README.md
June 30, 2026 · View on GitHub
Awesome Prompt Engineering 🧙♂️
A hand-curated collection of resources for Prompt Engineering and Context Engineering — covering papers, tools, models, APIs, benchmarks, courses, and communities for working with Large Language Models.
https://promptslab.github.io
Master Prompt Engineering. Join the Course at https://promptslab.github.io
Master Prompt Engineering. Join the Course at https://promptslab.github.io
![]()
![]()
![]()
🚀 Start Here
New to prompt engineering? Follow this path:
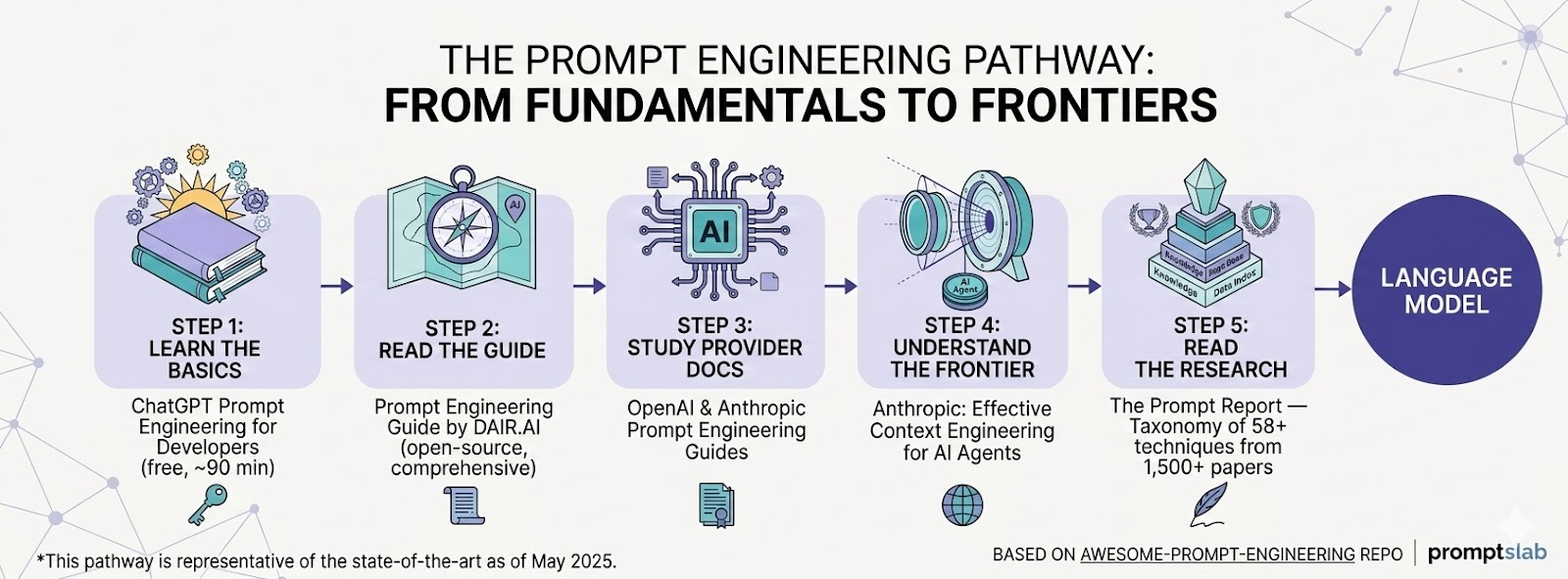
- Learn the basics → ChatGPT Prompt Engineering for Developers (free, ~90 min)
- Read the guide → Prompt Engineering Guide by DAIR.AI (open-source, comprehensive)
- Study provider docs → OpenAI Prompt Engineering Guide · Anthropic Prompt Engineering Guide
- Understand where the field is heading → Anthropic: Effective Context Engineering for AI Agents
- Read the research → The Prompt Report — taxonomy of 58+ prompting techniques from 1,500+ papers
Table of Contents
- Papers
- Major Surveys
- Prompt Optimization and Automatic Prompting
- Prompt Compression
- Reasoning Advances
- In-Context Learning
- Agentic Prompting and Multi-Agent Systems
- Multimodal Prompting
- Structured Output and Format Control
- Prompt Injection and Security
- Applications of Prompt Engineering
- Text-to-Image Generation
- Text-to-Music/Audio Generation
- Foundational Papers (Pre-2024)
- Tools and Code
- APIs
- Datasets and Benchmarks
- Models
- AI Content Detectors
- Books
- Courses
- Tutorials and Guides
- Videos
- Communities
- Autonomous Research & Self-Improving Agents
- How to Contribute
Papers
📄
Major Surveys
- The Prompt Report: A Systematic Survey of Prompting Techniques [2024] — Most comprehensive survey: taxonomy of 58 text and 40 multimodal prompting techniques from 1,500+ papers. Co-authored with OpenAI, Microsoft, Google, Stanford.
- A Systematic Survey of Prompt Engineering in Large Language Models: Techniques and Applications [2024] — 44 techniques across application areas with per-task performance summaries.
- A Survey of Prompt Engineering Methods in LLMs for Different NLP Tasks [2024] — 39 prompting methods across 29 NLP tasks.
- A Survey of Automatic Prompt Engineering: An Optimization Perspective [2025] — Formalizes auto-PE methods as discrete/continuous/hybrid optimization problems.
- Efficient Prompting Methods for Large Language Models: A Survey [2024] — Survey of efficiency-oriented prompting (compression, optimization, APE) for reducing compute and latency.
- Navigate through Enigmatic Labyrinth: A Survey of Chain of Thought Reasoning [2023, ACL 2024] — Systematic CoT survey.
- Demystifying Chains, Trees, and Graphs of Thoughts [2024] — Unified framework for multi-prompt reasoning topologies.
- Towards Goal-oriented Prompt Engineering for Large Language Models: A Survey [2024] — Focuses on prompts designed around explicit task goals.
- Towards Reasoning Era: A Survey of Long Chain-of-Thought for Reasoning LLMs [2025] — Distinguishes Long CoT from Short CoT in o1/R1-era models.
Prompt Optimization and Automatic Prompting
- OPRO: Large Language Models as Optimizers [2023, NeurIPS 2024] — Uses LLMs as optimizers via meta-prompts; optimized prompts outperform human-designed ones by up to 50% on BBH.
- DSPy: Compiling Declarative Language Model Calls into Self-Improving Pipelines [2023, ICLR 2024] — Framework for programming (not prompting) LLMs with automatic prompt optimization.
- MIPRO: Optimizing Instructions and Demonstrations for Multi-Stage Language Model Programs [2024, EMNLP 2024] — Bayesian optimization for multi-stage LM programs; up to 13% accuracy gains.
- TextGrad: Automatic "Differentiation" via Text [2024] — Treats compound AI systems as computation graphs with textual feedback as gradients. Published in Nature.
- EvoPrompt [2023, ACL 2024] — Evolutionary algorithm approach for automatically optimizing discrete prompts.
- Meta Prompting for AI Systems [2023, ICLR 2024 Workshop] — Example-agnostic structural templates formalized using category theory.
- Prompt Engineering a Prompt Engineer (PE²) [2024, ACL Findings] — Uses LLMs to meta-prompt themselves, refining prompts with step-by-step templates to significantly improve reasoning.
- Large Language Models Are Human-Level Prompt Engineers [2022] — Automatic prompt generation via APE.
- Hard Prompts Made Easy: Gradient-Based Discrete Optimization for Prompt Tuning [2023]
- SPO: Self-Supervised Prompt Optimization [2025] — Competitive performance at 1–6% of the cost of prior methods.
Prompt Compression
- LLMLingua-2: Data Distillation for Efficient and Faithful Task-Agnostic Prompt Compression [2024, ACL 2024] — 3x–6x faster than LLMLingua with GPT-4 data distillation.
- LongLLMLingua [2023, ACL 2024] — Question-aware compression for long contexts; 21.4% performance boost with 4x fewer tokens.
- Prompt Compression for Large Language Models: A Survey [2024] — Comprehensive survey of hard and soft prompt compression methods.
Reasoning Advances
- Scaling LLM Test-Time Compute Optimally [2024] — Shows optimal test-time compute allocation can outperform 14x larger models.
- DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning [2025] — Pure RL-trained reasoning model matching o1; open-source with distilled variants.
- s1: Simple Test-Time Scaling [2025] — SFT on just 1,000 examples creates competitive reasoning model via "budget forcing."
- Reasoning Language Models: A Blueprint [2025] — Systematic framework organizing reasoning LM approaches.
- Demystifying Long Chain-of-Thought Reasoning in LLMs [2025] — Analyzes long CoT behavior in modern reasoning models.
- Graph of Thoughts: Solving Elaborate Problems with LLMs [2023, AAAI 2024] — Models thoughts as arbitrary graphs; 62% quality improvement over ToT on sorting.
- Tree of Thoughts: Deliberate Problem Solving with LLMs [2023, NeurIPS 2023] — Tree search over reasoning paths.
- Everything of Thoughts [2023] — Integrates CoT, ToT, and external solvers via MCTS.
- Skeleton-of-Thought [2023] — Parallel decoding via answer skeleton generation for up to 2.69x speedup.
- Chain of Thought Prompting Elicits Reasoning in Large Language Models [2022] — The foundational CoT paper.
- Self-Consistency Improves Chain of Thought Reasoning [2022] — Aggregating multiple CoT outputs for reliability.
