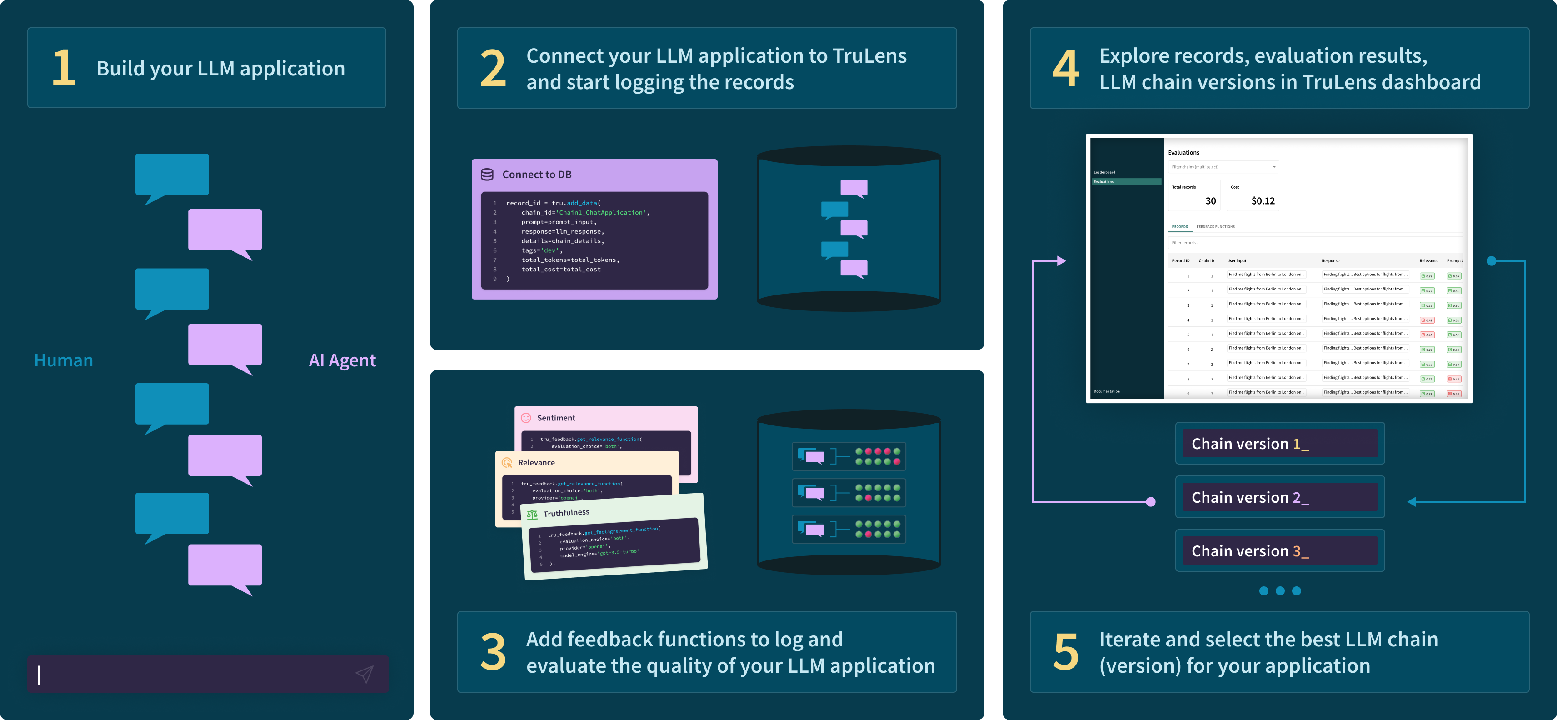
Build your first prototype then connect instrumentation and logging with TruLens. Decide what feedbacks you need, and specify them with TruLens to run alongside your app. Then iterate and compare versions of your app in an easy-to-use user interface 👇
Installation and Setup
Install the trulens pip package from PyPI.