- Large Language Models are Zero-Shot Reasoners [2022] — "Let's think step by step" as a zero-shot reasoning trigger.
- ReAct: Synergizing Reasoning and Acting in Language Models [2022] — Interleaving reasoning and tool use.
In-Context Learning
- Many-Shot In-Context Learning [2024, NeurIPS 2024 Spotlight] — Significant gains scaling ICL to hundreds/thousands of examples; introduces Reinforced and Unsupervised ICL.
- Many-Shot In-Context Learning in Multimodal Foundation Models [2024] — Scales multimodal ICL to ~2,000 examples across 14 datasets.
- Rethinking the Role of Demonstrations: What Makes In-Context Learning Work? [2022]
- Fantastically Ordered Prompts and Where to Find Them [2021] — Overcoming few-shot prompt order sensitivity.
- Calibrate Before Use: Improving Few-Shot Performance of Language Models [2021]
Agentic Prompting and Multi-Agent Systems
- Agentic Large Language Models: A Survey [2025] — Comprehensive survey organizing agentic LLMs by reasoning, acting, and interacting capabilities.
- Large Language Model based Multi-Agents: A Survey of Progress and Challenges [2024] — Covers profiling, communication, and growth mechanisms.
- Multi-Agent Collaboration Mechanisms: A Survey of LLMs [2025] — Reviews debate and cooperation strategies in LLM-based multi-agent systems.
- AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation [2023] — Microsoft's foundational multi-agent framework paper.
- ToolLLM: Facilitating Large Language Models to Master 16000+ Real-World APIs [2023, ICLR 2024] — Trains LLMs to use massive real-world API collections.
- SWE-bench: Can Language Models Resolve Real-World GitHub Issues? [2023, ICLR 2024] — The benchmark driving agentic coding progress.
- AgentBench: Evaluating LLMs as Agents [2023, ICLR 2024] — Benchmark across 8 environments.
- PAL: Program-aided Language Models [2023] — Offloading computation to code interpreters.
Multimodal Prompting
- Visual Prompting in Multimodal Large Language Models: A Survey [2024] — First comprehensive survey on visual prompting methods in MLLMs.
- Set-of-Mark Prompting Unleashes Extraordinary Visual Grounding in GPT-4V [2023] — Visual markers dramatically improve visual grounding.
- A Comprehensive Survey and Guide to Multimodal Large Language Models in Vision-Language Tasks [2024] — Covers text, image, video, audio MLLMs.
- Multimodal Chain-of-Thought Reasoning in Language Models [2023]
- From Prompt Engineering to Prompt Craft [2024] — Design-research view of prompt "craft" for diffusion models.
Structured Output and Format Control
- Let Me Speak Freely? A Study on the Impact of Format Restrictions on Performance of LLMs [2024] — Examines how constraining outputs to structured formats impacts reasoning performance.
- Batch Prompting: Efficient Inference with LLM APIs [2023]
- Structured Prompting: Scaling In-Context Learning to 1,000 Examples [2022]
Prompt Injection and Security
- Formalizing and Benchmarking Prompt Injection Attacks and Defenses [2023, USENIX Security 2024] — Formal framework with systematic evaluation of 5 attacks and 10 defenses across 10 LLMs.
- The Instruction Hierarchy: Training LLMs to Prioritize Privileged Instructions [2024] — OpenAI's priority-level training for injection defense.
- AgentDojo: A Dynamic Environment to Evaluate Prompt Injection Attacks and Defenses [2024] — Realistic agent scenario benchmark.
- InjecAgent: Benchmarking Indirect Prompt Injections in Tool-Integrated LLM Agents [2024]
- SecAlign: Defending Against Prompt Injection with Preference Optimization [2024] — DPO-based defense.
- WASP: Benchmarking Web Agent Security Against Prompt Injection [2025] — Security benchmark for web/computer-use agents.
- Many-Shot Jailbreaking [2024] — Scaling harmful examples in long-context windows enables jailbreaking (Anthropic Technical Report).
- Constitutional AI: Harmlessness from AI Feedback [2022]
- Ignore Previous Prompt: Attack Techniques For Language Models [2022]
- Artificial Intelligence and Cybersecurity: Documented Risks, Enterprise Guardrails, and Emerging Threats in 2024–2025 [2025] — Survey of real prompt-injection incidents with practical governance prompt patterns.
Applications of Prompt Engineering
- Rephrase and Respond: Let Large Language Models Ask Better Questions for Themselves [2023]
- Legal Prompt Engineering for Multilingual Legal Judgement Prediction [2023]
- Conversing with Copilot: Exploring Prompt Engineering for Solving CS1 Problems [2022]
- Commonsense-Aware Prompting for Controllable Empathetic Dialogue Generation [2023]
- PLACES: Prompting Language Models for Social Conversation Synthesis [2023]
- Medical Image Segmentation Using Transformer Encoders and Prompt-Based Learning: A Systematic Review [2025]
- TableRAG: A Retrieval Augmented Generation Framework for Heterogeneous Document Reasoning [2025] — SQL-based interface preserving tabular structure for multi-hop queries.
Text-to-Image Generation
- A Taxonomy of Prompt Modifiers for Text-To-Image Generation [2022]
- Design Guidelines for Prompt Engineering Text-to-Image Generative Models [2021]
- High-Resolution Image Synthesis with Latent Diffusion Models [2021]
- DALL·E: Creating Images from Text [2021]
- Investigating Prompt Engineering in Diffusion Models [2022]
Text-to-Music/Audio Generation
- MusicLM: Generating Music From Text [2023]
- ERNIE-Music: Text-to-Waveform Music Generation with Diffusion Models [2023]
- AudioLM: A Language Modeling Approach to Audio Generation [2023]
- Make-An-Audio: Text-To-Audio Generation with Prompt-Enhanced Diffusion Models [2023]
Foundational Papers (Pre-2024)
These papers established the core concepts that modern prompt engineering builds on:
- Language Models are Few-Shot Learners (GPT-3) [2020] — Demonstrated few-shot prompting at scale.
- Prefix-Tuning: Optimizing Continuous Prompts for Generation [2021]
- The Power of Scale for Parameter-Efficient Prompt Tuning [2021]
- Prompt Programming for Large Language Models: Beyond the Few-Shot Paradigm [2021]
- Show Your Work: Scratchpads for Intermediate Computation with Language Models [2021]
- Generated Knowledge Prompting for Commonsense Reasoning [2021]
- Making Pre-trained Language Models Better Few-shot Learners [2021]
- AutoPrompt: Eliciting Knowledge from Language Models with Automatically Generated Prompts [2020]
- How Can We Know What Language Models Know? [2020]
- A Prompt Pattern Catalog to Enhance Prompt Engineering with ChatGPT [2023]
- Synthetic Prompting: Generating Chain-of-Thought Demonstrations for LLMs [2023]
- Progressive Prompts: Continual Learning for Language Models [2023]
- Successive Prompting for Decompleting Complex Questions [2022]
- Decomposed Prompting: A Modular Approach for Solving Complex Tasks [2022]
- PromptChainer: Chaining Large Language Model Prompts through Visual Programming [2022]
- Ask Me Anything: A Simple Strategy for Prompting Language Models [2022]
- Prompting GPT-3 To Be Reliable [2022]
- On Second Thought, Let's Not Think Step by Step! Bias and Toxicity in Zero-Shot Reasoning [2022]
Tools and Code
🔧
Prompt Management and Testing
| Name | Description | Link |
|---|---|---|
| Promptfoo | Open-source CLI for testing, evaluating, and red-teaming LLM prompts. YAML configs, CI/CD integration, adversarial testing. ~9K+ ⭐ | GitHub |
| Promptify | Solve NLP Problems with LLM's & Easily generate different NLP Task prompts for popular generative models like GPT, PaLM, and more with Promptify | [Github] |
| Agenta | Open-source LLM developer platform for prompt management, evaluation, human feedback, and deployment. | GitHub |
| PromptLayer | Version, test, and monitor every prompt and agent with robust evals, tracing, and regression sets. | Website |
| Helicone | Production prompt monitoring and optimization platform. | Website |
| LangGPT | Framework for structured and meta-prompt design. 10K+ ⭐ | GitHub |
| ChainForge | Visual toolkit for building, testing, and comparing LLM prompt responses without code. | GitHub |
| LMQL | A query language for LLMs making complex prompt logic programmable. | GitHub |
| Promptotype | Platform for developing, testing, and managing structured LLM prompts. | Website |
| PromptPanda | AI-powered prompt management system for streamlining prompt workflows. | Website |
| Promptimize AI | Browser extension to automatically improve user prompts for any AI model. | Website |
| PROMPTMETHEUS | Web-based "Prompt Engineering IDE" for iteratively creating and running prompts. | Website |
| Better Prompt | Test suite for LLM prompts before pushing to production. | GitHub |
| OpenPrompt | Open-source framework for prompt-learning research. | GitHub |
| Prompt Source | Toolkit for creating, sharing, and using natural language prompts. | GitHub |
| Prompt Engine | NPM utility library for creating and maintaining prompts for LLMs (Microsoft). | GitHub |
| PromptInject | Framework for quantitative analysis of LLM robustness to adversarial prompt attacks. | GitHub |
| LynxPrompt | Self-hostable platform for managing AI IDE config files (.cursorrules, CLAUDE.md, copilot-instructions.md). Web UI, REST API, CLI, and federated blueprint marketplace for 30+ AI coding assistants. | GitHub |
| flompt | Visual AI prompt builder that decomposes prompts into 12 semantic blocks (role, context, constraints, examples, etc.) and compiles them into optimized XML. Browser extension for ChatGPT/Claude/Gemini, and MCP server for Claude Code agents. Free, open-source. | Website |
LLM Evaluation Tools
| Name | Description | Link |
|---|---|---|
| DeepEval | Open-source evaluation framework covering RAG, agents, and conversations with CI/CD integration. ~7K+ ⭐ | GitHub |
| Ragas | RAG evaluation with knowledge-graph-based test set generation and 30+ metrics. ~8K+ ⭐ | GitHub |
| LangSmith | LangChain's platform for debugging, testing, evaluating, and monitoring LLM applications. | Website |
| Langfuse | Open-source LLM observability with tracing, prompt management, and human annotation. ~7K+ ⭐ | GitHub |
| Braintrust | End-to-end AI evaluation platform, SOC2 Type II certified. | Website |
| Arize AI / Phoenix | Real-time LLM monitoring with drift detection and tracing. | GitHub |
| TruLens | Evaluating and explaining LLM apps; tracks hallucinations, relevance, groundedness. | GitHub |
| InspectAI | Purpose-built for evaluating agents against benchmarks (UK AISI). | GitHub |
| Opik | Evaluate, test, and ship LLM applications across dev and production lifecycles. | GitHub |
| EvalView | CLI tool for testing multi-step AI agents with YAML test cases, regression detection, and production monitoring. | GitHub |
Agent Frameworks
| Name | Description | Link |
|---|---|---|
| LangChain / LangGraph | Most widely adopted LLM app framework; LangGraph adds graph-based multi-step agent workflows. ~100K+ / ~10K+ ⭐ | GitHub · LangGraph |
| CrewAI | Role-playing AI agent orchestration with 700+ integrations. ~44K+ ⭐ | GitHub |
| AutoGen (AG2) | Microsoft's multi-agent conversational framework. ~40K+ ⭐ | GitHub |
| DSPy | Stanford's framework for programming LLMs with automatic prompt/weight optimization. ~22K+ ⭐ | GitHub |
| OpenAI Agents SDK | Official agent framework with function calling, guardrails, and handoffs. ~10K+ ⭐ | GitHub |
| Semantic Kernel | Microsoft's AI framework powering M365 Copilot; C#, Python, Java. ~24K+ ⭐ | GitHub |
| LlamaIndex | Data framework for RAG and agent capabilities. ~40K+ ⭐ | GitHub |
| Haystack | Open-source NLP framework with pipeline architecture for RAG and agents. ~20K+ ⭐ | GitHub |
| Agno (formerly Phidata) | Python agent framework with microsecond instantiation. ~20K+ ⭐ | GitHub |
| Smolagents | Hugging Face's minimalist code-centric agent framework (~1000 LOC). ~15K+ ⭐ | GitHub |
| Pydantic AI | Type-safe agent framework using Pydantic for structured validation. ~8K+ ⭐ | GitHub |
| Mastra | TypeScript AI agent framework with assistants, RAG, and observability. ~20K+ ⭐ | GitHub |
| Google ADK | Agent Development Kit deeply integrated with Gemini and Google Cloud. | GitHub |
| Strands Agents (AWS) | Model-agnostic framework with deep AWS integrations. | GitHub |
| Langflow | Node-based visual agent builder with drag-and-drop. ~50K+ ⭐ | GitHub |
| n8n | Workflow automation with AI agent capabilities and 400+ integrations. ~60K+ ⭐ | GitHub |
| Dify | All-in-one backend for agentic workflows with tool-using agents and RAG. | GitHub |
| PraisonAI | Multi-AI Agents framework with 100+ LLM support, MCP integration, and built-in memory. | GitHub |
| Neurolink | Multi-provider AI agent framework unifying 12+ providers with workflow orchestration. | GitHub |
| Composio | Connect 100+ tools to AI agents with zero setup. | GitHub |
Prompt Optimization Tools
| Name | Description | Link |
|---|---|---|
| DSPy | Multiple optimizers (MIPROv2, BootstrapFewShot, COPRO) for automatic prompt tuning. ~22K+ ⭐ | GitHub |
| TextGrad | Automatic differentiation via text (Stanford). ~2K+ ⭐ | GitHub |
| OPRO | Google DeepMind's optimization by prompting. | GitHub |
Red Teaming and Prompt Security
| Name | Description | Link |
|---|---|---|
| Garak (NVIDIA) | LLM vulnerability scanner for hallucination, injection, and jailbreaks — the "nmap for LLMs." ~3K+ ⭐ | GitHub |
| PyRIT (Microsoft) | Python Risk Identification Tool for automated red-teaming. ~3K+ ⭐ | GitHub |
| DeepTeam | 40+ vulnerabilities, 10+ attack methods, OWASP Top 10 support. | GitHub |
| LLM Guard | Security toolkit for LLM I/O validation. ~2K+ ⭐ | GitHub |
| NeMo Guardrails (NVIDIA) | Programmable guardrails for conversational systems. ~5K+ ⭐ | GitHub |
| Guardrails AI | Define strict output formats (JSON schemas) to ensure system reliability. | Website |
| Lakera | AI security platform for real-time prompt injection detection. | Website |
| Purple Llama (Meta) | Open-source LLM safety evaluation including CyberSecEval. | GitHub |
| GPTFuzz | Automated jailbreak template generation achieving >90% success rates. | GitHub |
| Rebuff | Open-source tool for detection and prevention of prompt injection. | GitHub |
| AgentSeal | "Open-source scanner that runs 150 attack probes to test AI agents for prompt injection and extraction vulnerabilities." | GitHub |
MCP (Model Context Protocol)
MCP is an open standard developed by Anthropic (Nov 2024, donated to Linux Foundation Dec 2025) for connecting AI assistants to external data sources and tools through a standardized interface. It has 97M+ monthly SDK downloads and has been adopted by GitHub, Google, and most major AI providers.
| Name | Description | Link |
|---|---|---|
| MCP Specification | The core protocol specification and SDKs. ~15K+ ⭐ | GitHub |
| MCP Reference Servers | Official implementations: fetch, filesystem, GitHub, Slack, Postgres. | GitHub |
| FastMCP (Python) | High-level Pythonic framework for building MCP servers. ~5K+ ⭐ | GitHub |
| GitHub MCP Server | GitHub's official MCP server for repo, issue, PR, and Actions interaction. ~15K+ ⭐ | GitHub |
| Awesome MCP Servers | Curated list of 10,000+ community MCP servers. ~30K+ ⭐ | GitHub |
| Context7 | MCP server providing version-specific documentation to reduce code hallucination. | GitHub |
| GitMCP | Creates remote MCP servers for any GitHub repo by changing the domain. | Website |
| MCP Inspector | Visual testing tool for MCP server development. | GitHub |
Vibe Coding and AI Coding Assistants
🟢 = Open Source · 🔵 = Commercial · 🟣 = Open Source + Commercial (open core with paid cloud/API)
CLI-Based Coding Agents
Terminal-native agentic tools that understand your codebase and execute multi-step tasks.
| Name | Description | Type | Link |
|---|---|---|---|
| Claude Code | Anthropic's agentic coding CLI; understands full codebases and executes complex multi-step tasks via natural language. | 🔵 | Docs |
| OpenAI Codex CLI | Open-source terminal coding agent from OpenAI; lightweight, local-first, with sandboxed code execution. ~68K+ ⭐ | 🟣 | GitHub |
| Gemini CLI | Google's open-source terminal AI agent with 1M-token context window and Google Search grounding. ~96K+ ⭐ | 🟣 | GitHub |
| Qwen Code | Open-source terminal AI agent optimized for Qwen3-Coder; multi-protocol support (OpenAI/Anthropic/Gemini APIs), 1,000 free requests/day. ~21K+ ⭐ | 🟢 | GitHub |
| Aider | AI pair programming in terminal with deep Git integration; maps entire codebases and auto-commits changes. ~42K+ ⭐ | 🟢 | GitHub |
| OpenCode | Powerful open-source AI coding agent with beautiful TUI; supports nearly all AI model providers. ~120K+ ⭐ | 🟢 | GitHub |
| Goose | Extensible open-source AI agent from Block (Square/Cash App); installs, executes, edits, and tests with any LLM. ~29K+ ⭐ | 🟢 | GitHub |
| Crush | Glamorous agentic coding agent from Charmbracelet with multi-model support, LSP integration, and beautiful terminal UI. ~9K+ ⭐ | 🟢 | GitHub |
| Amazon Q Developer CLI | Agentic chat experience in terminal from AWS; transitioning to Kiro CLI. | 🟣 | GitHub |
| Amp | Sourcegraph's agentic coding tool (Cody successor); works across CLI and IDE. | 🔵 | Website |
| Junie CLI | JetBrains' LLM-agnostic coding agent CLI (beta 2026); supports all major model providers. | 🔵 | Website |
| Autohand Code CLI | Self-evolving autonomous terminal coding agent with multi-provider LLM support, 40+ tools, and modular skills system. | 🟢 | GitHub |
AI Code Editors / IDEs
Standalone editors or IDE forks with deep AI integration.