pip install trulens-core
Install with a specific LLM provider for feedback evaluation:
pip install trulens trulens-providers-openai # OpenAI / Azure OpenAI
pip install trulens trulens-providers-litellm # LiteLLM (Anthropic, Cohere, Mistral, …)
pip install trulens trulens-providers-google # Google Gemini
pip install trulens trulens-providers-bedrock # AWS Bedrock
pip install trulens trulens-providers-cortex # Snowflake Cortex
pip install trulens trulens-providers-huggingface # HuggingFace
pip install trulens trulens-providers-langchain # LangChain models
Install with a specific app framework integration:
pip install trulens trulens-apps-langchain # LangChain / LangGraph
pip install trulens trulens-apps-llamaindex # LlamaIndex
Quick Usage
Walk through how to instrument and evaluate a RAG built from scratch with TruLens.
![]()
Key Features
🔭 OpenTelemetry-based tracing
TruLens instrumentation is built on OpenTelemetry. Every function call, LLM generation, retrieval, and tool invocation is captured as a structured OTEL span. This makes TruLens interoperable with existing observability infrastructure — export traces to Jaeger, Grafana Tempo, Datadog, or any OTLP-compatible backend.
from trulens.core.otel.instrument import instrument
from trulens.otel.semconv.trace import SpanAttributes
class MyRAG:
@instrument(
span_type=SpanAttributes.SpanType.RETRIEVAL,
attributes={
SpanAttributes.RETRIEVAL.QUERY_TEXT: "query",
SpanAttributes.RETRIEVAL.RETRIEVED_CONTEXTS: "return",
},
)
def retrieve(self, query: str) -> list:
...
🤖 Agentic evaluations
Seven purpose-built evaluators for agentic systems — each measuring a distinct aspect of agent behavior:
| Evaluator | What it measures |
|---|---|
| LogicalConsistency | Reasoning coherence; flags hallucinations and unsupported assertions |
| ExecutionEfficiency | Redundant steps, unnecessary retries, wasted computation |
| PlanAdherence | Whether execution followed the stated plan |
| PlanQuality | Intrinsic plan quality — strategy, not outcome |
| ToolSelection | Right tool chosen for each subtask |
| ToolCalling | Argument validity and output interpretation |
| ToolQuality | External tool/service reliability |
📊 Batch and inline evaluation
Run evaluations alongside your app, on existing data, or in offline batch mode:
# Inline — evaluate as the app runs
with tru_recorder as recording:
response = my_app.query("What is TruLens?")
# Batch — evaluate a pre-collected dataset using the TruLens 2.8 Run API
from trulens.core.run import RunConfig
run_config = RunConfig(
run_name="batch_eval_v1",
dataset_name="eval_questions",
source_type="TABLE",
dataset_spec={"input": "QUESTION"},
invocation_max_workers=8,
metric_max_workers=4,
)
run = tru_app.add_run(run_config=run_config)
run.start()
run.compute_metrics([relevance, groundedness])
🔌 MCP support
Instrument Model Context Protocol tool calls
with the MCP span type to capture tool name, arguments, output, and latency:
@instrument(span_type=SpanAttributes.SpanType.MCP)
def call_mcp_tool(self, tool_name: str, arguments: dict) -> str:
...
🎯 Selector API
Target any span attribute for evaluation using the flexible Selector API:
from trulens.core import Metric, Selector
f_context_relevance = Metric(
name="Context Relevance",
implementation=provider.context_relevance,
selectors={
"input": Selector.select_record_input(),
"context": Selector.select_context(),
},
)
Supported LLM Providers
| Provider | Package |
|---|---|
| OpenAI / Azure OpenAI | trulens-providers-openai |
| LiteLLM (Anthropic, Cohere, Mistral, and more) | trulens-providers-litellm |
| Google Gemini | trulens-providers-google |
| AWS Bedrock | trulens-providers-bedrock |
| Snowflake Cortex | trulens-providers-cortex |
| HuggingFace | trulens-providers-huggingface |
| LangChain models | trulens-providers-langchain |
💡 Contributing & Community
Interested in contributing? See our contributing guide for more details.
The best way to support TruLens is to give us a ⭐ on GitHub and join our discourse community!