| Name | Description | Type | Link |
|---|---|---|---|
| Cursor | Leading AI-native code editor (VS Code fork); Composer generates entire apps from natural language, agentic multi-file edits. | 🔵 | Website |
| Windsurf | AI-powered IDE (VS Code fork) with proprietary Cascade agent and SWE-1.5 model; acquired by Cognition AI. | 🔵 | Website |
| Zed | High-performance editor in Rust with native AI features, Zeta edit prediction, and Agent Client Protocol support. ~77K+ ⭐ | 🟢 | GitHub |
| Trae | Free AI-powered IDE from ByteDance ("The Real AI Engineer") with Builder Mode; provides free access to Claude, GPT-4o, and DeepSeek. | 🔵 | Website |
| Google Antigravity | Google's agent-first IDE (VS Code fork) with Manager view for orchestrating multiple agents in parallel; powered by Gemini. | 🔵 | Website |
| Kiro | AWS's spec-driven agentic AI IDE (VS Code fork); turns prompts into specs, then working code, docs, and tests. | 🔵 | Website |
| PearAI | Open-source AI code editor (VS Code fork) with Continue-based chat and completions. ~40K+ ⭐ | 🟢 | GitHub |
| Void | Open-source Cursor alternative (VS Code fork); any model or local hosting with change visualization. ~28K+ ⭐ | 🟢 | GitHub |
| Melty | Open-source chat-first AI code editor with multi-file editing and deep Git integration. ~7K+ ⭐ | 🟢 | GitHub |
| Emdash | Open-source agentic dev environment (YC W26) for running multiple coding agents in parallel in isolated Git worktrees. | 🟢 | GitHub |
IDE Extensions / Plugins
Plugins for VS Code, JetBrains, Neovim, and other editors.
| Name | Description | Type | Link |
|---|---|---|---|
| GitHub Copilot | Most widely adopted AI coding assistant; inline completions, chat, and agentic coding agent across VS Code, JetBrains, Neovim. | 🔵 | Website |
| Cline | Autonomous coding agent in VS Code with human-in-the-loop approvals; file editing, terminal commands, and browser use. ~59K+ ⭐ | 🟢 | GitHub |
| Continue | Open-source VS Code and JetBrains extension for creating custom, modular AI dev systems; any model. ~32K+ ⭐ | 🟢 | GitHub |
| Cody | Sourcegraph-powered AI assistant that pulls context from local and remote codebases; VS Code, JetBrains, Visual Studio. | 🔵 | Website |
| Codeium | Free AI coding extension for 40+ IDEs with completions, chat, and search across 70+ languages. | 🟣 | Website |
| Amazon Q Developer | AWS's AI coding assistant with completions, inline chat, and agent mode; deep AWS integration. | 🟣 | Website |
| Gemini Code Assist | Google's IDE extension powered by Gemini with completions, Next Edit Predictions, and inline diffs; free for individuals. | 🟣 | Website |
| Tabnine | Privacy-focused AI assistant trained on permissive-licensed OSS; supports all major IDEs with on-premises deployment. | 🔵 | Website |
| Augment Code | Enterprise AI coding assistant with 200K-token Context Engine for deep codebase understanding. | 🔵 | Website |
| Qodo | AI code review and quality platform with multi-agent architecture; test generation, code review, CI/CD enforcement. | 🟣 | Website |
| CodeGeeX | Open-source multilingual code generation model supporting 20+ languages with VS Code and JetBrains extensions. ~11K+ ⭐ | 🟢 | GitHub |
| Tabby | Self-hosted open-source AI coding assistant (Copilot alternative); runs entirely on your infrastructure. ~25K+ ⭐ | 🟢 | GitHub |
AI Coding Platforms / Cloud Agents
Browser-based or cloud-hosted agents that build, test, and deploy autonomously.
| Name | Description | Type | Link |
|---|---|---|---|
| Devin | First fully autonomous cloud-based AI software engineer; plans, codes, tests, and opens PRs independently. | 🔵 | Website |
| Replit Agent | Cloud-native AI agent that autonomously builds, tests, and deploys full-stack apps in-browser; 50+ languages. | 🔵 | Website |
| bolt.new | AI-powered web dev agent; prompt, run, edit, and deploy full-stack apps directly in the browser via WebContainers. ~15K+ ⭐ | 🟢 | GitHub |
| bolt.diy | Community fork of bolt.new with extended features and broader LLM flexibility. ~12K+ ⭐ | 🟢 | GitHub |
| Lovable | Full-stack apps from natural language with built-in Supabase, auth, and one-click deploy; fastest European startup to $20M ARR. | 🔵 | Website |
| v0 | Vercel's AI platform for generating high-quality React/Next.js UI components from natural language. | 🔵 | Website |
| GitHub Copilot Workspace | Cloud-based coding environment with plan, brainstorm, and repair agents; included with paid Copilot plans. | 🔵 | Website |
| Firebase Studio | Google's agentic cloud-based development environment. | 🔵 | Website |
Open-Source Coding Agent Frameworks
Frameworks and research projects for building autonomous coding agents.
| Name | Description | Type | Link |
|---|---|---|---|
| OpenHands | Leading open-source platform for cloud coding agents; consistently top on SWE-bench. Formerly OpenDevin. ~69K+ ⭐ | 🟢 | GitHub |
| SWE-agent | Takes a GitHub issue and automatically fixes it using a custom agent-computer interface. [NeurIPS 2024] ~19K+ ⭐ | 🟢 | GitHub |
| Open SWE | LangChain's async cloud-hosted coding agent framework built on LangGraph with Slack/Linear integration. ~8K+ ⭐ | 🟢 | GitHub |
| Devika | Open-source agentic software engineer; breaks down instructions, researches, and writes code. Devin alternative. ~18K+ ⭐ | 🟢 | GitHub |
| AutoCodeRover | Autonomous program improvement combining LLMs with fault localization for GitHub issue resolution. ~2.8K+ ⭐ | 🟢 | GitHub |
| Agentless | Simple three-phase approach (localize → repair → validate) to solving software development problems. ~2K+ ⭐ | 🟢 | GitHub |
| Devon | Open-source pair programmer SWE agent with code writing, planning, and research; supports Claude, GPT-4, Llama, Ollama. ~3.5K+ ⭐ | 🟢 | GitHub |
Other Notable Repositories
| Name | Description | Link |
|---|---|---|
| Prompt Engineering Guide (DAIR.AI) | The definitive open-source guide and resource hub. 3M+ learners. ~55K+ ⭐ | GitHub |
| Awesome ChatGPT Prompts / Prompts.chat | World's largest open-source prompt library. 1000s of prompts for all major models. | GitHub |
| 12-Factor Agents | Principles for building production-grade LLM-powered software. ~17K+ ⭐ | GitHub |
| NirDiamant/Prompt_Engineering | 22 hands-on Jupyter Notebook tutorials. ~3K+ ⭐ | GitHub |
| Context Engineering Repository | First-principles handbook for moving beyond prompt engineering to context design. | GitHub |
| AI Agent System Prompts Library | Collection of system prompts from production AI coding agents (Claude Code, Gemini CLI, Cline, Aider, Roo Code). | GitHub |
| Awesome Vibe Coding | Curated list of 245+ tools and resources for building software through natural language prompts. | GitHub |
| OpenAI Cookbook | Official recipes for prompts, tools, RAG, and evaluations. | GitHub |
| Embedchain | Framework to create ChatGPT-like bots over your dataset. | GitHub |
| ThoughtSource | Framework for the science of machine thinking. | GitHub |
| Promptext | Extracts and formats code context for AI prompts with token counting. | GitHub |
| Price Per Token | Compare LLM API pricing across 200+ models. | Website |
| OpenPaw | CLI tool (npx pawmode) that turns Claude Code into a personal assistant by generating system prompts (CLAUDE.md + SOUL.md) with personality, memory, and 38 skill routers. | GitHub |
| Think Better | Open-source CLI that permanently injects 10 structured decision frameworks (MECE, Issue Trees, Pre-Mortems) and 12 cognitive bias detectors into AI assistant prompts. Go, MIT. | GitHub |
APIs
💻
OpenAI
| Model | Context | Price (Input/Output per 1M tokens) | Key Feature |
|---|---|---|---|
| GPT-5.2 / 5.2 Thinking | 400K | $1.75 / $14 | Latest flagship, 90% cached discount, configurable reasoning |
| GPT-5.1 | 400K | $1.25 / $10 | Previous generation flagship |
| GPT-4.1 / 4.1 mini / nano | 1M | $2 / $8 | Best non-reasoning model, 40% faster and 80% cheaper than GPT-4o |
| o3 / o3-pro | 200K | Varies | Reasoning models with native tool use |
| o4-mini | 200K | Cost-efficient | Fast reasoning, best on AIME at its cost class |
| GPT-OSS-120B / 20B | 128K | $0.03 / $0.30 | First open-weight models, Apache 2.0 |
Key features: Responses API, Agents SDK, Structured Outputs, function calling, prompt caching (90% discount), Batch API (50% discount), MCP support. Platform Docs
Anthropic (Claude)
| Model | Context | Price (Input/Output per 1M tokens) | Key Feature |
|---|---|---|---|
| Claude Opus 4.6 | 1M (beta) | $5 / $25 | Most powerful, state-of-the-art coding and agentic tasks |
| Claude Sonnet 4.5 | 200K | $3 / $15 | Best coding model, 61.4% OSWorld (computer use) |
| Claude Haiku 4.5 | 200K | Fast tier | Near-frontier, fastest model class |
| Claude Opus 4 / Sonnet 4 | 200K | $15/$75 (Opus) | Opus: 72.5% SWE-bench, Sonnet 4 powers GitHub Copilot |
Key features: Extended Thinking with tool use, Computer Use, MCP (originated here), prompt caching, Claude Code CLI, available on AWS Bedrock and Google Vertex AI. API Docs
Google (Gemini)
| Model | Context | Price (Input/Output per 1M tokens) | Key Feature |
|---|---|---|---|
| Gemini 3 Pro Preview | 1M | $2 / $12 | Most intelligent Google model, deployed to 2B+ Search users |
| Gemini 2.5 Pro | 1M | $1.25 / $10 | Best for coding/agentic tasks, thinking model |
| Gemini 2.5 Flash / Flash-Lite | 1M | $0.30/$1.50 · $0.10/$0.40 | Price-performance leaders |
Key features: Thinking (all 2.5+ models), Google Search grounding, code execution, Live API (real-time audio/video), context caching. Google AI Studio
Meta (Llama)
| Model | Architecture | Context | Key Feature |
|---|---|---|---|
| Llama 4 Scout | 109B MoE / 17B active | 10M | Fits single H100, multimodal, open-weight |
| Llama 4 Maverick | 400B MoE / 17B active, 128 experts | 1M | Beats GPT-4o, open-weight |
| Llama 3.3 70B | Dense | 128K | Matches Llama 3.1 405B |
Available on 25+ cloud partners, Hugging Face, and inference APIs. Llama
Other Notable Providers
| Provider | Description | Link |
|---|---|---|
| Mistral AI | Mistral Large 3 (675B MoE), Devstral 2, Ministral 3. Apache 2.0. | Website |
| DeepSeek | V3.2 (671B MoE), R1 (reasoning, MIT license). $0.15/$0.75 per 1M tokens. | Website |
| xAI (Grok) | Grok 4.1 Fast: 2M context, $0.20/$0.50 per 1M tokens. | Website |
| Cohere | Command A (111B, 256K context), Embed v4, Rerank 4.0. Excels at RAG. | Website |
| Together AI | 200+ open models with sub-100ms latency. | Website |
| Groq | LPU hardware with ~300+ tokens/sec inference. | Website |
| Fireworks AI | Fast inference with HIPAA + SOC2 compliance. | Website |
| OpenRouter | Unified API for 300+ models from all providers. | Website |
| Cerebras | Wafer-scale chips with best total response time. | Website |
| Perplexity AI | Search-augmented API with citations. | Website |
| Amazon Bedrock | Managed multi-model service with Claude, Llama, Mistral, Cohere. | Website |
| Hugging Face Inference | Access to open models via API. | Website |
Datasets and Benchmarks
💾
Major Benchmarks (2024–2026)
| Name | Description | Link |
|---|---|---|
| Chatbot Arena / LM Arena | 6M+ user votes for Elo-rated pairwise LLM comparisons. De facto standard for human preference. | Website |
| MMLU-Pro | 12,000+ graduate-level questions across 14 domains. NeurIPS 2024 Spotlight. | GitHub |
| GPQA | 448 "Google-proof" STEM questions; non-expert validators achieve only 34%. | arXiv |
| SWE-bench Verified | Human-validated 500-task subset for real-world GitHub issue resolution. | Website |
| SWE-bench Pro | 1,865 tasks across 41 professional repos; best models score only ~23%. | Leaderboard |
| Humanity's Last Exam (HLE) | 2,500 expert-vetted questions; top AI scores only ~10–30%. | Website |
| BigCodeBench | 1,140 coding tasks across 7 domains; AI achieves ~35.5% vs. 97% human success. | Leaderboard |
| LiveBench | Contamination-resistant with frequently updated questions. | Paper |
| FrontierMath | Research-level math; AI solves only ~2% of problems. | Research |
| ARC-AGI v2 | Abstract reasoning measuring fluid intelligence. | Research |
| IFEval | Instruction-following evaluation with formatting/content constraints. | arXiv |
| MLE-bench | OpenAI's ML engineering evaluation via Kaggle-style tasks. | GitHub |
| PaperBench | Evaluates AI's ability to replicate 20 ICML 2024 papers from scratch. | GitHub |
Leaderboards and Meta-Benchmarks
| Name | Description | Link |
|---|---|---|
| Hugging Face Open LLM Leaderboard v2 | Evaluates open models on MMLU-Pro, GPQA, IFEval, MATH. | Leaderboard |
| Artificial Analysis Intelligence Index v3 | Aggregates 10 evaluations. | Website |
| SEAL by Scale AI | Hosts SWE-bench Pro and agentic evaluations. | Leaderboard |
Prompt and Instruction Datasets
| Name | Description | Link |
|---|---|---|
| P3 (Public Pool of Prompts) | Prompt templates for 270+ NLP tasks used to train T0 and similar models. | HuggingFace |
| System Prompts Dataset | 944 system prompt templates for agent workflows (by Daniel Rosehill, Aug 2025). | HuggingFace |
| OpenAssistant Conversations (OASST) | 161,443 messages in 35 languages with 461,292 quality ratings. | HuggingFace |
| UltraChat / UltraFeedback | Large-scale synthetic instruction and preference datasets for alignment training. | HuggingFace |
| SoftAge Prompt Engineering Dataset | 1,000 diverse prompts across 10 categories for benchmarking prompt performance. | HuggingFace |
| Text Transformation Prompt Library | Comprehensive collection of text transformation prompts (May 2025). | HuggingFace |
| Writing Prompts | ~300K human-written stories paired with prompts from r/WritingPrompts. | Kaggle |
| Midjourney Prompts | Text prompts and image URLs scraped from MidJourney's public Discord. | HuggingFace |
| CodeAlpaca-20k | 20,000 programming instruction-output pairs. | HuggingFace |
| ProPEX-RAG | Dataset for prompt optimization in RAG workflows. | HuggingFace |
| NanoBanana Trending Prompts | 1,000+ curated AI image prompts from X/Twitter, ranked by engagement. | GitHub |
Red Teaming and Adversarial Datasets
| Name | Description | Link |
|---|---|---|
| HarmBench | 510 harmful behaviors across standard, contextual, copyright, and multimodal categories. | Website |
| JailbreakBench | Open robustness benchmark for jailbreaking with 100 prompts. | Research |
| AgentHarm | 110 malicious agent tasks across 11 harm categories. | arXiv |
| DecodingTrust | 243,877 prompts evaluating trustworthiness across 8 perspectives. | Research |
| SafetyPrompts.com | Aggregator tracking 50+ safety/red-teaming datasets. | Website |
Models
🧠
Frontier Models (2025–2026)
| Model | Provider | Context | Key Strength |
|---|---|---|---|
| GPT-5.2 | OpenAI | 400K | General intelligence, 100% AIME 2025 |
| Claude Opus 4.6 | Anthropic | 1M (beta) | Coding, agentic tasks, extended thinking |
| Gemini 3 Pro | 1M | #1 LMArena (~1500 Elo), multimodal | |
| Grok 4.1 | xAI | 2M | #2 LMArena (1483 Elo), low hallucination |
| Mistral Large 3 | Mistral AI | 256K | Best open-weight (675B MoE/41B active), Apache 2.0 |
| DeepSeek-V3.2 | DeepSeek | 128K | Best value (671B MoE/37B active), MIT license |
| Llama 4 Maverick | Meta | 1M | Beats GPT-4o (400B MoE/17B active), open-weight |
Reasoning Models
| Model | Key Detail |
|---|---|
| OpenAI o3 / o3-pro | 87.7% GPQA Diamond. Native tool use. |
| OpenAI o4-mini | Best AIME at its cost class with visual reasoning. |
| DeepSeek-R1 / R1-0528 | Open-weight, RL-trained. 87.5% on AIME 2025. MIT license. |
| QwQ (Qwen with Questions) | 32B reasoning model. Apache 2.0. Comparable to R1. |
| Gemini 2.5 Pro/Flash (Thinking) | Built-in reasoning with configurable thinking budget. |
| Claude Extended Thinking | Hybrid mode with visible chain-of-thought and tool use. |
| Phi-4 Reasoning / Plus | 14B reasoning models rivaling much larger models. Open-weight. |
| GPT-OSS-120B | OpenAI's open-weight with CoT. Near-parity with o4-mini. Apache 2.0. |
Notable Open-Source Models
| Model | Provider | Key Detail |
|---|---|---|
| Qwen3-235B-A22B | Alibaba | Flagship MoE. Strong reasoning/code/multilingual. Apache 2.0. Most downloaded family on HuggingFace. |
| Gemma 3 | 270M to 27B. Multimodal. 128K context. 140+ languages. | |
| OLMo 2/3 | Allen AI | Fully open (data, code, weights, logs). OLMo 2 32B surpasses GPT-3.5. Apache 2.0. |
| SmolLM3-3B | Hugging Face | Outperforms Llama-3.2-3B. Dual-mode reasoning. 128K context. |
| Kimi K2 | Moonshot AI | 32B active. Open-weight. Tailored for coding/agentic use. |
| Llama 4 Scout | Meta | 109B MoE/17B active. 10M token context. Fits single H100. |
Code-Specialized Models
| Model | Key Detail |
|---|---|
| Qwen3-Coder (480B-A35B) | 69.6% SWE-bench — milestone for open-source coding. 256K context. Apache 2.0. |
| Devstral 2 (123B) | 72.2% SWE-bench Verified. 7x more cost-efficient than Claude Sonnet. |
| Codestral 25.01 | Mistral's code model. 80+ languages. Fill-in-the-Middle support. |
| DeepSeek-Coder-V2 | 236B MoE / 21B active. 338 programming languages. |
| Qwen 2.5-Coder | 7B/32B. 92 programming languages. 88.4% HumanEval. Apache 2.0. |
Foundational Models (Historical Reference)
These models established key concepts but are largely superseded for practical use:
| Model | Provider | Significance |
|---|---|---|
| GLM-130B | Tsinghua | Open bilingual English/Chinese LLM (2023) |
| Falcon 180B | TII | Large open generative model (2023) |
| Mixtral 8x7B | Mistral AI | Pioneered MoE architecture for open models (2023) |
| GPT-NeoX-20B | EleutherAI | Early open autoregressive LLM |
| GPT-J-6B | EleutherAI | Early open causal language model |
AI Content Detectors
🔎
Leading Commercial Detectors
| Name | Accuracy | Key Feature | Link |
|---|---|---|---|
| GPTZero | 99% claimed | 10M+ users, #1 on G2 (2025). Detects GPT-4/5, Gemini, Claude, Llama. Free tier available. | Website |
| Originality.ai | 98–100% (peer-reviewed) | Consistently rated most accurate. Combines AI detection + plagiarism + fact checking. From $14.95/month. | Website |
| Turnitin AI Detection | 98%+ on unmodified AI text | Dominant in academia. Launched AI bypasser/humanizer detection (Aug 2025). Institutional licensing. | Website |
| Copyleaks | 99%+ claimed | Enterprise tool detecting AI in 30+ languages. LMS integrations. | Website |
| Winston AI | 99.98% claimed | OCR for scanned documents, AI image/deepfake detection. 11 languages. | Website |
| Pangram Labs | 99.3% (COLING 2025) | Highest score in COLING 2025 Shared Task. 100% TPR on "humanized" text. 97.7% adversarial robustness. | Website |
Free and Research Detectors
| Name | Description | Link |
|---|---|---|
| Binoculars | Open-source research detector using cross-perplexity between two LLMs. | arXiv |
| DetectGPT / Fast-DetectGPT | Statistical method comparing log-probabilities of original text vs. perturbations. | arXiv |
| Openai Detector | AI classifier for indicating AI-written text (OpenAI Detector Python wrapper) | [GitHub] |
| Sapling AI Detector | Free browser-based detector (up to 2,000 chars). 97% accuracy in some studies. | Website |
| QuillBot AI Detector | Free, no sign-up required. | Website |
| Writer AI Content Detector | Free tool with color-coded results. | Website |
| ZeroGPT | Popular free detector evaluated in multiple academic studies. | Website |
Watermarking Approaches
| Name | Description | Link |
|---|---|---|
| SynthID (Google DeepMind) | Watermarking for AI text, images, and audio via statistical token sampling. Deployed in Google products. | Website |
| OpenAI Text Watermarking | Developed but still experimental as of 2025. Research shows fragility concerns. | Experimental |
Important caveat: No detector claims 100% accuracy. Mixed human/AI text remains hardest to detect (50–70% accuracy). Adversarial robustness varies widely. The AI detection market is projected to grow from ~$2.3B (2025) to $15B by 2035.
Books
📖
Prompt Engineering
| Title | Author(s) | Publisher | Year |
|---|---|---|---|
| Prompt Engineering for LLMs | John Berryman & Albert Ziegler | O'Reilly | 2024 |
| Prompt Engineering for Generative AI | James Phoenix & Mike Taylor | O'Reilly | 2024 |
| Prompt Engineering for LLMs | Thomas R. Caldwell | Independent | 2025 |
LLM Application Development
| Title | Author(s) | Publisher | Year |
|---|---|---|---|
| AI Engineering: Building Applications with Foundation Models | Chip Huyen | O'Reilly | 2025 |
| Build a Large Language Model (From Scratch) | Sebastian Raschka | Manning | 2024 |
| Building LLMs for Production | Louis-François Bouchard & Louie Peters | O'Reilly | 2024 |
| LLM Engineer's Handbook | Paul Iusztin & Maxime Labonne | Packt | 2024 |
| The Hundred-Page Language Models Book | Andriy Burkov | Self-Published | 2025 |
AI Agents
| Title | Author(s) | Publisher | Year |
|---|---|---|---|
| Building Applications with AI Agents | Michael Albada | O'Reilly | 2025 |
| AI Agents and Applications | Roberto Infante | Manning | 2025 |
| AI Agents in Action | Micheal Lanham | Manning | 2025 |
Production, Reliability, and Security
| Title | Author(s) | Publisher | Year |
|---|---|---|---|
| LLMs in Production | Christopher Brousseau & Matthew Sharp | Manning | 2025 |
| Building Reliable AI Systems | Rush Shahani | Manning | 2025 |
| The Developer's Playbook for LLM Security | Steve Wilson | O'Reilly | 2024 |
Courses
👩🏫
Free Short Courses
- ChatGPT Prompt Engineering for Developers — Co-taught by Andrew Ng and OpenAI's Isa Fulford. The foundational starting point. (DeepLearning.AI)
- Building Systems with the ChatGPT API — Multi-step LLM system design for production. (DeepLearning.AI)
- AI Agents in LangGraph — Agentic dataflows with tool use and research agents. (DeepLearning.AI)
- Building Agentic RAG with LlamaIndex — RAG research agent construction. (DeepLearning.AI)
- Functions, Tools and Agents with LangChain — Function calling and agent building. (DeepLearning.AI)
- Prompt Engineering for Vision Models — Visual prompting techniques. (DeepLearning.AI)
University and Platform Courses
- Prompt Engineering Specialization (Vanderbilt) — 3-course series by Dr. Jules White covering foundational to advanced PE. (Coursera)
- Generative AI with LLMs (DeepLearning.AI + AWS) — LLM lifecycle, transformers, RLHF, deployment. (Coursera)
- Stanford CS336: Language Modeling from Scratch — Build an LLM end-to-end. (Stanford, 2024–2026)
- MIT 6.S191: Introduction to Deep Learning — Annual course including LLMs and generative AI. (MIT, 2024–2026)
- The Complete Prompt Engineering for AI Bootcamp — Covers GPT-5, DSPy, LangGraph, agent architectures. 58K+ ratings. (Udemy, updated Feb 2026)
Free Platform Courses
- Google Prompting Essentials — 5-step prompt design, meta-prompting, Gemini. Under 6 hours.
- Microsoft Azure AI Fundamentals: Generative AI — Free learning path covering LLMs, prompts, agents, Azure OpenAI.
- Hugging Face LLM Course — Community-driven course covering transformers, fine-tuning, building reasoning models.
- Hugging Face AI Agents Course — Agent theory to practice. 100K+ registered students.
Learn Prompting Courses
- ChatGPT for Everyone
- Introduction to Prompt Engineering
- Advanced Prompt Engineering
- Introduction to Prompt Hacking
- Advanced Prompt Hacking
- Introduction to Generative AI Agents for Business Professionals
- AI Safety
Tutorials and Guides
📚
Official Provider Guides
- OpenAI Prompt Engineering Guide — Comprehensive, covering GPT-4.1/5 prompting, reasoning models, structured outputs, agentic workflows. Continuously updated.
- OpenAI GPT-4.1 Prompting Guide [2025] — Structured agent-like prompt design: goal persistence, tool integration, long-context processing.
- Anthropic Prompt Engineering Overview — Iterative prompt design, XML tags, chain-of-thought, role assignment. Includes prompt generator.
- Anthropic Claude 4 Best Practices [2025–2026] — Parallel tool execution, thinking capabilities, image processing.
- Anthropic: Effective Context Engineering for AI Agents [2025] — The evolution from prompt engineering to context engineering: agent state, memory, tools, MCP.
- Google Gemini Prompting Strategies — Multimodal prompting for Gemini via Vertex AI and AI Studio.
- Microsoft Prompt Engineering in Azure AI Studio — Tool calling, function design, few-shot prompting, prompt chaining.
Community and Independent Guides
- Prompt Engineering Guide (DAIR.AI / promptingguide.ai) — Most comprehensive open-source guide. 18+ techniques, model-specific guides, research papers. 3M+ learners. Now includes context engineering.
- Learn Prompting (learnprompting.org) — Structured free platform. Beginner to advanced PE, AI security, HackAPrompt competition.
- IBM 2026 Guide to Prompt Engineering [2026] — Curated tools, tutorials, real-world examples with Python code.
- Anthropic Interactive Tutorial — 9-chapter Jupyter notebook course with hands-on exercises.
- Lilian Weng's Prompt Engineering Guide [2023] — Highly respected technical blog from OpenAI researcher.
- Google Prompt Engineering Guide (68-page PDF) [2025] — Internal-style best-practice guide for Gemini with concrete patterns.
- DigitalOcean: Prompt Engineering Best Practices [2025] — Updated guide summarizing techniques: few-shot, chain-of-thought, role prompting, etc.
- Aakash Gupta: Prompt Engineering in 2025 [2025] — Practical guide with wisdom from shipping AI at OpenAI, Shopify, and Google.
- Best practices for prompt engineering with OpenAI API — OpenAI's introductory best practices.
- OpenAI Cookbook — Official recipes for function calling, RAG, evaluation, and complex workflows.
- Microsoft Prompt Engineering Docs — Microsoft's open prompt engineering resources.
- DALLE Prompt Book — Visual guide for text-to-image prompting.
- Best 100+ Stable Diffusion Prompts — Community-curated image generation prompts.
- Vibe Engineering (Manning) — Book by Tomasz Lelek & Artur Skowronski on building software through natural language prompts.
Videos
🎥
- Andrej Karpathy: "Deep Dive into LLMs" & "How I Use LLMs" [2024–2025] — Two of the most influential AI videos of 2024–2025. Comprehensive technical deep dive followed by practical usage patterns.
- Karpathy: "Software in the Era of AI" (YC AI Startup School) [2025] — Coined "vibe coding" (Feb 2025) and championed "context engineering" (Jun 2025).
- Karpathy: Neural Networks: Zero to Hero [2023–2024] — Full lecture series building from backpropagation to GPT.
- 3Blue1Brown: Neural Networks Series [Updated 2024] — Iconic animated visual explanations of transformers and attention mechanisms. 7M+ subscribers.
- AI Explained [2024–2025] — Long-form analysis breaking down papers, model capabilities, and PE developments.
- Sam Witteveen [2024–2025] — Practical tutorials on prompt engineering, LangChain, RAG, and agents.
- Matthew Berman [2024–2025] — Popular channel covering model releases and practical LLM usage. 600K+ subscribers.
- DeepLearning.AI YouTube [2024–2026] — Structured lessons, course previews, and Andrew Ng talks on agents and AI careers.
- Lex Fridman Podcast (AI Episodes) [2024–2025] — Long-form interviews with Altman, Hinton, Amodei on LLMs, prompting, and safety.
- ICSE 2025: AIware Prompt Engineering Tutorial [2025] — Conference tutorial covering prompt patterns, fragility, anti-patterns, and optimization DSLs.
- CMU Advanced NLP 2022: Prompting — Foundational academic lecture on prompting methods.
- ChatGPT: 5 Prompt Engineering Secrets For Beginners — Accessible intro for beginners.
Communities
🤝
Discord Servers
- Learn Prompting — 40,000+ members. Largest PE Discord with courses, hackathons, HackAPrompt competitions.
- PromptsLab Discord - Community
- Midjourney — 1M+ members. Primary hub for text-to-image prompt sharing.
- OpenAI Discord — Official community with channels for GPTs, Sora, DALL-E, and API help.
- Anthropic Discord — Official Claude community for AI development collaboration.
- Hugging Face Discord — Model discussions, library support, community events.
- FlowGPT — 33K+ members. 100K+ prompts across ChatGPT, DALL-E, Stable Diffusion, Claude.
- r/PromptEngineering — Dedicated subreddit for prompt crafting techniques and discussions.
- r/ChatGPT — 10M+ members. Primary hub for ChatGPT users and prompt sharing.
- r/LocalLLaMA — Highly technical community for running open-source LLMs locally.
- r/ClaudeAI — Anthropic's Claude community: prompt sharing, API tips, model comparisons.
- r/MachineLearning — Academic-oriented ML research discussions.
- r/OpenAI — OpenAI product and API discussions.
- r/StableDiffusion — 450K+ members for AI art prompting and workflows.
- r/ChatGPTPromptGenius — 35K+ members sharing and refining prompts.
Forums and Platforms
- OpenAI Developer Community — Official forum for API help, best practices, project sharing.
- Hugging Face Community — Hub for open-source AI collaboration.
- DeepLearning.AI Community — Forum for learners discussing courses and AI careers.
- LessWrong — In-depth technical posts on AI capabilities and safety.
- AI Alignment Forum — Specialized alignment research discussions.
- CivitAI — Generative AI creators platform for sharing models, LoRAs, and prompts.
GitHub Organizations
- LangChain — Open-source LLM app framework. 100K+ stars.
- Promptslab — Generative Models | Prompt-Engineering | LLMs
- Hugging Face — Central hub: Transformers, Diffusers, Datasets, TRL.
- DSPy (Stanford NLP) — Growing community for systematic prompt optimization.
- OpenAI — Open-source models, benchmarks, and tools.
🔬 Autonomous Research & Self-Improving Agents
Auto-synced from awesome-autoresearch · Last synced: 2026-06-30
General-Purpose Descendants
- kayba-ai/recursive-improve — Recursive self-improvement framework where agents capture execution traces, analyze failure patterns, and apply targeted fixes with keep-or-revert evaluation.
- vukrosic/auto-research — Docs-only control plane for an open autonomous AI research lab — file-based operating model for human direction and agent execution.
- uditgoenka/autoresearch — Claude Code skill that generalizes autoresearch into a reusable loop for software, docs, security, shipping, debugging, and other measurable goals.
- leo-lilinxiao/codex-autoresearch — Codex-native autoresearch skill with resume support, lessons across runs, optional parallel experiments, and mode-specific workflows.
- SeeleAI/Thoth — Dashboard-first Claude Code and Codex runtime for autoresearch, with durable runs, locked work items, visible ledgers, and reviewable verdicts.
- supratikpm/gemini-autoresearch — Gemini CLI skill that generalises autoresearch to any measurable goal. Gemini-native: uses Google Search grounding as a live verification source inside the loop, true headless overnight mode via --yolo --prompt, and 1M token context. Also works in Antigravity IDE via .agents/skills/.
- davebcn87/pi-autoresearch —
piextension plus dashboard for persistent experiment loops, live metrics, confidence tracking, and resumable autoresearch sessions. - drivelineresearch/autoresearch-claude-code — Claude Code plugin/skill port of
pi-autoresearch, with a clean experiment-loop workflow and a concrete biomechanics case study. - greyhaven-ai/autocontext — Closed-loop control plane for repeated agent improvement, with evaluation, persistent knowledge, staged validation, and optional distillation into cheaper local runtimes.
- Necmttn/ax — Local retro loop for AI coding agents: captures session traces, turns repeated friction into proposals, and tracks accepted fixes as experiments.
- jmilinovich/goal-md — Generalizes autoresearch into a
GOAL.mdpattern for repos where the agent must first construct a measurable fitness function before it can optimize. - james-s-tayler/lazy-developer — Claude Code skill that orchestrates autoresearch across a prioritized sequence of optimization goals (coverage, test speed, build speed, complexity, LOC, performance) using GOAL.md as the engine. Supports standalone and Ralph Mode multi-instance execution.
- mutable-state-inc/autoresearch-at-home — Collaborative fork of upstream autoresearch that adds experiment claiming, shared best-config syncing, hypothesis exchange, and swarm-style coordination across many single-GPU agents.
- zkarimi22/autoresearch-anything — Generalizes autoresearch to any measurable metric — system prompts, API performance, landing pages, test suites, config tuning, SQL queries. "If you can measure it, you can optimize it."
- Entrpi/autoresearch-everywhere — Cross-platform expansion that auto-detects hardware config and starts the loop. The "glue and generalization" half of autoresearch.
- ShengranHu/ADAS — Automated Design of Agentic Systems — ICLR 2025. Meta-agents that invent novel agent architectures by programming them in code.
- MaximeRobeyns/self_improving_coding_agent — SICA: Self-Improving Coding Agent that edits its own codebase. ICLR 2025 Workshop paper demonstrating scaffold-level self-improvement on coding benchmarks.
- peterskoett/self-improving-agent — Alternative self-improving agent architecture with reflection and meta-learning cycles.
- metauto-ai/HGM — Huxley-Gödel Machine for coding agents — applies self-improvement to SWE-bench performance via meta-level optimization.
- gepa-ai/gepa — GEPA (Genetic-Pareto) — ICLR 2026 Oral. Reflective prompt evolution that outperforms RL (GRPO) on benchmarks. Optimizes any textual parameters against any metric using natural language reflection.
- sentient-agi/EvoSkill — Automated skill discovery for coding agents: evolves reusable skills and prompts from failed trajectories against benchmarks, with support for Claude Code, Codex CLI, OpenCode, OpenHands, and Goose.
- MrTsepa/autoevolve — GEPA-inspired autoresearch for self-play: mutate code strategies, evaluate head-to-head, rate with Elo/Bradley-Terry, branch from the Pareto front. Agent reads match traces to target mutations. Works as a Claude Code skill.
- HKUDS/ClawTeam — Agent swarm intelligence for autoresearch — spawns parallel GPU research directions, distributes work across agents, aggregates results.
- Orchestra-Research/AI-Research-SKILLs — Comprehensive skill library including autoresearch orchestration with two-loop architecture (inner optimization + outer synthesis).
- WecoAI/aideml — AIDE: Tree-search ML engineering agent that autonomously improves model performance via iterative code generation and evaluation.
- weco.ai — Weco: Cloud platform for AIDE with observability, experiment tracking, and managed runs — brings the autoresearch loop into production.
Research-Agent Systems
- aiming-lab/AutoResearchClaw — End-to-end research pipeline that turns a topic into literature review, experiments, analysis, peer review, and paper drafts; broader than autoresearch, but clearly in the same lineage.
- OpenRaiser/NanoResearch — End-to-end autonomous research engine that plans experiments, generates code, runs jobs locally or on SLURM, analyzes real results, and writes papers grounded in those outputs.
- kaust-ark/ARK — ARK (Automatic Research Kit): idea + venue → paper pipeline orchestrating 6 agents — proposal analysis, literature search, Slurm experiments, LaTeX drafting, iterative peer review. Controlled via CLI, web dashboard, or Telegram.
- wanshuiyin/Auto-claude-code-research-in-sleep — Markdown-first research workflows for Claude Code and other agents, centered on autonomous literature review, experiments, paper iteration, and cross-model critique.
- skyllwt/AutoSci — Wiki-centric full-lifecycle research platform built on Claude Code, realizing Karpathy's LLM-Wiki vision. 20+ skills cover the full loop: ingest → ideate → novelty check → experiment design / run / eval → paper writing. Research state lives in a structured knowledge wiki with an interactive graph.
- Sibyl-Research-Team/AutoResearch-SibylSystem — Fully autonomous AI scientist built on Claude Code, with explicit AutoResearch lineage, multi-agent research iteration, GPU experiment execution, and a self-evolving outer loop.
- eimenhmdt/autoresearcher — Early open-source package for automating scientific workflows, currently centered on literature-review generation with an ambition toward broader autonomous research.
- hyperspaceai/agi — Distributed, peer-to-peer research network where autonomous agents run experiments, gossip findings, maintain CRDT leaderboards, and archive results to GitHub across multiple research domains.
- Human-Agent-Society/CORAL — CORAL: Autonomous multi-agent evolution for open-ended discovery (arXiv:2604.01658). Long-running agents with shared persistent memory, asynchronous execution, and heartbeat-based interventions; SOTA on 10 math/algorithmic/systems tasks.
- SakanaAI/AI-Scientist — The AI Scientist: First comprehensive system for fully automatic scientific discovery. From idea generation to paper writing with minimal human supervision.
- SakanaAI/AI-Scientist-v2 — Workshop-level automated scientific discovery via agentic tree search. Removes template dependency from v1, generalizes across research domains.
- AweAI-Team/AiScientist — AiScientist: long-horizon ML research lab with hierarchical orchestration and File-as-Bus coordination — workspace files act as the durable system of record. Drives autonomous paper-reproduction (PaperBench) and competition-style MLE-Bench iteration loops under fixed compute/time budgets. (arXiv 2604.13018)
- HKUDS/AI-Researcher — NeurIPS 2025 paper. Full end-to-end research automation: hypothesis → experiments → manuscript → peer review. Production version at novix.science.
- openags/Auto-Research — OpenAGS: Orchestrates a team of AI agents across the full research lifecycle — lit review, hypothesis generation, experiments, manuscript writing, and peer review.
- SamuelSchmidgall/AgentLaboratory — End-to-end autonomous research workflow: idea → literature review → experiments → report. Supports both autonomous and co-pilot modes.
- AgentRxiv — Collaborative autonomous research framework where agent laboratories share a preprint server to build on each other's work iteratively.
- JinheonBaek/ResearchAgent — Iterative research idea generation over scientific literature with LLMs. Multi-agent review and feedback loops.
- du-nlp-lab/MLR-Copilot — Autonomous ML research framework — generates ideas, implements experiments, analyzes results.
- MASWorks/ML-Agent — Reinforcing LLM agents for autonomous ML engineering. Learns from trial and error to improve model performance.
- PouriaRouzrokh/LatteReview — Low-code Python package for automated systematic literature reviews via AI-powered agents.
- LitLLM/LitLLM — AI-powered literature review assistant using RAG for accurate, well-structured related-work sections in academic writing.
- Agent Laboratory — Three-phase research pipeline: Literature Review → Experimentation → Report Writing, with specialized agents for each phase.
Platform Ports & Hardware Forks
- gianfrancopiana/openclaw-autoresearch — OpenClaw port of pi-autoresearch; autonomous experiment loop for any optimization target with statistical confidence scoring.
- miolini/autoresearch-macos — Widely adopted macOS fork that adapts upstream autoresearch for Apple Silicon / MPS while preserving the original loop shape.
- trevin-creator/autoresearch-mlx — MLX-native Apple Silicon port that keeps the upstream fixed-budget
val_bpbloop while removing the PyTorch/CUDA dependency entirely. - jsegov/autoresearch-win-rtx — Windows-native RTX fork focused on consumer NVIDIA GPUs, with explicit VRAM floors and a practical desktop setup path.
- iii-hq/n-autoresearch — Multi-GPU autoresearch infrastructure with structured experiment tracking, adaptive search strategy, crash recovery, and queryable orchestration around the classic
train.pyloop. - lucasgelfond/autoresearch-webgpu — Browser/WebGPU port that lets agents generate training code, run experiments in-browser, and feed results back into the loop without a Python setup.
- tonitangpotato/autoresearch-engram — Fork with persistent cognitive memory — frequency-weighted retrieval of cross-session knowledge for improved experiment continuity.
- Colab/Kaggle T4 port — Adapts autoresearch for free T4 GPUs (Google Colab / Kaggle) with zero cost and zero local setup. Key changes: Flash Attention 3 → PyTorch SDPA, removes H100-only kernel dependency.
- ArmanJR-Lab/autoautoresearch — Jetson AGX Orin port with a director — a Go binary that acts as a "creative director" injecting novelty (arxiv papers + DeepSeek Reasoner) into the loop to escape local minima. Includes multi-experiment comparison (baseline vs director-guided) with detailed stall analysis.
Domain-Specific Adaptations
- mattprusak/autoresearch-genealogy — Applies the autoresearch pattern to genealogy, using structured prompts, archive guides, source checks, and vault workflows to iteratively expand and verify family-history research.
- ArchishmanSengupta/autovoiceevals — Uses adversarial callers plus keep-or-revert prompt edits to harden voice AI agents across Vapi, Smallest AI, and ElevenLabs.
- chrisworsey55/atlas-gic — Applies the autoresearch keep-or-revert loop to trading agents, optimizing prompts and portfolio orchestration against rolling Sharpe ratio instead of model loss.
- RightNow-AI/autokernel — Applies the autoresearch loop to GPU kernel optimization: profile bottlenecks, edit one kernel, benchmark, keep or revert, repeat.
- ElliotXie/autozyme — Multi-agent framework that applies the autoresearch keep-or-revert loop to CPU-side scientific software: profile a target function, generate one optimization candidate, benchmark for speed while preserving the original outputs, keep or revert, repeat.
- Agent-Analytics/autoresearch-growth — Applies autoresearch to landing-page positioning and A/B test candidates, using analytics snapshots and measured experiment results to seed subsequent rounds.
- Rkcr7/autoresearch-sudoku — Enhanced autoresearch workflow where an AI agent iteratively rewrites and benchmarks a Rust sudoku solver, ultimately beating leading human-built solvers on hard benchmark sets.
- jeongph/autospec — Reads natural-language business rules and autonomously builds a Spring Boot service with tests via the keep-or-revert loop. Evaluates with Gradle build + JUnit XML. 119-line skeleton to 950 lines in 5 cycles.
- vlasenkoalexey/tpu_performance_autoresearch_wiki — Applies the autoresearch keep-or-revert loop to TPU model performance (MFU / tokens-per-sec) on v6e hardware: profiles each run through an XProf MCP server, makes one model-code change per experiment, and keeps or reverts against measured MFU. Pairs the loop with a Karpathy-style LLM wiki for domain knowledge and per-experiment optimization traces; includes Llama3-8B and Qwen3-8B case studies across JAX and torchax lanes.
Evaluation & Benchmarks
- snap-stanford/MLAgentBench — Benchmark suite for evaluating AI agents on ML experimentation tasks. 13 tasks from CIFAR-10 to BabyLM.
- OpenAI/mle-bench — OpenAI's benchmark for measuring how well AI agents perform at ML engineering.
- chchenhui/mlrbench — MLR-Bench: Evaluating AI agents on open-ended ML research. 201 tasks from NeurIPS/ICLR/ICML workshops.
- gersteinlab/ML-Bench — Evaluates LLMs and agents for ML tasks on repository-level code.
- THUDM/AgentBench — Comprehensive benchmark for LLM-as-Agent evaluation across 8 distinct environments. ICLR 2024.
Related Resources
- ai-agents-2030/awesome-deep-research-agent — Curated list of deep research agent papers and systems.
- YoungDubbyDu/LLM-Agent-Optimization — Papers on LLM agent optimization methods.
- VoltAgent/awesome-ai-agent-papers — Curated AI agent papers from 2026 — agent engineering, memory, evaluation, workflows, and autonomous systems.
- masamasa59/ai-agent-papers — AI agent research papers updated biweekly via automated arxiv search with curated selection.
- tmgthb/Autonomous-Agents — Autonomous agents research papers, updated daily.
- HKUST-KnowComp/Awesome-LLM-Scientific-Discovery — EMNLP 2025 survey on LLMs in scientific discovery.
- openags/Awesome-AI-Scientist-Papers — Collection of AI Scientist / Robot Scientist papers.
- agenticscience.github.io — Survey: "From AI for Science to Agentic Science: A Survey on Autonomous Scientific Discovery."
- dspy.ai/GEPA — DSPy integration of GEPA reflective prompt optimizer for compound AI systems.
- OpenAI Cookbook: Self-Evolving Agents — Cookbook for autonomous agent retraining using GEPA-style reflective evolution.
- WecoAI/awesome-autoresearch — Curated list of AutoResearch use cases with verifiable traces and progress charts, organized by domain (LLM training, GPU kernels, voice agents, trading, etc.).
How to Contribute
We welcome contributions to this list! Before contributing, please take a moment to review our contribution guidelines. These guidelines will help ensure that your contributions align with our objectives and meet our standards for quality and relevance.
What we're looking for:
- New high-quality papers, tools, or resources with a brief description of why they matter
- Updates to existing entries (broken links, outdated information)
- Corrections to star counts, pricing, or model details
- Translations and accessibility improvements
Quality standards:
- All tools should be actively maintained (updated within the last 6 months)
- Papers should be from peer-reviewed venues or have significant community adoption
- Datasets should be publicly accessible
- Please include a one-line description explaining why the resource is valuable
Thank you for your interest in contributing to this project!
Maintained by PromptsLab · Star this repo if you find it useful!